

June 3, 2016
Unstructured Data Miners Chase Silver with Deep Learning

(Paul-Fleet/Shutterstock)
The traditional approach to mining unstructured data typically involves training machine learning models upon high-quality “gold standard” data that’s been meticulously groomed. But thanks to innovations in deep learning, more insight may be extracted at less cost by training upon larger amounts of raw data, or what’s being called “silver standard” data.
This is the approach advocated by indico, a Boston startup that’s looking to make a mark in the burgeoning world of deep learning. The company is leveraging deep learning models running atop a combination of CPUs and GPUs to help customers in financial services and marketing to analyze large amounts of unstructured data, primarily text and images.
There’s a tremendous amount of value hidden in unstructured data, including social media posts, news stories, legal documents, and other free sources of data. But as indico CEO Slater Victoroff explains, it can be very difficult to get useful insights out of these sources, such as performing sentiment analyses.
“We found the majority of people are either not doing anything with unstructured data, or not doing nearly enough with it,” Victoroff tells Datanami. “The main barrier to sentiment analysis is not making a better model. It’s getting more data.”
Indico claims it has come up with a better way to analyze unstructured data. While much of how the platform works is secret, key breakthroughs involve the combination of silver-standard corpora training data, as well as the use of transfer learning techniques to accelerate the training of its recurrent neural network (RNN) model.![]()
The use of transfer learning is key to accelerate a machine’s capability to simulate how humans communicate, Victoroff says. For example, consider the case of an organization that wants to automatically identify a person’s political leaning by analyzing what they write. A keyword-based approach may involve searching for terms such as “wealth inequality” and various combinations of those words.
“But there are a lot of different ways of wording that actually may not use the words ‘wealth’ or ‘inequality,'” Victoroff explains. “For instance, if you have a sentence that says ‘Believes very strongly in addressing the growing gap between rich and poor,’ neither wealth nor inequality is mentioned, but it’s clearly talking about that subject.”
Machines have traditionally been very bad at spotting that fine-grained level of nuance in language, he says. Humans can do it, but humans do not scale. “But with the transfer learning [component of the indico platform], that’s something you could prototype yourself in an hour,” Victoroff says.
The use of raw, silver-standard training data, as opposed to refined gold-standard data, is another differentiator in the indico platform.
“The issue with gold standard corpora is it works only on pristine data. There’s a large emphasis on pre-processing data, making sure it’s very clean before you run anything on it,” the 23-year-old Victoroff says. “There are good reasons for that. If you’re constrained to a small data set, you really don’t have any other choice.
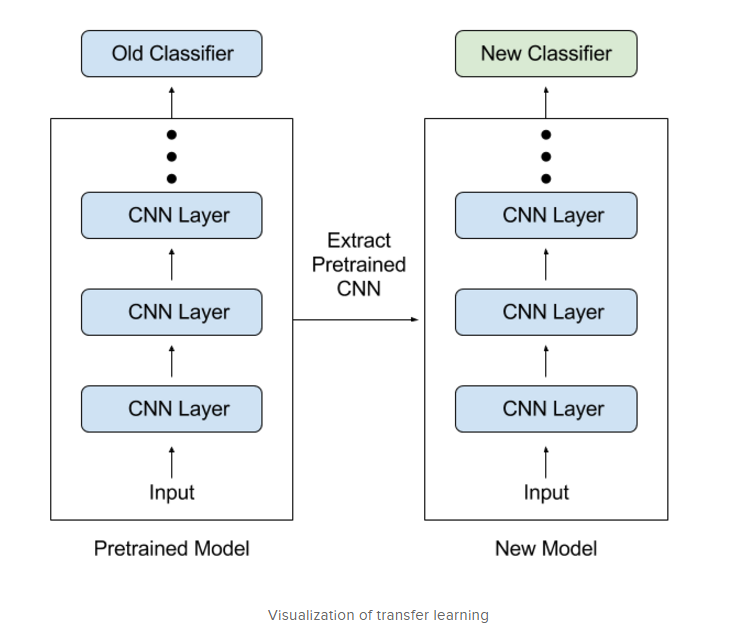
Indico uses transfer learning to accelerating the process of building machine learning models
“But one of the really nice benefits of dealing with silver-standard corpora,” he continues, “is it allows us to work with messy data. It means our models learn to work natively with messy data, instead of requiring any kind of pre-processing.”
Not only does the use of silver-standard corpora–such as the entirety of Wikipedia, all the user reviews on Amazon, or the entire IMDB movie review database—eliminate the need to pre-process huge amounts of data, but it also maintains signals that overeager algorithms or humans may mistakenly delete.
“We encourage our users not to pre-process their data,” Victoroff says. “Every time you do pre-processing, you are taking away a piece of data. If you get rid of punctuation marks, there’s information there. If you extend your words, there’s information there. If you remove the signature at the end of the email, there’s signal there, even if it’s not a very strong signal.”
Indico has a handful of customers who use the company’s RESTful APIs to enrich their real-time data feeds. For marketing professionals looking to identify key influencers, this could be as social-media “firehoses,” while for financial analysts who are seeking information to trade on, it could be stories in the Wall Street Journal or legal or financial disclosure statements.
Recently, indico attracted a new customer in the insurance business. Insurers are typically swimming in all sorts of data, including demographic data, transactions data, and risk data, says indico Chief Revenue Vishal Daga.
“The idea here is you can take those existing prediction models, but augment them with things like social media and other publicly availed data to get new signals from unstructured domain that actually improve the predictability of your overall model,” Daga says. “Those are the emerging use cases where there’s really interesting value that can be delivered.”
Regardless of the use case, indico’s cloud-based platform can accelerate analyses beyond what’s possible with traditional unstructured data mining approaches, as well as what mere humans are capable of. For example, the company recently clocked its algorithms at 93.8 percent accuracy in assessing the IMDB database. Considering that human accuracy on that type of data is about 95 percent, that level is certainly good enough.
Related Items:
‘Social Physics’ Harnesses Big Data to Predict Human Behavior
Why Twitter Is the Low-Hanging Fruit of Social Analytics
Vendors:
indico
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States