

January 14, 2016
As Data Science Evolves, It’s Taking Statistics with It

(rzoze19/Shutterstock.com)
While there are disagreements about what exactly constitutes a “data scientist,” there’s little doubt that one of the critical components involves statistical aptitude. And as the data science profession evolves, it’s taking the field of statistics with it, an expert with the American Statistical Association says.
Before the Harvard Business Review dubbed data scientist the sexiest job of the 21st century several years ago, few people outside of Silicon Valley had heard the term. But all of a sudden, the title was showing up in thousands of job descriptions, as companies sought the key personnel who could help them make sense of the big, messy, and fast-moving data they were collecting.
McKinsey & Co compounded the problem when it warned that demand for data scientists was far outstripping supply, which seemed to amplify the run on data scientists even more. Universities responded by creating more post-graduate program designed to educate people with data science skills. It’s estimated that there are more than 100 such master’s and PhD level programs across the United States today, but it’s barely putting a dent in supply, as some estimate the shortage of data scientists will soon reach 1 million individuals.
In the classic Venn diagram for data science, there are three components: math and statistics; computer science; and subject matter experise. Of the three, it could be argued that the first one is the most critical to data science in the classic sense (if there is such a thing). Is somebody who’s an expert in distributed computing and banking a data scientist? Most familiar with the analytics field would say no.
While data science and statistics are clearly not the same thing, it’s also clear that the skyrocketing popularity of the former is having a measurable impact on the state of the latter. We’ve yet to see how the traditionally button-downed statistical community will respond to the allure of big data fame and glory. But it’s clear that the field of statistics is beginning to stir thanks to the lift provided by big data.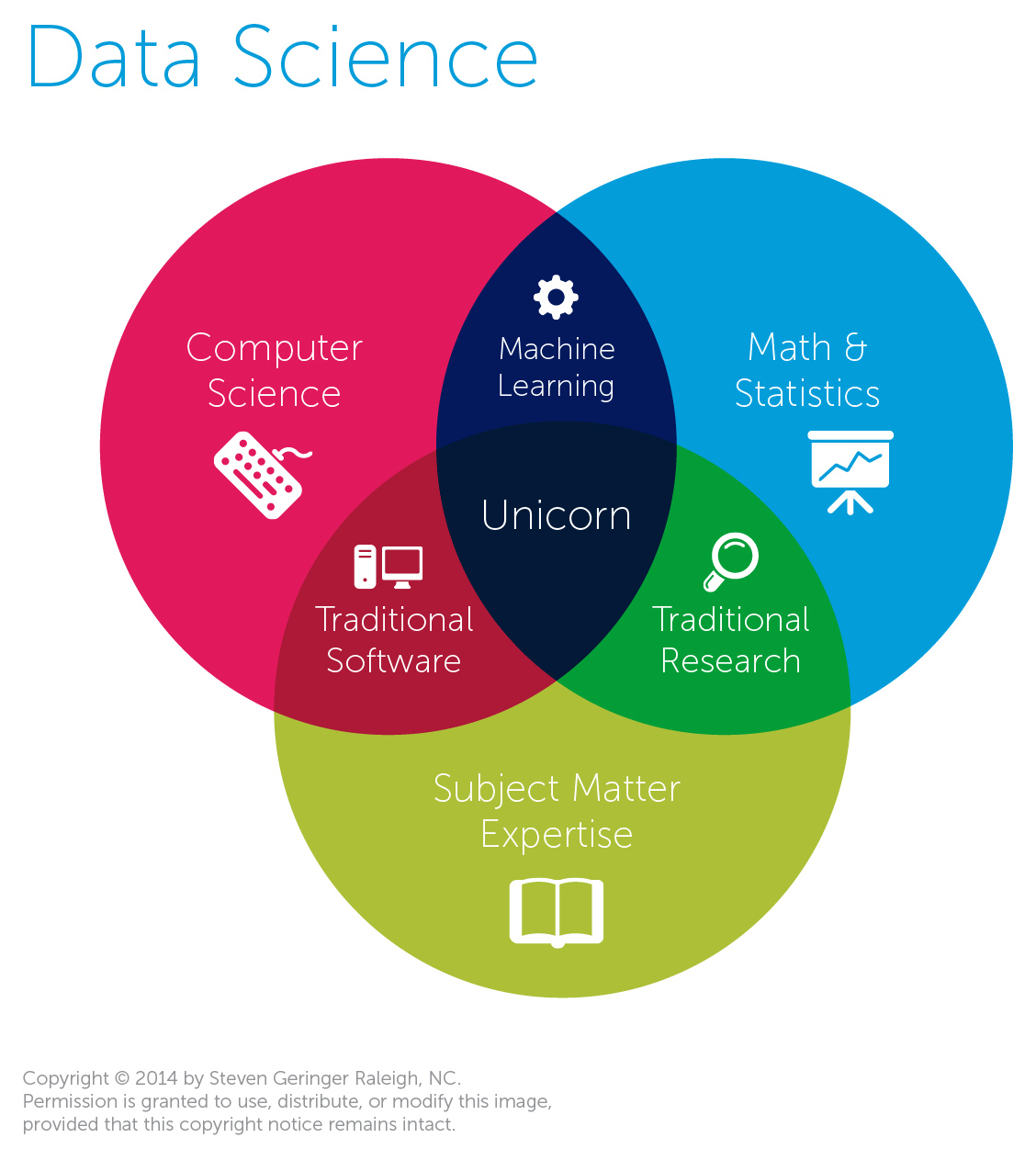
“I don’t think you can state it strongly enough,” says David van Dyk, a member of the American Statistical Association. “I’m not sure what the future will hold. That is to say, it could be a big data bubble. It could be that our hopes are getting too high and people will turn to something else because it [big data] really has a life of its own.
“On the other hand,” van Dyk continues, “if you compare what is the view or the public perception of statisticians 20 years ago, there was no public perception of statisticians! It was completely off the radar. You never heard about field statistics in the news before, or had young kids thinking this is a career opportunity for them. Just by virtue of us being put into the limelight, it’s changing statistics.”
Statistics’ Changing Role
The ASA is reaching out to the statistics and data science communities in hopes of sparking a dialog about what role statistics will play in data science going forward, and how universities and other institutions can best train the next-generation of data scientists with relevant statistical abilities.
In October, van Dyk and other ASA members published a statement in the ASA’s online publication, AMSTATNEWS, on the role of statistics in data science. The article reads in part:
Certainly, data science intersects with numerous other disciplines and areas of research. Indeed, it is difficult to think of an area of science, industry, commerce, or government that is not in some way involved in the data revolution. But it is databases, statistics, and distributed systems that provide the core pipeline. At its most fundamental level, we view data science as a mutually beneficial collaboration among these three professional communities, complemented with significant interactions with numerous related disciplines. For data science to fully realize its potential requires maximum and multifaceted collaboration among these groups.
“We wanted to say what we think and stimulate some conversation,” van Dyk tells Datanami, “but then go on and enunciate specifically what statisticians can do and how they can play a central role in data science.”
As van Dyk sees it, the field of statistics is changing as a result of the big data revolution. “The theory of statistics and mathematics shouldn’t change. But I would say that the theory has to be extended,” he says. “There’s new paradigms that weren’t particularly important in the past because data was more limited. And because of the size of the data set, we need to contend ourselves with different kinds of errors that require different thinking.”
![]() For example, calculating statistical error and making sure it’s within certain bounds used to occupy a large chunk of the statistician’s time. But thanks to big data’s capability to deliver us huge sample sizes from enormous populations, the sampling error isn’t as big of an issue as it once was.
For example, calculating statistical error and making sure it’s within certain bounds used to occupy a large chunk of the statistician’s time. But thanks to big data’s capability to deliver us huge sample sizes from enormous populations, the sampling error isn’t as big of an issue as it once was.
Instead, the modern statistician must contend with other things that can contaminate the equations, such as biases, says van Dyke, an American who teaches at Imperial College London in the UK. “You can have a misrepresentation of the truth in the massive data you have,” he says. “It’s a different kind of error that’s quantified in a different way.”
The old adage “correlation does not equal causation” will continue to keep statisticians up at night, especially as random fluctuations in the data lead them down rabbit holes. But types of errors, such as false positives, may require some new thinking.
“Now if you have a massive data set and you’re checking more and more things, hopefully your finding more positives and more interesting results, but they’re going to be hidden in more and more false results,” van Dyk says. “There’s things that definitely hold over and are tweaked a little bit, and there are places that really require new thinking.”
Pushing the Boundaries
The field of statistics has already gone through several periods of rapid evolution during the ASA’s 177-year existence. “The way statistics did their work before desktop computing–we don’t teach those,” van Dyk says. “It doesn’t make any sense anymore.”
That’s why the ASA is strongly encouraging statisticians to adopt some of the aspects and skills that are commonly associated with data science, such as the capability to manage large amounts of data and to take advantage of the scale of distributed computing.

