

November 9, 2015
Part Two: MapR’s Top Execs Sound Off on Hadoop, IoT, and Big Data Use Cases

John Schroeder, CEO and co-founder of MapR Technologies, and newly hired COO and president Matt Mills recently sat down for an interview with Datanami. Here’s part two of our chat.
To read part one, see www.datanami.com/2015/11/03/maprs-top-execs-sound-off-on-hadoop-iot-and-big-data-use-cases.
Datanami: So many big data roads point back to the need for better data governance. What is MapR’s strategy there?
John Schroeder: We approach it more as a company issue, not a big data issue. They’ve got many terabytes, petabytes of data across platforms, new ones like MapR’s and legacy ones. You have to approach it from a company-wide perspective. You can’t just go in and build a governance tool for Hadoop. The governance problem is bigger than that. You need to approach it like a company-wide perspective and then plug and play with the other governance technologies they have in place.
Datanami: What is MapR’s strategy for Apache Spark?
Schroeder: We love Spark. There are five projects related to Spark, and we were the first one to include all five projects. We just did a survey of our customer base of which open source projects they use, and Spark is definitely broadly used, especially in the enterprise accounts. We do get revenue from Spark. It expands the use cases the customer can do. It’s a good source of business for us
But as a replacement for Hadoop’s compute engine? If you want to do interactive query, data discovery against your data lake, you’re probably going to use sorting like Apache Drill or perhaps Impala. So it’s one of the compute engines — certainly a hot one today. It is certainly taking on the use cases that have traditionally been done in MapReduce. [But] you still need a persistence layer. You still need other technologies to process the data. It’s not going to do 100 percent of your use cases. There’s no NoSQL processing in Spark. There’s weak interactive SQL processing in Spark. It’s part of our distribution, but it’s one of the set of technologies that you need to process your big data.
Datanami: How important is open source to MapR? One of your competitors touts its closeness to open source, whereas MapR is viewed as the most proprietary.
Schroeder: It’s definitely a way that one of our competitors likes to positon it. Hortonworks has hung their hat on open source being core to the value proposition. Cloudera is quite like MapR. They announced their hybrid open source strategy. HOSS is very similar to what we’ve done since day one. The difference is we started out day one and Cloudera started that 18 to 24 months ago.![]()
I think we’ve taken the approach that software companies are going to use in the future, which is you want to be able to participate in the community. You want customers to able to benefit from the innovations [in open source]. And in the application layer, you want your customers to be comfortable that they’re using an industry standard set of technologies to build their applications so they’re not going to have artificial lock-ins to a particular vendor.
On the other hand they need more than what open source is providing. That’s the recipe we put together when I founded the company. If you look at the 25 open source projects we include in our distribution, we have a huge amount of engineering resource on that. We provide best-in-class support on the open source. We run that all on MapR’s engine. So we have replacement for the underlying file and storage layer in Hadoop, which gives us a big advantage in the marketplace and allows us to expand beyond the use case cases that Hadoop can support.
And the innovation at that layer is generally vendor driven. If you look at other vendors who take similar approaches…IBM has GPFS as a replacement. That area was made to be pluggable. We’re just the only one who literally built a purpose-built service for this use case–meaning thousands of servers with exabytes of data and multiple computer platforms. That’s what gives us our advantage in the marketplace. I would say Hortonworks is the only vendor whose linchpin is being the most open source content. To most of our customers, it’s irrelevant.
Datanami: Has the lack of data scientists caught the attention of MapR and if so what are you doing about it?
Schroeder: It’s still an issue in the industry. There’s absolutely a shortage. It’s like being an Oracle DBA in 1993. There’s a shortage on them, but on the other hand, that’s what everybody wants to learn. If they get that skillset, they’ll earn 30 percent more than their friends for the next 30 years.
There’s a shortage of talent but there’s a tremendous desire in the industry to plug up those skills. We put together MapR training academy, and we’ve had over 40,000 students go through the coursework in that training facility since January. So we’re helping to close the gap.
From a technology standpoint, we’ve closed the gap a lot. All these companies have tremendous talent with SQL. So technology like Apache Drill opens up a familiar SQL interface to Hadoop. Hand in hand with that, to make SQL work, you need some structure around the data. So we’ve opened up Hadoop with a project called OJAI that opens up self-describing data interchange formats like JSON. So basically, the modern way of structuring data is to have the applications publish the structure with the data, instead of having an army of DBAs to manually create structure.
Datanami: It’s been said that Hadoop hits a wall at 400 nodes, and that you get diminishing returns the bigger you go. Does that jibe with what you see?
