

November 9, 2016
Trump Victory: How Did the National Polls Get It So Wrong?

(gral/Shutterstock)
As Donald Trump celebrates his stunning victory in last night’s presidential election, professional pollsters are waking up and asking themselves: How did we get it so wrong?
Nearly all the national polls showed Hillary Clinton winning the presidency in the weeks before the election. Going into yesterday’s election, Clinton’s odds of winning were generally placed around 85%, while Trump’s odds were about 15%.
Two days before the election, Monmouth University Poll reported that Clinton led Trump by 6 points in a national poll of likely voters. Public Policy Polling reported last week that Clinton led Trump by 5 points in Michigan, which Trump actually won by 1 point. RealClearPolitics’ average of multiple polls showed Clinton with a 3.3% lead.
In his final election update, FiveThirtyEight founder Nate Silver, perhaps the most widely respected political statistician in the business, reported that his ensemble modeling techniques showed Clinton had a 72% chance of winning. “There were a wide range of outcomes,” Silver wrote yesterday about the model runs, “and most of them came up Clinton.”
Few people questioned whether the polls were accurately reflecting the political reality. People scoffed when Trump denounced the accuracy of what he called “biased” national polls, saying they were the proof that media elite was working to control information and rig the system against him. Eyes rolled when Trump claimed a large pool of angry voters existed and that he would ride this sentiment to victory on Election Day.
(newelle/Shutterstock)
Amazingly, Trump was right, and nearly every pollster got it wrong. There was a large pool of angry voters, they did show up in large enough numbers to create the biggest upset in the recent history of presidential elections, and there was a bias in the polls.
How did that happen?
Not surprisingly, it comes down to the details–the mechanics of how polls are conducted and the statistical techniques that professional pollsters use to separate the signal from the noise within their particular samples.
The source of the bias in most of the polls, it appears, comes down to inccorectly estimating who was actually going to show up to vote.
Exit polls conducted outisde voting stations yesterday showed an unexpected large turnout of white voters without a college degree in Rust Belt swing states like Pennsylvania, Ohio, Michigan, and Wisconsin. It would appear that pollsters didn’t account for this particular demographic—which swung heavily for Trump by a 30% margin—in the weightings they applied to the samples they used in their polls.
“Did no one poll the farmers?” Tweeted veteran journalist Elizabeth Drew, a regular contributor to the New York Review of Books.
But there was one poll that did correctly forecast Trump’s victory. The USC Dornsife/Los Angeles Times “Daybreak” poll, which tracked about 3,000 eligible voters until election day, showed Trump with a sizable lead throughout the fall.
Did no one poll the farmers?
— Elizabeth Drew (@ElizabethDrewOH) November 9, 2016
David Lauter, the LA Times’ Washington bureau chief, explains that one of the big differences between the Daybreak poll and other polls is how it was weighted. “The Daybreak poll uses a weighting plan that is more complicated than most other surveys — perhaps too complex, critics said,” Lauter writes.
Specifically, the poll estimated a higher turnout of white voters compared to 2012. That is exactly what happened, and it’s something that other respected polls did not correctly estimate in their weightings.
The Daybreak poll surfaced another piece of data that may explain why other polls got it wrong. The poll asked the survey respondents how they feel about talking about the candidate they support. The poll showed that, while, Trump supporters are more comfortable than Clinton about talking about the candidate they’re going to vote for, they’re less comfortable talking about their candidate to pollsters over the telephone than Clinton supporters.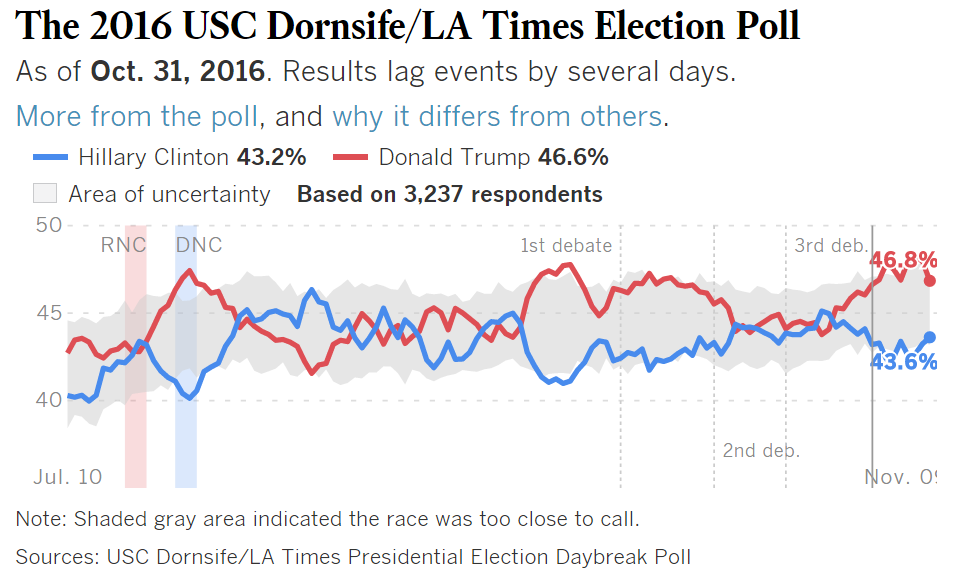
The poll asked respondents whether they were comfortable talking to people about their vote. The survey found that Trump supporters reported themselves as being slightly more comfortable than Clinton voters in talking to family members and acquaintances about their choice.
These are biases that could have, and should have, been identified. “Some of the worst failures of polling have come about because pollsters,” Lauter writes, “whether deliberately or not, converged on a single view of an election, in what is often referred to as ‘herding.'”
Mona Chalabi, the data editor at The Guardian, has been vocally critical about the reliability of polls and the accuracy of predictions that they generate. In a blog post today, she explains how mainstream polls often get it wrong.
Chalabi says only 10% of people who are called on the phone by polling companies actually take part in the poll. “Have you ever taken part in a poll about politics? I didn’t think so,” the disillusioned former FiveThirtyEight editor says. “Most polls only speak to a small handful of people. And that’s just one reason why they can’t be trusted.”
Chalabi explained that much of the error can be attributed to the weighting factors that professional pollsters use to create what they think is a balanced view of “likely voters.”

(joseph-sohm/Shutterstock)
“Let’s say only 5% of your respondents are black. But 10% of the entire population are black. So what you do is you just double the results you got from the black respondents, which sounds sensible.” Chalabi says. “But when your whole survey sample is just 1,000 people, that means that all of a sudden 50 individuals are supposed to represent 42 million black people in America.”
And that, in turn, is where nearly every poll got it wrong. They significantly underestimated the turnout of a particular demographic—the disillusioned white voters, especially men, without college degrees—and they paid the price for it.
That polls are subject to error isn’t news, of course. Pollsters have been attempting to “correct” their polls for as long as they’ve been doing them. Just as data scientists will “tweak” their model to generate what they hope are better and more accurate predictions, the pollster will juggle different weightings until they have something that they think accurately reflects the populace.
For anybody who’s involved in statistical analysis–which is what anybody who’s using big data to make predictions about the world–it’s a worthy lesson to understand how the mistakes were made, so they can avoid making them in the future.
Related Items:
8 Interactive Visualizations for Election Day
From Blackjack to Big Data – The Importance of Avoiding Cognitive Bias
Technologies:
Middleware
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
Call & Contact Center Expo
 April 24 - April 25Las Vegas NV United States
April 24 - April 25Las Vegas NV United States -
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States