

March 10, 2016
Using Big Data Analytics to Fight Gambling Addiction

(Pavel L Photo/Shutterstock.com)
It’s estimated that 3 to 5 percent of people who gamble develop an addiction to the activity, which can lead to an array of problems for gamblers, their families, and society at large. Millions are spent annually treating people with gambling addiction, but now some gaming institutions are exploring innovative ways of identifying problem gamblers in real-time through an innovative application of machine learning.
Gambling is a big business, bringing in $500 billion in revenues around the world every year. Thanks to the rise of Internet gambling and the popularity of fantasy sports games like FanDuel and DraftKings, the business model appears to be on solid footing for years of growth.
But as it grows, the industry must grapple with the problem of gambling addiction, which cuts across all social and demographic groups and can impact anybody. Currently, a bright light is being shone on the problem in the UK, where regulated gambling has been legal for decades, and where casinos and betting parlors are easily accessed.
According to BetBuddy CEO Simo Dragicevic, over half of the UK population gambles on a regular basis, putting them at risk of developing into problem gamblers, for whom the anticipation and thrill of gambling creates a natural high that can become addictive. The UK government is stepping up to address the problem, and doctors are even prescribing drugs like Naltrexone, which is normally used to treat drug addicts and alcoholics, in an effort to stave off the craving of gamblers.
BetBuddy, which is based in the UK, develops a software product called PowerCrunch that uses data mining and machine learning techniques to detect high-risk or problem gambling while the player is still engaged in the activity. The software, which was built using machine learning automation software from H2O, works by calculating a risk score for each gambler based on his or her actions, and then automatically sending out personalized and targeted messages and tests to the players, thereby helping to understand their own behavior and its implications, and possibly steering them away from potential problems.
Detecting Problem Gamblers
A lot of research has gone into the BetBuddy system, which is based on a three-tier model of gambling-related data that BetBuddy researchers published in the Journal of Gambling Studies in 2013.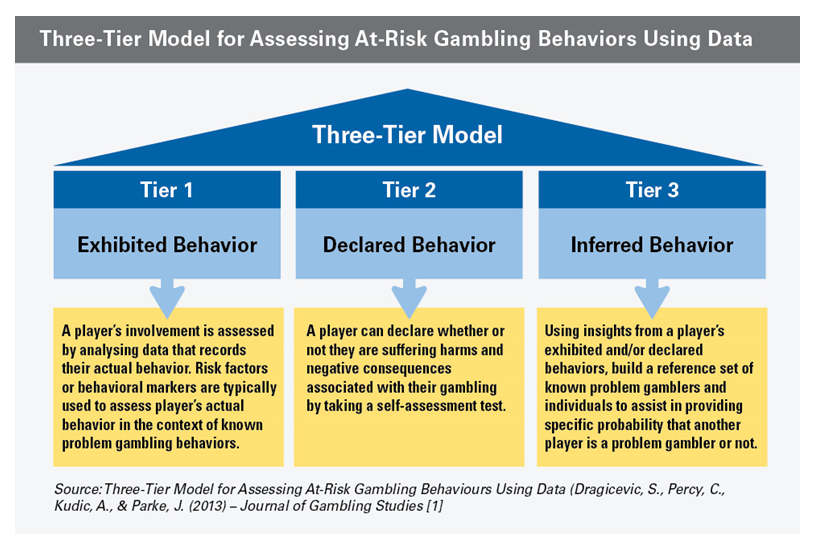
According to BetBuddy, the first tier analyzes exhibited behavior, or data collected directly from casino management system. The second tier looks at declared behavior, or the results of self-assessment test. The third tier revolves around inferred behavior, which is deduced by combining results from the first two to create a predictive model based on actual data gleaned from problem gamblers (anonymized to protect privacy).
Two years ago, BetBuddy set out to improve the accuracy of its inferred behavior model by working with the Machine Learning Group from City University London. The collaboration was funded by the UK’s innovation agency, Innovate UK, and involved contributions from the Engineering and Physical Sciences Research Council (EPSRC) and the Defense Science and Technology Laboratory (Dstl).
The challenge that BetBuddy faced was not trivial. While the vast majority of people who gamble do not become addicted to it, history shows that a small percentage will succumb to the gambling’s dark side. The key to success for BetBuddy lies in its ability to accurately identify the complex behavioral pathways that lead to the onset of gambling addiction, and then build a predictive software program that signals when those pathways are being filled using a combination of artificial neural networks, random forests, Bayesian network, and logistic regression algorithms.
