

October 20, 2016
Why America’s Spy Agencies Are Investing In MapD

(GlebStock/Shutterstock)
In-Q-Tel, the venture arm of American spy agencies, announced yesterday that it has invested in MapD. Why are the nation’s spooks interested in MapD Technologies, which develops a parallel SQL database that runs on GPUs? The answer may surprise you.
Nobody really knows what the CIA and assorted other intelligence agencies are doing in the world of big data analytics. We know they’re doing something, of course. The spy agencies are likely facing a lot of the same data analysis challenges and opportunities that private companies deal with every day–too much data and too little time to make sense of it. Occasionally we get a peek behind the curtain, but for the most part the details are kept secret.
However, one can glean a slight semblance of the technical direction of America’s spy agencies by looking at the roster of private firms that In-Q-Tel invests in.
Founded in 1999 by a former Lockheed Martin CEO and a video game designer, the privately held non-profit organization has invested federal funds into a variety of startups in the field of predictive analytics, geospatial analytics, speech and handwriting recognition, and search engines. Datanami readers will recognize companies like Cloudera, Continuum Analytics, Databricks, Lucidworks, MemSQL, MongoDB, Narrative Science, Palantir, Paxata, Skytree, and Zoomdata, all of which received In-Q-Tel funding.
You can now count MapD among those. The company develops a parallelized, column-oriented SQL database designed specifically to run on GPUs. Atop this database sits a visual analytics layer that allows users to interact with the data.
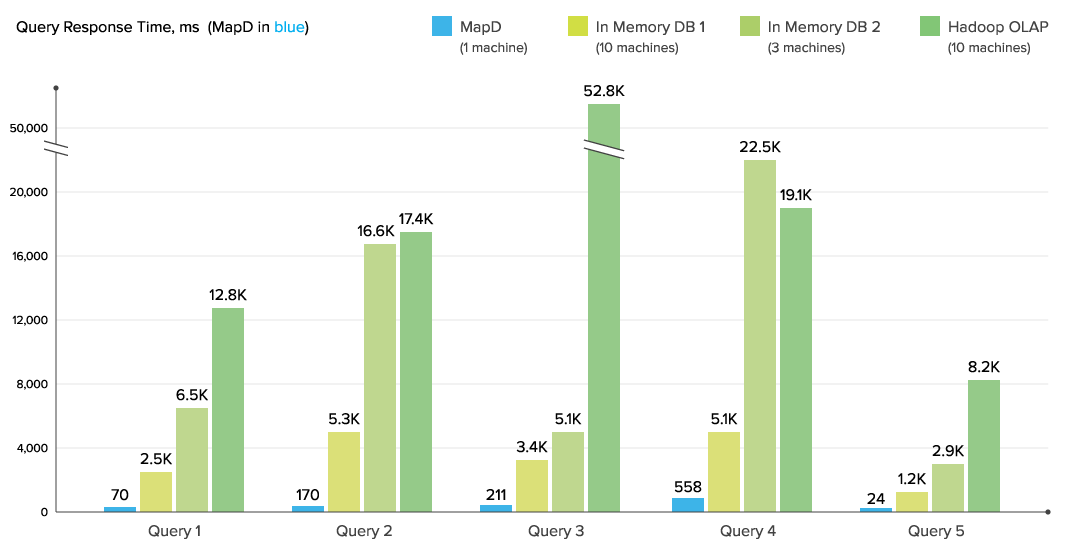
MapD says its GPU-powered SQL database runs orders of magnitude faster than CPU-based databases
In a recent interview with Datanami, MapD founder and CEO Todd Mostak talked about what makes his product unique. One word kept coming up over and over: Speed. Because MapD’s database runs in a GPU’s memory, it holds a tremendous speed advantage over not only the database dinosaurs that store data on disks, but also the new class of relational in-memory databases that are tied to CPUs, Mostak says.
“We do several thing to make sure we can run as fast as possible on very, very fast hardware,” he says. “The first thing is we try to cache the hot data across multiple GPUs…And of course we’re a column store. We’re compressing the data, so you can have many, many billions of rows in that GPU memory.”
