

September 19, 2016
Can Hadoop Be Simple Again?

(ra2studio/Shutterstock)
In the beginning, Hadoop had two pieces: HDFS and MapReduce. Developers knew how to use them to build applications, and IT teams knew what it took to operate them. Fast forward to 2016, and developers have a cornucopia of technologies and frameworks at their disposal. But now IT teams are struggling to keep it all running.
Massive innovation in the open source community has generated an embarrassment of riches for prospective big data application developers working for individual organizations. Much of this effort has been focused on Hadoop and the surrounding Hadoop ecosystem. For just about every class of tool or business challenge, there are multiple solutions available. Need a SQL on Hadoop solution? You’ve got a dozen to pick from. It’s truly a great time to be a part of this industry.
While we all benefit from this rich flowering of technological diversity and big data achievement, there’s a downside for those who value security, governance, repeatability, and control. Sure, developers love the fact that the technology is moving so quickly. But the fact that most of these tools are being used to build one-off applications means that the operations folks (read: IT teams) must learn to run the applications in a one-off manner too. That hurts productivity and ultimately can act to hinder innovation.
Integration Challenges
One person at the forefront of minimizing the impact of the big data application integration challenge is Jonathan Gray, the founder and CEO of Cask, which is attempting to help organizations float above the underlying complexity in the Hadoop stack.
Gray uses Apache Spark to illustrate his point. While developers and data scientists love Spark because it’s so much easier and faster and all-around better than MapReduce, Spark has introduced some real barriers to productivity, at least compared to the time-tested MapReduce apps that have been running for five years already.
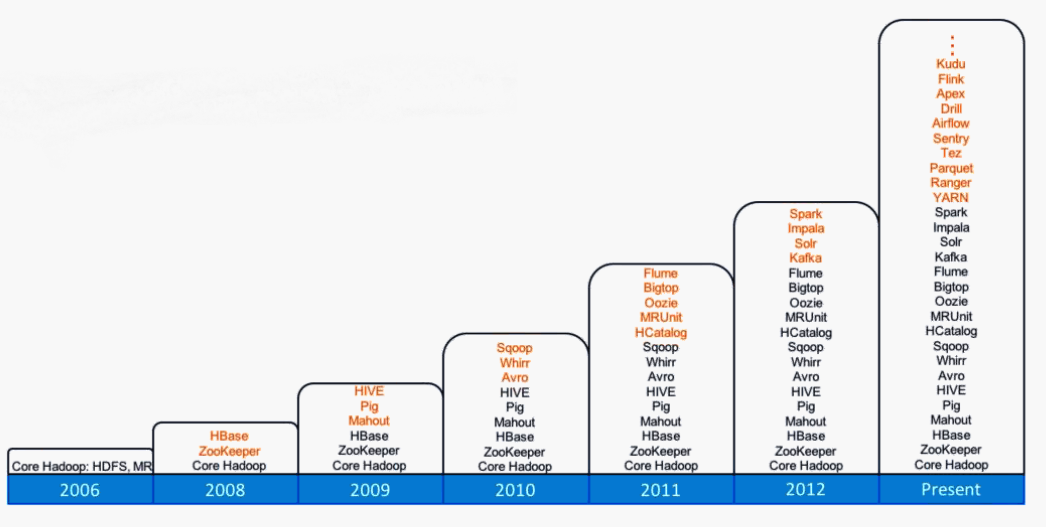
What is Hadoop? Here are some of its sub-projects
“For the developer, everything got better going from MapReduce to Spark, but operations and security got much harder,” Gray tells Datanami. “It’s great when new technology comes out and the developer uses that stuff, but operationally, that technology isn’t there. Operationally the rest of the organization basically needs to re-integrate everything with Spark that they built around MapReduce the last time.”
Just as big data apps are predominantly bespoke, so too are all those integration points. “There’s a lot of inherent complexity with the fact that ops teams, security teams, and all these people are binding directly to open source projects and specific distros, so as the versions change, they have to change, and as new technology gets adopted, they have to integrate those new technologies,” says. “They’re really exposed to the fine-level detail of each of these individual open source projects.”
Cask aims to help the big data adopters by providing a standard reference architecture that sits a level above the actual products, technologies, and frameworks. Developers can continue to use their technology of choice, such as Spark or MapReduce. But instead of using the framework-specific APIs to call and control a Spark or MapReduce job, the IT team can control it using the Cask-provided APIs.
“What we allow you to do is to layer higher-level APIs on top,” Gray, says the former Facebook engineer and HBase committer who founded Cask as Continuuity five years ago. “It allows the operations and security teams, who are not developers writing code, to integrate a platform once against these standardize APIs. The development team continues to evolve and continues to adopt new technologies, but everyone else gets the same consistent view.”
App Store
Today Cask unveiled a new version of its big data integration platform, called Cask Data Application Platform. With CDAP version 4, the company has provided more plug-ins for connecting to big data sources, including HBase, Oracle DB2, Netezza, and AWS Redshift and Kinesis. The platform also capture more data lineage information, and includes a data wrangler tool.