The research yielded some interesting results–namely that using random forest algorithms could elevate the accuracy of BetBuddy’s forecasts of problem gamblers to 87 percent. That compares favorably to earlier peer-reviewed studies using a Harvard Medical School data set and methodology, which produced accuracies in the 62 to 67 percent accuracy range.
The key driver to the increased performance, the company says, was the technique that BetBuddy used to detect changes in behavior of players as they approach the point at which they experience harm.
Putting ML Into Production
The next challenge BetBuddy faced was operationalizing the insights generated by its platform, and that’s where the machine learning platform from H2O comes into the picture. According to H2O, BetBuddy analyzed a range of machine learning platforms that are compatible with Java, including Spark, Weka, and Mahout, but eventually settled on H2O.
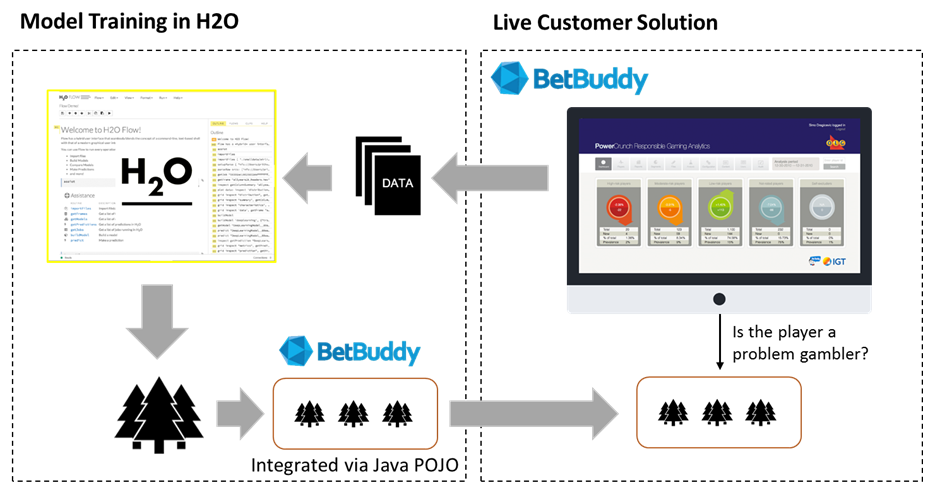 BetBuddy’s selection of H2O hinged on three main factors, Dragicevic says. First, the H2O software is not tightly tied to Hadoop, which BetBuddy wanted to avoid. It also doesn’t have the “experimental” tag that other platform shave, and doesn’t suffer from open source licensing restrictions (although H2O’s software is open source), the BetBuddy CEO says.
BetBuddy’s selection of H2O hinged on three main factors, Dragicevic says. First, the H2O software is not tightly tied to Hadoop, which BetBuddy wanted to avoid. It also doesn’t have the “experimental” tag that other platform shave, and doesn’t suffer from open source licensing restrictions (although H2O’s software is open source), the BetBuddy CEO says.
H2O also helped BetBuddy operationalize the machine learning models into PowerCrunch, which was written in Java. Because H2O could expose the models as POJOs—or plain old Java objects—it simplified the process of putting the machine learning models into action.
“The only platform that scored highly on all of BetBuddy’s selection criteria was H2O,” Dragicevic says. “These considerations, coupled with strategic developments undertaken by H2O to integrate with the most promising platforms in the market, such as Spark, gave BetBuddy confidence in its choice.”
Real World Impact
PowerCrunch is still fairly new, but BetBuddy’s “responsible gambling” solution is showing signs of adoption. In particular, the Ontario Lottery and Gaming Corporation (OLG) tested the software and concluded that nine out of 10 players found the software helpful in managing their personal gambling.![]()
Going forward, BetBuddy and City University are largely focused on opening up the underlying algorithms used in the system. Regulators and gaming executives, in particular, are interested in how BetBuddy’s software makes its predictions. The company is utilizing H2O’s model training analysis functionality in the hope of adding more transparency to the random forest and neural network algorithms that underlie the program.
As the gambling industry grows, casinos have a responsibility to identify the minority of gamblers who can’t rein themselves in. Innovative applications of data science, such as the one that BetBuddy is developing, show that responsibility in the gambling hall doesn’t have to come at the cost of excluding 95 percent of the population from having a little fun now and then.
Related Items:
How Big Data Can Help the Sick and Poor
How Big Data Is Helping Indian Schoolchildren
Sectors:
Other
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States