And that GPU memory is very fast, he says. “People think of GPUs in term of their compute bandwidth,” he says. “But what is actually particularly important for the analyses and database operations is they have gobs of memory bandwidth—literally terabytes per second per sever, particularly with the advent of the high bandwidth memory that Nvidia has added to the latest generation of Pascal cards.”
MapD can access upwards of 5TB per second of memory bandwidth on these GPUs. “That means you can literally scan data at that rate, 5TB per second,” Mostak says. “On CPUs, if you’re lucky, you might have a little over 100GB per second. That’s a 50x difference.”
And of course the processing speed of GPUs provides a speed advantage too. “You can have almost 100 Teraflops [with an eight-GPU setup], which would certainly have qualified as a top 10 supercomputer not very long ago,” Mostak says. “Anytime you’re doing computational intensive operations, you’re going to have so much power on tap compared to CPUs.”
In a recent benchmark, the MapD database running on a single-node GPU in the cloud ran 78x faster than a traditional MPP-style analytical database running on eight CPU nodes, Mostak says. That kind of speed opens up all kinds of use cases that would have been closed off due to the latencies of existing systems, he says.
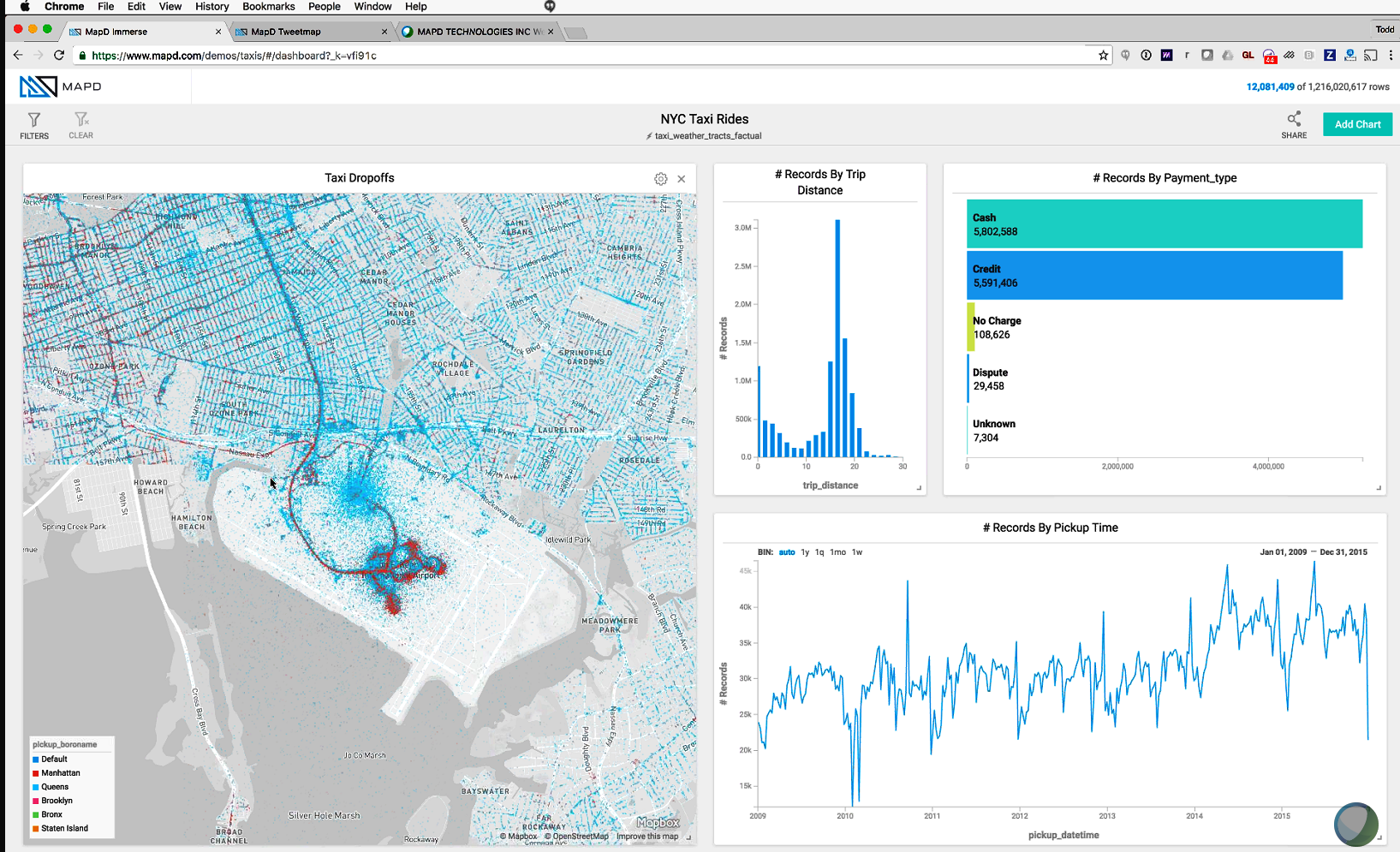
MapD’s visualization layer takes advantage of the database’s capability to execute billions of SQL queries per second to deliver record-level granularity with millisecond speed
“We’ve heard from a lot of our clients that every year their systems are getting slower,” Mostak says. “Most companies are producing a deluge of data these days. They’re just trying to keep their heads above water in terms of being able to analyze this data in real time. By bringing GPUs in to the equation, with orders of magnitude performance speed-up, we literally can bring those queries back to interactive speeds.”