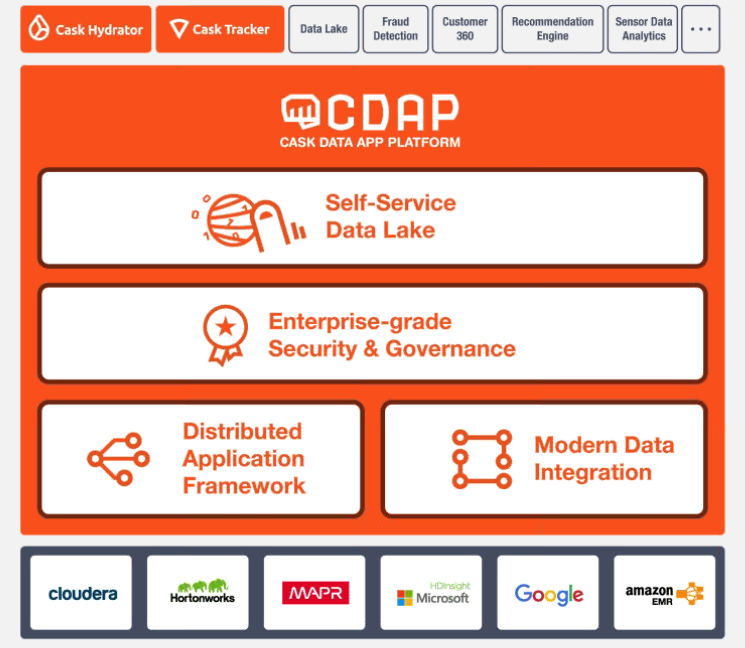
The CDAP architecture
The enhancements will help the IT department, which historically has owned the Hadoop cluster in many organizations, to provide more self-service capabilities to the user they serve, Gray says. That’s one of the shifts that’s currently occurring in the market, he says.
“Horizontal IT infrastructure and systems people who have a background in Hadoop are not the best people to deploy a marketing solution,” Gray says. “The people in the marketing department are the best people to understand what that solution needs to be. It’s not that you don’t need technical people or developers, but the nature of the people who are more horizontal- and infrastructure- and systems-oriented is a totally different role from solutions and vertical applications.”
Cask also today unveiled a big data app store, where customers, developers, and third-party software vendors can post their own CDAP-compatible applications, tools, templates, and plug-ins for use by the wider community. Cask develops its software under an open source license, and its software is free.
At some point in the future, big data apps won’t all be one-off development efforts. Users will be able to buy big data apps that just work with other big data products out of the box, and wizards will streamline any configuration that needs to be done. We’re not there yet, but Gray is doing his best to ensure that Cask plays a role in building it.
“It’s unbelievable how many different customers we talk to who say all they want to do is take Netezza data and offload it to Hadoop so they don’t have to renew their Netezza subscriptions,” Gray says. “But is there a product that you to and in 10 minutes it makes it easy to point at Netezza and load Hadoop? There’s not. You engage a Hadoop distro on that, it’s two week proof of concept.”
Future of Big Data
As the big data market matures and application and data integration becomes easier and less of a technical hurdle, we’ll see a proliferation of app stores selling shrink-wrapped apps. We’re not there yet. “We’re certainly hoping [big data app stores] is one of the next waves,” Gray says. “We’re working hard to work with as many of those companies as we can, to be that defacto platform that an ISV wants to be on…. We see this opportunity to be a standardization layer. If an ISV build on us, we can deploy to any environment.”
The SMACK stack is emerging as an alternative to Hadoop-based big data stacks
The emerging divergence among Hadoop distributions is posing a challenge for those who value integration and code mobility. Gray says many customers have expressed dismay that it commonly takes six months to convert an application originally developed for Cloudera‘s Distribution of Hadoop (CDH) to run on the Hadoop distribution from Hortonworks (NASDAQ: HDP).
“That’s our whole goal. We want to support every Hadoop distro and cloud vendor,” Gray says. “The other area we’re going to be expanding beyond cloud next year is the SMACK stack, Spark and Mesas and Cassandra. We’ll create something next year that allows portability between HBase and Cassandra and YARN and Mesos. That stuff is in development now, and we’ll launch in Q1. It will allow us to take any app and , run them in SAMCK cloud stack, or pure on-prem Hadoop. No changes at all to your code and your applications.”
We’re in the early innings still of the big data game. The big data pioneers who have been at this game for the past five years are benefiting now. For the rest of us who lack the technological chips or patience to make it all work, there’s good news: it will soon get easier, thanks to the work done by the big data pioneers, as well as vendors like Cask and others working to hammer big data tech into a workable business model.
Related Items:
Wanted: A Plug-In Architecture for Hadoop Development
Hadoop Data Virtualization from Cask Now Open Source
Applications:
Enterprise Analytics
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
Call & Contact Center Expo
 April 24 - April 25Las Vegas NV United States
April 24 - April 25Las Vegas NV United States -
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States