

September 13, 2016
Unraveling Hadoop and Spark Performance Mysteries

(Sergey Nivens/Shutterstock.com)
What do you do when your Spark or Hive job runs like molasses? If you’re like most end-users who lack in-depth technical skills, the answer is “not much.” Now a startup named Unravel Data is working to show you what’s actually going on in the cluster, and provide some configuration recommendations and automatic fixes as well.
“Big data operations is usually considered a black art,” says Kunal Agarwal, the co-founder and CEO of Unravel Data, which came out of stealth mode today three years after its founding. “People don’t usually understand what’s happening in the stack, and this impedes its performance.”
Agarwal studied parallel programming and distributed systems while enrolled in Duke University’s computer science program, and got a taste for how complex Hadoop and Spark clusters can be. When he left North Carolina to enter the big data space, he looked for ways he could make the biggest impact. His focus quickly turned to the operations side of things, which he terms “Data Ops.”
“End users are spending more than half of their day trying to solve these issues and getting productive on the big data stack,” he tells Datanami. “People don’t necessarily understand distributed computing and parallel processing, and getting performance and reliability out of these applications is super hard.”
Rouge Jobs
Like many things in life, there are multiple ways to gum up an otherwise well-running cluster. For example, a novice analyst could submit a killer join that sucks up processing capacity for hours. An organization could be keeping cold data on their primary storage, taking up valuable storage capacity. Or just one misconfigured setting in a Spark job could slow processing.

