
(Jurik Peter/Shutterstock)
Yahoo today announced that it’s open sourcing Pulsar, a new distributed “publish and subscribe” messaging systems designed to be highly scalable while maintaining low levels of latency. The bus already backs some of Yahoo’s key apps, and now the Web giant is seeking the help of the open source community to take Pulsar to the next level.
In a post to the Yahoo Engineering blog, Yahoo developers Joe Francis and Matteo Merli explained the application requirements that spurred the creation of the new “pub-sub” messaging system that would become Pulsar.
“These applications provide real-time services, and need publish-latencies of 5ms on average and no more than 15ms at the 99th percentile,” they write. “At Internet scale, these applications require a messaging system with ordering, strong durability, and delivery guarantees.” The messages must also be committed to multiple disks or nodes in order to get to the 99.999% guaranteed durability level, they add.
“At the time we started, we could not find any existing open-source messaging solution that could provide the scale, performance, and features Yahoo required to provide messaging as a hosted service, supporting a million topics,” Francis and Merli write. “So we set out to build Pulsar as a general messaging solution, that also addresses these specific requirements.”
Yahoo designed Pulsar to scale horizontally on commodity hardware, and to provide messaging as a service to multiple applications. The system can scale to handle millions of independent topics and millions of messages published per second, according to Pulsar’s GitHub page.
Developers and administrators interact with Pulsar through a collection of APIs. The software also includes a client library that encapsulates the messaging protocol and handles “complex” functions like service discovery and establishing and recovering connections.
Pulsar Architecture
A Pulsar cluster is composed of a set of brokers, BookKeepers (or bookies), and ZooKeeper for coordination and configuration management. A Pulsar instance typically consists of multiple physical clusters that are geographically separated from one another, Yahoo says.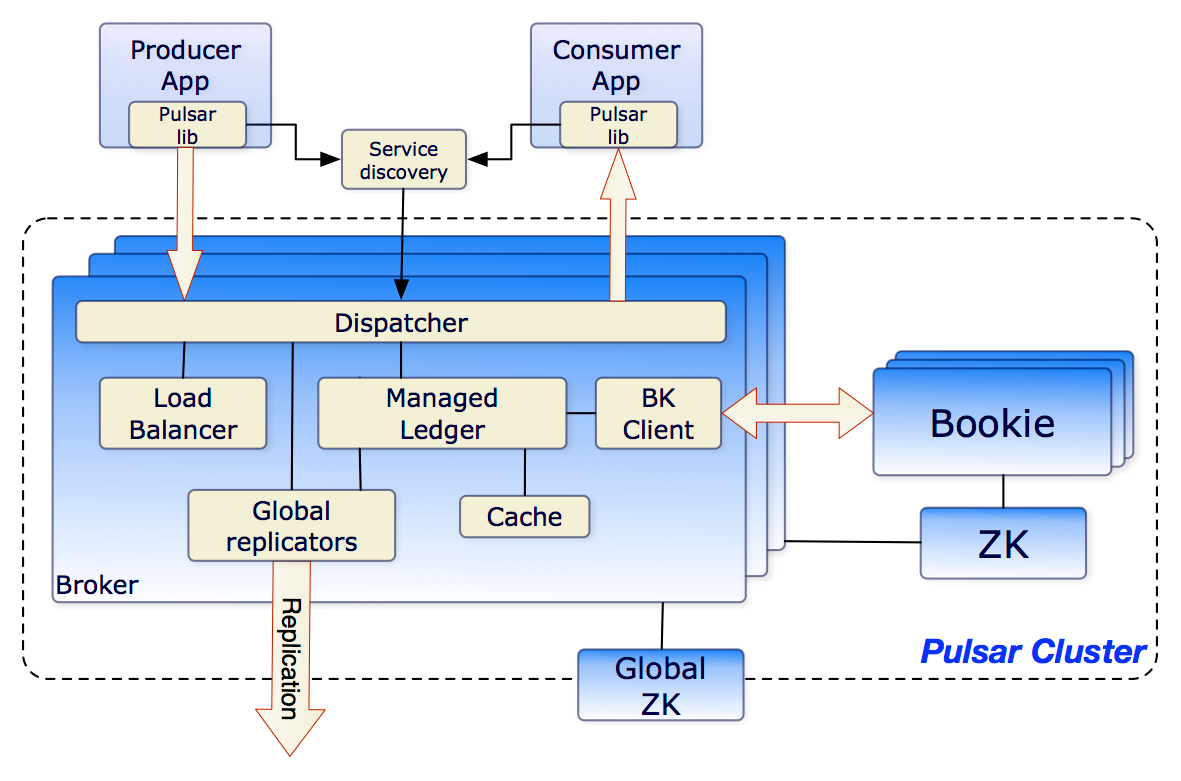
Pulsar uses Apache Bookkeeper (committed by Yahoo to open source in 2011) as its durable storage mechanism. “With Bookkeeper, applications can create many independent logs, called ledgers,” Pulsar’s project page on GitHub says. “A ledger is an append-only data structure with a single writer that is assigned to multiple storage nodes (or bookies) and whose entries are replicated to multiple of these nodes.”
Pulsar uses brokers to serve topics. Each topic is assigned to a broker, and an individual broker can serve thousands of topics, Yahoo says. “The broker accepts messages from writers, commits them to a durable store, and dispatches them to readers,” Yahoo says.
An instance of Apache Zookeeper keeps all the other pieces of Pulsar working together. Yahoo contributed ZooKeeper to the Apache Software Foundation in 2008, and since then the software has become a key component of Apache Hadoop and other big data frameworks.
It appears the use of BookKeeper is key to Pulsar’s high level of durability, and the capability to scale elements of the messaging bus independently. It also offers clues as to why Yahoo developed Pulsar in the first place, and didn’t rely on other open source messaging systems, such as Apache Kafka.
“By using separate physical disks (one for journal and another for general storage), bookies are able to isolate the effects of read operations from impacting the latency of ongoing write operations, and vice-versa,” the Yahoo developers write on their blog. “Since read and write paths are decoupled, spikes in reads – which commonly occur when readers drain backlog to catch up – do not impact publish latencies in Pulsar. This sets Pulsar apart from other commonly-used messaging systems.”
While Kafka was available when Yahoo started developing Pulsar, the technology didn’t offer some of the features that Yahoo’s engineering team required, Yahoo tells Datanami.
Specifically, features like offset (cursor) management, geo-replication, multi-tenancy, and performance under message backlog conditions were not available in Kafka then, and some even aren’t available now, a Yahoo spokesperson says.
Yahoo’s engineering team deployed its first Pulsar instance in the spring of 2015, and use of it has grown quickly since then. Today Pulsar backs Yahoo applications like Mail, Finance, Sports, Gemini Ads, and Sherpa, which is Yahoo’s distributed key-value service. All told, Pulsar publishes more than 100 billion messages per day across 1.4 million topics with an average latency of less than 5 ms.
By making Pulsar available under an Apache 2.0 license, Yahoo hopes to spur development of the messaging bus. Specific areas the company is currently looking to improve upon include decreasing the tiem it takes to migrate tpics among brokers from 10 seconds to less than one second, improving the 99.9-percentile publish latencies to 5ms, and providing additional language bindings for Pulsar.
Yahoo’s Pulsar project is not to be confused with the real-time analytics platform named Pulsar that came out eBay. You can read more about the eBay Software Foundation’s product at gopulsar.io.



















 April 24 - April 25Las Vegas NV United States
April 24 - April 25Las Vegas NV United States June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States