(bluebay/Shutterstock.com)
“We went through a revelation, a revolution, a transformation at that time [when desktop computing emerged],” he says. “Now in some ways it’s a continuation of that same transformation, but it’s definitely again changing the way we think about doing data analytics because of the technology we have available to us and the data that’s available.”
In this day and age, it would be rare for a prospective data scientist who is learning advanced applied statistics in a Master’s or PhD program to not get their hands dirty with data. Data is everywhere in higher learning, whether it’s a “pure” data science program (of which there are few) or, more likely, an inter-disciplinary program of which statistics is one part.
But it’s also critical to learn to apply statistics against the advance distributed computing systems of our age, which are becoming inextricably linked with statistics, van Dyk says.
“It’s easy to think that that the math is the hard part. But in the real world getting your code to run and getting your distributed systems to run and making sense of your data and cleaning the data–dealing with strange artifacts in the data–all those require thought,” he says. “You can get funny answers if you don’t do them well. So those are important skills And in some ways it’s harder because it’s less conducive to classroom activity.”
A new discipline is emerging, and the term “data science” is the main flag bearer. But the field of statistics is right there alongside it.
“I, as a statistician, will be a better statistician in a 21st century data problem if I know a little about databases and computing, because that will enable me to collaborate with others,” he says. “I do think that it would be better if we push the boundaries a little bit.”
Related Items:
Beware of Bias in Big Data, Feds Warn
What Does 2016 Mean for Data Science?
Data Science Education Gets Stronger, But It’s Not There Yet
Sectors:
Academia
Vendors:
American Statistical Association
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
Call & Contact Center Expo
 April 24 - April 25Las Vegas NV United States
April 24 - April 25Las Vegas NV United States -
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States