Big data clusters are complex
Intent on tackling the challenge, Agarwal and his Duke advisor (and Unravel Data co-founder and CTO) Shivnath Babu worked with a handful of companies to gain a better understanding of what’s going on under the covers. They analyzed more than 8 million Hadoop and Spark jobs from real-world applications and clusters, and found some patterns.
While the company isn’t disclosing too much about how its analyses works, rest assured that it would look familiar to most data scientists. “This is big data for big data,” Agarwal says. “As you can imagine, there’s so much information we can gather. There’s a lot of rich resources that HDFS provides us. So we’ve architected our system on the big data stacks itself.”
The company’s product, called Unravel, sits on a node in the Hadoop cluster and continuously collects usage information from HDFS and other sources. After collecting and analyzing data from Hadoop (including Hive and MapReduce) and Spark jobs, it bubbles up its findings to a centralized console via ElasticSearch.
Unravel does three main things, Agarwal says.
- Analysis of Hadoop and Spark jobs. The software can identify where the job is resource constrained, and make specific recommendations on how to address performance problems.
- Monitor jobs to achieve meet service level agreements (SLAs). The software tells the user how the application is behaving, what resources it’s using, and where processing time is spent.
- Analysis of all the data on the cluster, including how it’s used in applications, how tables are partitioned, and access patterns of data.
Taken together, these three elements should give Unravel users a very thorough picture of how applications are working with the data, the frameworks, and the hardware itself.
“We give people full visibility into what their application behavior is like, which means what kinds of data is it reading, what resources is it using, which different components of your application are being used, where is time actually spent,” Agarwal says. “Then we apply a lot of analysis on top of that to give people simple, plain-English recommendations and automatic optimization around ‘This is what’s wrong, this is why it happened, and here’s how to fix it.'”
Full-Stack Analysis
Agarwal calls it “full-stack” analysis.
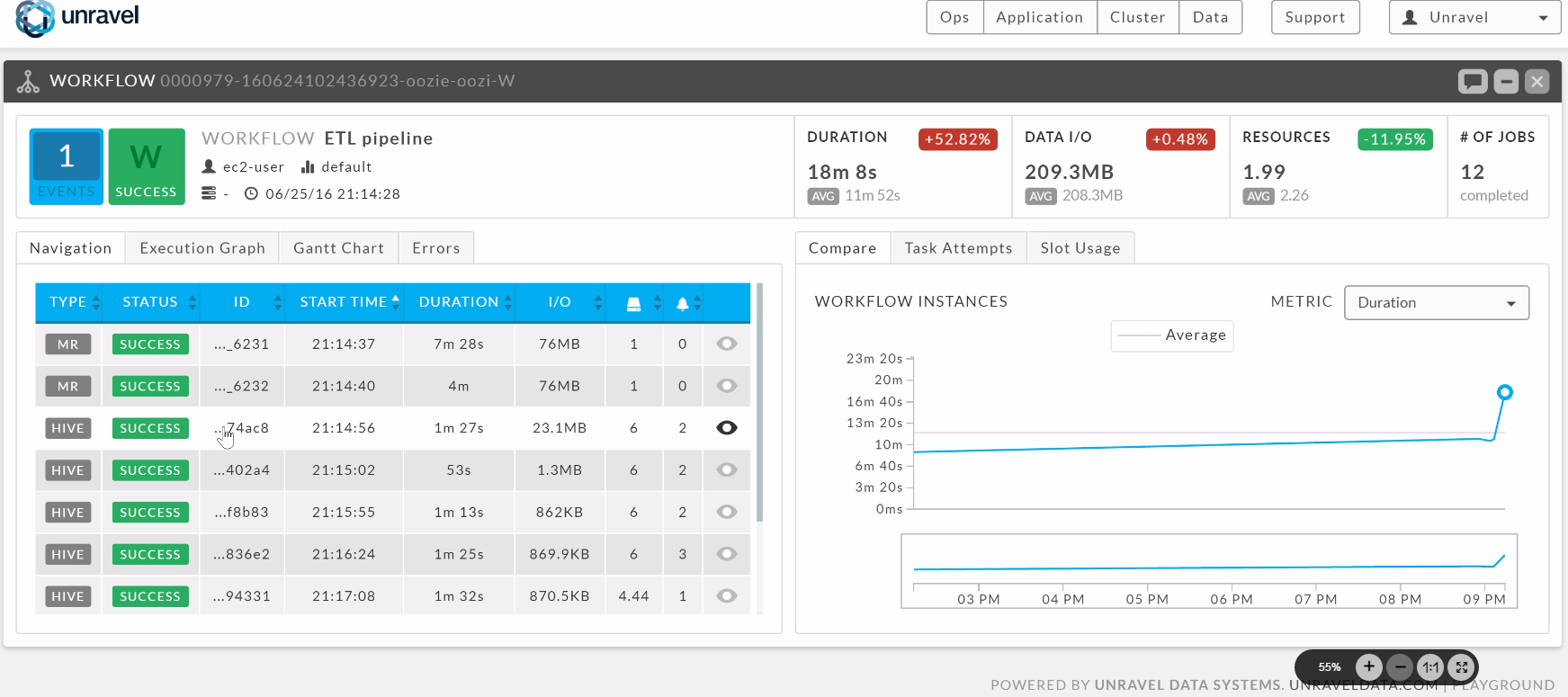
Unravel presents a unified interface for monitoring the performance of Hadoop and Spark clusters and applications.
“You have to look at the full layers of the stack from the application down to the infrastructure to really pinpoint where problems reside and what you need to do to optimize it,” he says. “You need to go beyond just monitoring and providing graphs and metrics to actually connecting dots for customers, to be able to get to automated root-cause analysis for fixing a lot of these problems.”
The software is designed to complement existing Hadoop management systems, such as Cloudera Manager and Ambari, which is backed by Hortonworks (NASDAQ: HDP). Unravel takes the output from those products, which Agarwal says are designed for systems administrators. Unravel, on the other hand, is aimed at the operations personnel who maintain clusters on a day to day basis–not to mention the users themselves, who are increasingly left to fend for themselves in today’s “self-service” environments.
Today, the product supports Hadoop, Spark, and Kafka, but the roadmaps calls for supporting other parts of the big data stack in the near future, including HBase, Cassandra, and other NoSQL databases. In many cases, these frameworks and databases are being strung together to support various big data use cases that span transactional and analytic use cases.
“When you start working with these companies you realize that one size doesn’t fit all,” Agarwal says. “That’s the vision of Unravel, to be the defacto management platform for the modern data stack.”
While Unravel Data doesn’t yet have a product generally available, it does have several thousand nodes under management via private betas, including some at companies like YellowPages and Autodesk.
 The software has been well-received by Charlie Crocker, the director of product analytic at Autodesk. “Unravel Data improves reliability and performance of our big data applications and helps us identify bottlenecks and inefficiencies in our Spark, Hadoop and Oozie workloads,” he says in a statement. “It also helps us understand how resources are being used on the cluster, and forecasts our compute requirements.”
The software has been well-received by Charlie Crocker, the director of product analytic at Autodesk. “Unravel Data improves reliability and performance of our big data applications and helps us identify bottlenecks and inefficiencies in our Spark, Hadoop and Oozie workloads,” he says in a statement. “It also helps us understand how resources are being used on the cluster, and forecasts our compute requirements.”
Unravel Data, which is now based in Menlo Park, California, has gone through two rounds of financing, including a Series A in early 2016 that provided funding for developing of the shrink wrapped product. The company expects to ship a GA product in 2017.
Related Items:
Overcoming Spark Performance Challenges in Enterprise Hadoop Environments
Happy Birthday, Hadoop: Celebrating 10 Years of Improbable Growth
Enforcing Hadoop SLAs in a Big YARN World
Applications:
Predictive Analytics
Technologies:
Frameworks
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States