Schroeder: With vanilla Apache Hadoop there’s a lot of truth in that. It doesn’t have the performance and throughput. It’s also subject to availability problems that larger clusters get. That’s something we addressed in the first couple versions of MapR. We can drive much more throughout, much more dense servers. We have a 3,000-node cluster running in production in financial services. It’s availability characteristics are similar to enterprise products lie VMware or Oracle.
 When you look at very early implementations of Hadoop, there were lots of small servers, doing batch processing, almost archival. With the 3,000 cluster I’m talking about, there’s a very high usage rate. It’s seen as primary storage. There’s a lot more read and write update activity. It’s much more like a database environment. You could put together a large cluster and use it as an archive, but that wouldn’t be very challenging. The ones we’re doing are much more operational in nature, and have similar usage characterizes as a traditional database than an archive.
When you look at very early implementations of Hadoop, there were lots of small servers, doing batch processing, almost archival. With the 3,000 cluster I’m talking about, there’s a very high usage rate. It’s seen as primary storage. There’s a lot more read and write update activity. It’s much more like a database environment. You could put together a large cluster and use it as an archive, but that wouldn’t be very challenging. The ones we’re doing are much more operational in nature, and have similar usage characterizes as a traditional database than an archive.
Datanami: Are performance boosts in the future going to come largely from innovation at the hardware layer, through things like flash storage, in-memory computing, and faster interconnects, or are we going to get more performance from innovation in the software?
Schroeder: You’ve got to ride those waves. You think of Hadoop proper–why was Hadoop successful? CPU was basically free, and connectivity was free and storage was free. When I first stated shipping product in 2011, you could get a 1TB drive. Now customers regularly order 4TB drives. There’s no reason to conserve those resources, so it created a new design center for the software.
There’s a move to large memory or Flash or even PCIe-attached flash like NVMe. Then you have to architect again around storage and data I/O. Whenever you’re trying to drive performance, you’re going to have a bottleneck. If you have more flash and more memory then your CPU become the bottleneck, so you have to architect your software to do multi-threading to take advantage of it.
Absolutely you’ll see a wave that’s going to take advantage of 40GbE networks and 10GbE networks and both RAID attached flash and NVMe flash. We got a head start on that. Samsung published a benchmark on that two months ago where we were getting 16GB per second using MapR running Samsung NVMe flash. So you’ll see that wave as long as you’ve got a software stack that tunes to that new flash storage and large memory footprint. You do have to make some changes to your technology to take advantage of it.
Datanami: As the performance capabilities and characteristics change, how will you help your customers take advantage of this with real-world applications?
Schroeder: It has to be more and more real time. Hadoop started out as batch predictive analytics. But if you’re an etailer you need to be able to respond to your customer in Web time while they’re on your site. And if you’re a credit card company you need to respond with a credit card swipe.
Then you explode that to the IoT and the requirements for real-time get even more. That’s where this is all taking us, much more real time processing. The hardware will take us a little further and the software will be able to take more advantage of the hardware.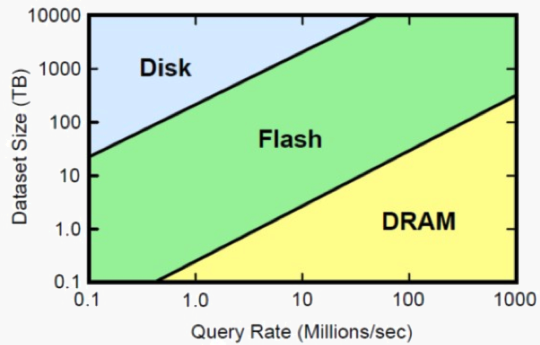
Datanami: How will the design patterns change?
Schroeder: The biggest change is probably around IoT. If you look at Hadoop it’s generally about dragging an Exabyte of data into a single cluster and processing it. But if you look at IoT you’ve got processing on the device itself. You need to have processing that happens at the edge and you probably need to forward more information to a central cluster. That’s why you’ve seen us develop things like multi-master table replication so we can put smaller code footprint in multiple locations and have them synchronized. That’s where you’re seeing us come out with a messaging components to be able to, at extreme scale, be able to message reliability between components. The next wave will be more distributed process than a centralized process we’ve seen over Hadoop for the past few years.
Related Item:
MapR’s Top Execs Sound Off on Hadoop, IoT, and Big Data Use Cases
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
Call & Contact Center Expo
 April 24 - April 25Las Vegas NV United States
April 24 - April 25Las Vegas NV United States -
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States