

December 17, 2015
New TPC Benchmark Puts an End to Tall SQL-on-Hadoop Tales

(Bakhtiar Zein/Shutterstock)
You take certain things for granted in the big data world. Data will continue to grow at a geometric rate. Amazing new technologies will regularly appear out of nowhere. And software vendors will squabble endlessly over whose SQL-on-Hadoop engine is fastest and best. Thanks to a new TPC-DS 2.0 benchmark unveiled today, we may take the last one off that list.
The Transaction Processing Performance Council (TPC) organization today unveiled a new benchmark for gauging the performance of SQL engines running on big data platforms. The new metric is a variation of the longstanding TPC-DS benchmark, and should give customers greater clarity when comparing SQL execution engines and query optimizer, whether they run on big data platforms like Hadoop or regular RDBMSs.
One of the big goals with the creation of TPC-DS 2.0 was putting an end to the practice of big data vendors “cherry picking” parts of the old TPC-DS benchmark to give a skewed picture of their SQL engine’s performance, says Meikel Poess, chairman of the TPC-DS committee.
“Many of the big data players use the TPC-DS benchmark in some sort of form to claim certain performance numbers, and they’re cherry picking the queries they run best. They change the execution rules sometimes and come up with their own metric,” Poess tells Datanami. “So the TPC said, why don’t we modify the TPC-DS to cater to these big data players who have products out there that are SQL-based but that have a hard time running the very stringent rules of TPC-DS.”
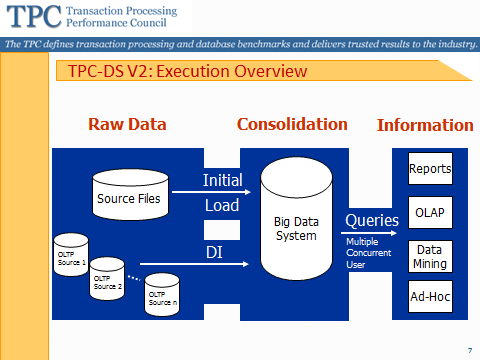
Like the first TPC-DS, the new benchmark models the decision support functions of a retail product supplier operating in brick-and-mortar, online, and catalog sales. It measures how quickly a SQL engine can run a variety of queries (ad-hoc reporting, iterative OLAP, and data mining) in single-user and multi-user modes. It also measures how quickly a SQL engine can complete an initial data load, and provides some data integration (ETL) measurements as well.
But some key changes were made to the new benchmark. For starters, it no longer requires the underlying database (or file system, in Hadoop’s case) to comply with ACID properties that have been expected for so long in the world of RDBMs. Dropping the ACID requirement doesn’t mean that TPC-DS 2.0 doesn’t reflect real-world conditions, says Poess, whose day job is at Oracle.
“In the big data area, ACID does seem to be such a big issue because data is mostly read-only,” he says. “Data is not necessarily coming in on a continuous basis. There are usually…windows where they can load data into the database, so it’s kind of a different scenario. It’s not a pure data warehouse.”
The second big change is the elimination of the need to run under enforced constraints. The original TPC-DS required the database to enforce constraints (usually against foreign keys and primary keys), but those requirements have been eliminated with TPC-DS 2.0. “There is a cost to having an enforced primary-key, foreign-key constraint,” Poess says. “You can still run with enforced constraints, but you don’t need to anymore.”
The third big change is the elimination of trickle updates. The TPC decided against using trickle updates—which is a common way to keep data warehouses current—because it would have required ACID compliance, Poess says.
The final change is the way the final score is tabulated. In the previous TPC-DS version, the various sub-components of the test were weighted more or less equally. But taking a straight arithmetic-mean approach would have result in potentially skewed results in the brave new big data world, so with TPC-DS 2.0 the final score is calculated on a geometric-mean basis.
Poess elaborates on that change. “The reason for that primarily was to give all the pieces in the metric equal importance. If we don’t have a geometric mean metric, then the emphasis is too much on data integration portion,” he says.
 At the end of the day, a benchmark has to be fair and it has be unbreakable. One could argue that the old TPC-DS benchmark was neither fair nor unbreakable when you factored the big data and Hadoop players into the mix. The organization is confident it has remedied that problem with TPC-DS 2.0
At the end of the day, a benchmark has to be fair and it has be unbreakable. One could argue that the old TPC-DS benchmark was neither fair nor unbreakable when you factored the big data and Hadoop players into the mix. The organization is confident it has remedied that problem with TPC-DS 2.0
“The intent is to look at [the old DS benchmark] and come up with a version that lifts some of the requirement that prevents them from running, while at the same time not making the benchmark meaningless,” Poess says. “We still kept a lot of the characteristics of the original TPC-DS. We kept all the queries, and the queries are fairly complex and they put a lot of stress on both the execution engine and also query optimizer.”
What’s more, traditional database and EDW vendors can still participate. The TPC-DS 2.0 benchmark was created in such a way that it can accurately measure the performance of IBM (NYSE: IBM), Microsoft (NASDAQ: MSFT), and Oracle (NYSE: ORCL) databases. “We definitely targeted all these vendors who were cherry picking portions of original TPC-DS and came up with something that both the traditional database companies can agree on, as well as the new big data players,” Poess says.
TPC also unveiled TPCx-V, a new “express” benchmark aimed at gauging the performance of virtualized environments. TPCx-V models a cloud computing environment that seeks to measure how well virtualized platforms can handle a variety of business intelligence and OLTP workloads.
“In a cloud environment, you have various sizes of VMs,” says says Reza Taheri, chairman of the TPCx-V committee. “You have some tiny ones and some huge ones. And you want to challenge the virtualization platform to see if it can handle both. Can it handle the demand of the very large VMs without ignoring the small ones? Our VMs have very different sizes and they have different workloads.”
TPCx-V should help assuage the fears that CIOs have over running production database workloads in virtualized environments, Taheri tells Datanami.
“There’s been a lot of concern about virtualizing databases because of the overhead,” says Taheri, who’s day job is at VMware. “They were virtualizing web servers, logic, etc. but the database was staying on physical [hardware] because of concerns with putting their crown jewels on a virtual server. So this benchmark addresses this. If you’re virtualizing your servers, and you’re wondering ‘Can it handle my database workloads?’ you can use this benchmark to answer this question.”
It’s the second “express” benchmark from the TPC. Express benchmarks are downloadable and have auditing built-in, thereby eliminating the need for an external auditor to validate the results.
Related Items:
Spark Smashes MapReduce in Big Data Benchmark
BigData Top 100 Benchmark Nearing Completion
TPC Crafts More Rigorous Hadoop Benchmark From TeraSort Test
Technologies:
Middleware
Sectors:
Retail
Leading Solution Providers









Tabor Network
Sponsored Multimedia








{kind=link}
Featured Events
-
Call & Contact Center Expo
 April 24 - April 25Las Vegas NV United States
April 24 - April 25Las Vegas NV United States -
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States