MapD has been selling its product for less than a year, but it’s already attracting attention from some very big companies. That includes Verizon Wireless, which recently adopted MapD to power an application that’s used by analysts to asses SIM card updates and determine cell tower outages impacting its 85 million subscribers. The application previously ran on a well-known analytical database, but analysts were frustrated that it often took hours to get the results of SQL queries.
With MapD, Verizon analysts now enjoy sub-second response times for queries that are hitting a database with hundreds of millions of rows of data. “The database is fast, because it is using the true power of the GPUs, so the data is available almost immediately to the processors,” Abdul Subhan, principal architect at Verizon Communications, says in a Verizon case study posted to the MapD website.
Verizon Wireless, whose parent company is in the process of acquiring Hadoop-pioneer Yahoo, pitted MapD against a Hadoop-based SQL database. A single node of MapD ran over 100x faster than a 20-node Impala cluster, Verizon says.
So it’s not so surprising to see that Verizon Ventures, the venture capital arm of the $131-billion telecommunications giant, has taken a stake in MapD, along with In-Q-Tel and others. “The ability to interact with and visualize billions of data elements in real-time is a transformative capability for our national security partners,” George Hoyem, managing partner for In-Q-Tel, said in a press release.
It’s all about speed, Mostak says. “If your query takes minutes or hours to run, it’s not going to lead to a good experience for the user,” he says. “That’s a huge win there if you can deliver interactivity over the data.”
 MapD is still ramping up. The San Francisco-based company completed a $12-million round of financing earlier this year, which In-Q-Tel was a part of. The company has 30 employees, and a handful of customers (Mostak says “in the tens”) across various industries. The software is being used by oil and gas companies, banks, hedge funds, retailers, ad tech firms, and the U.S. Government, the CEO confirms.
MapD is still ramping up. The San Francisco-based company completed a $12-million round of financing earlier this year, which In-Q-Tel was a part of. The company has 30 employees, and a handful of customers (Mostak says “in the tens”) across various industries. The software is being used by oil and gas companies, banks, hedge funds, retailers, ad tech firms, and the U.S. Government, the CEO confirms.
While truly big petabyte-scale data will stay in Hadoop lakes, Mostak sees customers getting real value out of fast GPU clusters on the side that deliver sub-second response times and interactive data discovery on data sets measured in the millions of rows, or tens of terabytes. The advent of fast cloud-based GPUs, such as the Nvidia K80 instances now available on the Amazon cloud, will only accelerate the momentum behind GPU-based analytics, he says.
And it won’t be just SQL. “In the future going to increasingly push on data science side, because not only are the GPUs good for pushing fast SQL queries or for visualizing the data,” Mostak says, “but they have so much computational throughput that they’ve become the tool of choice all sorts of machine learning algorithms. Imagine being able to run Tensorflow as a UDF in MapD. I think is where we want to go.”
Related Stories:
AWS Beats Azure to K80 General Availability
GPUs Seen Lifting SQL Analytic Constraints
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
Call & Contact Center Expo
 April 24 - April 25Las Vegas NV United States
April 24 - April 25Las Vegas NV United States -
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States