

September 28, 2015
Cloudera Unveils Kudu, a Fast New Storage Option for Hadoop

Hadoop has been evolving from its batch-oriented roots into a more real-time system for some time. That evolution gained momentum today with Cloudera’s announcement of Kudu, a new in-memory data store for Hadoop designed to support real-time analytics on fast changing data.
Historically, Hadoop users have had to make compromises with the data store when developing real-time analytic applications. They could power fast sequential scans with HDFS or power fast random access with HBase, which is essentially a NoSQL database built into Hadoop. But if they wanted to do both–which is often the cast with real-time analytics on data from the Internet of Things (IoT)–then it required developing convoluted architectures.
Cloudera hopes to “dramatically simplify” these Hadoop architectures for IoT analytic use cases with Kudu. As a third data store option alongside HDFS and HBase, the column-oriented data store is said to deliver nearly the performance of HDFS for sequential scans and nearly the performance of HBase for random reads.
“As a new updatable, columnar store for Hadoop, Kudu complements the capabilities of HDFS and HBase and is purpose-built for use cases requiring a simultaneous combination of sequential and random reads and writes,” Cloudera says in its announcement. This eliminates “the need for complex architectures for common use cases, including time series analysis, machine data analytics, and online reporting.”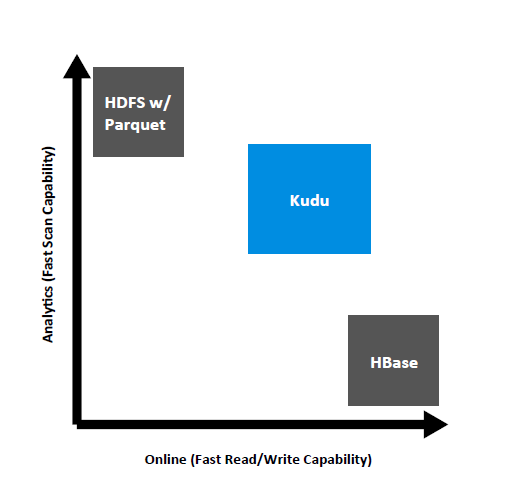
Kudu today sports Java and C++ APIs and features an “early integration” with Cloudera’s SQL query engine Impala, according to a story about Kudu in VentureBeat last week. Cloudera is said to be in the process of developing an integration for Apache Spark, which Cloudera is positioning as a replacement for MapReduce for many Hadoop workloads.
Cloudera developed Kudu with help from business partners, including Intel, which took a large stake in the Hadoop pioneer last year. Intel, Cloudera notes, is helping to ensure that Kudu can take full advantage of its memory and processor designs, including 3D XPoint, the next-gen, non-volatile memory architecture that Intel and Micron unveiled in July, which is said to be up to 1,000 times faster than NAND and enable storage density 10 times denser than traditional memory.
Other partners participating in the development of Kudu include AtScale, which is developing OLAP software for Hadoop; Splice Machine, which wants to use Hadoop to power relational database for OLTP apps; Zoomdata, which uses Spark to power streaming real-time queries; and Xiaomi, the world’s fourth-largest manufacturer of smartphones.’![]()
Baoqiu Cui, chief architect at Xiaomi, described his company’s participation in the beta program for Kudu and its contribution. “Our infrastructure team has been working with Cloudera to develop Kudu, taking advantage of its unique ability to support columnar scans and fast inserts and updates to continue to expand our Hadoop ecosystem footprint,” Cui says. “Using Kudu, alongside interactive SQL tools like Impala, has allowed us to build a next generation data analytics platform for real-time analytics and online reporting.”
Cloudera is releasing Kudu today as a beta under an Apache open source license. The company plans to eventually transition the Kudu project to the Apache Software Foundation. Kudu, by the way, is a species of Antelope native to Africa, which is home to another type of antelope–the Impala.
But Wait, There’s More!
As if the launch of a third data storage option in Hadoop wasn’t enough, Cloudera also today unveiled RecordService, a new “core” security service for Hadoop. The software will present a security layer that “centrally enforces access control policies for every Hadoop access,” the company says.
Security is a critical part of Hadoop, says Mike Olson, co-founder and chief strategy officer of Cloudera. “However, for Hadoop to continue to evolve and support the next generation of analytics for ever-growing amounts of users and access paths, security needs to become universal across the platform.”
The new RecordService software should take a big step in that direction by “fulfill[ing] the vision of unified fine-grained access controls for every Hadoop access path,” Olson says.
The software also provides data masking, thereby obscuring sensitive data as it’s being accessed. Like Kudu, RecordService is available now in beta under an Apache license, with plans to contribute the software to the ASF in the future.
Related Items:
Cutting: Spark an ‘All-Around Win’ for Hadoop
Spark Is the Future of Hadoop, Cloudera Says
Intel Exits Hadoop Market, Throws In with Cloudera
Vendors:
Cloudera
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States