

October 12, 2015
Inside Yahoo’s Super-Sized Deep Learning Cluster

(sakkmesterke/Shutterstock)
As the ancestral home of Hadoop, Yahoo is a big user of the open source software. In fact, its 32,000-node cluster is the still the largest in the world. Now the Web giant is souping up its massive investment in Hadoop to give it a deep learning environment that’s the envy of the valley.
With more than 600 petabytes of data spread across 40,000 Hadoop nodes, Yahoo is obviously a big believer in all things Hadoop. After all, Doug Cutting and Mike Cafarella worked for Yahoo when they first created Hadoop 10 years ago.
But the latest news out of Yahoo show the company is pushing the limits of traditional Hadoop and encroaching on high performance computing’s (HPC) traditional stomping grounds. In a blog post, the company’s engineering department shared information about their efforts to build a large-scale deep learning environment directly on Hadoop.
By outfitting some nodes of Hadoop nodes with GPUs—specifically, four NVIDIA Tesla K80 cards, each of which carries two GK210 GPUs–and connecting the nodes with 100Gb InfiniBand interconnects, Yahoo has amassed some serious computational firepower to run deep learning algorithms.
“It’s a very high-compute hardware infrastructure that is more like traditional supercomputer and HPC efforts than the traditional Hadoop hardware,” Yahoo vice president of engineering Peter Cnudde tells Datanami. “GPUs are the best way to implement [deep learning algorithms] because of their very high compute capability and memory bandwidth. There’s a lot of people in the industry and this space who are using GPUs for those kinds of algorithms, and so are we.”
Spark and Caffe
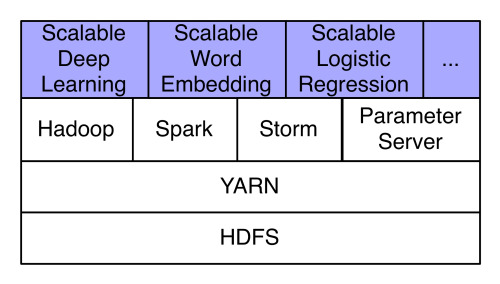
Yahoo’s deep learning stack runs atop Hadoop
The hardware is clearly impressive, with each GPU-enabled node offering 10x the processing power as a traditional CPU node, according to Yahoo’s blog post. But perhaps equally impressive is the work Yahoo did on the software side to enable Spark- and GPU-powered deep learning to run atop its everyday Hadoop infrastructure.
As Cnudde explains, Yahoo adapted the open source Caffe package (which provides the framework for programming the GPUs) to enable it to work with Spark. “We’ve basically brought Spark and Caffe together” in a “loosely coupled” manner, Cnudde says.
For customers who are already well-versed in Spark and the concept of resilient distributed datasets (RDDs), adding Caffe and GPUs into the mix is not that big a deal, he says.
“If you’ve already done your traditional processing on Spark, and you have your data in an RDD and ready in Spark, now you can just call the Caffe library and it will then automatically run it on the GPUs using Caffe, and the results are materialize as an RDD in Spark for which you can then continue,” Cnudde says. “That’s kind of what we provided. So for people who are not real experts but are familiar with Spark, it’s just a couple of API calls and it will work.”
Yahoo is contributing this capability back to the open source community with the hope that it will help other Hadoop and Spark users adopt deep learning technologies and techniques, like GPUs and Caffe.
Hadoop Goes Deep
Hadoop is critical for Yahoo’s business. It stores all of its data in HDFS, and relies on the power of YARN to allow it to bring different computational engines to the data. So it was natural for Cnudde’s team to build a deep learning environment atop Hadoop, and now that it’s built, various teams within Yahoo are being encouraged to find ways to use it.
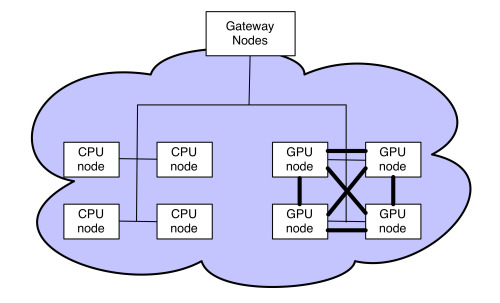
Yahoo uses both Ethernet and InfiniBand in the deep learning parts of its Hadoop clusters
“A key strength of Hadoop is the breath of the ecosystem,” Cnudde says. “All of our data is on HDFS, and all these different compute environments have come tougher. So we might prepare some of that data with our existing pipelines using traditional MapReduce, and then we can run a traditional Spark job on that data or do some analysis, and it’s all still on the same hardware.”
The addition of GPU nodes for deep learning just adds another dimension to this Hadoop ecosystem. “On our largest Hadoop cluster, we have GPU nodes, so we can run GPU jobs…all on the same environments, and then dump the results onto HDFS where some post processing can deal with it.”
The combination of Spark and Caffe are critical to Yahoo’s deep learning pipelines. Yahoo’s deep learning system encompasses three distinct stages, including the data prep, the running of the deep learning algorithm, and the post processing. Spark is used for the first and third steps, while Yahoo supplies its own algorithm. for the
“For our data set, which is typically very large, we find that Spark is very good at the initial stage – data preparation and the traditional ETL-like functional of data processing,” he says. “And for core machine learning, we have very specialized internal engines that solve these things better than Spark does at the moment, like in this case, Caffe on GPU. Then for post processing – Spark is very good at providing interactive analysis capabilities for the data scientists.
Growth of Deep Learning
Yahoo’s deep learning environment is currently used primarily for categorizing and detecting objects in Flickr customers’ images, Cnudde says. (Flickr, of course, is a subsidiary of Yahoo.) But it’s just a matter of time before deep learning powers additional use cases.![]()
“Machine learning is key to every part of our business, from image recognition, targeting of people, advertisement targeting, search rankings, personalization, and abuse detection,” Cnudde says, “and I would think that deep learning has probably a role in most, if not all of them…There are plenty of other applications internally that we have not publicly talked about. It’s across our business, as you can imagine.”
As Cnudde sees it, there’s a very good chance that deep learning will basically carry the flag for machine learning going forward. “There’s an enormous amount of interest around deep learning in academia, and as a result, deep learning algorithms are beating traditional machine learning algorithms in almost every single benchmark they compete in, from object recognition in images, to a whole series of others,” he says.
Today, deep learning still requires an additional level of technical aptitude, Cnudde says, but the maturation curve is rapidly flattening, which should help democratize deep learning technology going forward.
“At the moment these [deep learning] tools are still hard to use,” he says. “There’s a level where it requires more expertise than Spark does. It’s closer to academia. But I think that will evolve and I would imagine a strong interest from the Spark community to make that more deeply integrated and just as easy to run a deep learning algorithm as it is to run a more simpler algorithm.”
Related Items:
How NVIDIA Is Unlocking the Potential of GPU-Powered Deep Learning
Three Things Apache Spark Needs to Out-Hadoop Hadoop
Yahoo: We Run the Whole Company on Hadoop
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
Call & Contact Center Expo
 April 24 - April 25Las Vegas NV United States
April 24 - April 25Las Vegas NV United States -
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States