

September 22, 2015
Inside Platfora’s Transition to Apache Spark

Platfora has embraced Apache Spark as the underlying data processing engine in version 5 of Big Data Discovery, which it announced today. But the company hasn’t completely gotten rid of MapReduce in its Hadoop application, and the reason may surprise you.
Platfora ‘s Big Data Discovery combines many of the steps involved in analyzing big data–from data cleansing and transformation to data visualization–into one solution that runs natively on Hadoop. Platfora was one of the first analytic tool vendors to target Hadoop in an end-to-end manner, and the company enjoys a healthy customer list that includes such blue chip names as Bank of America, Disney, UnitedHealthGroup, Sears, and J.P. Morgan.
Like all Hadoop vendors at the time, Platfora adopted MapReduce as the programming and run-time framework underpinning its Hadoop software. But in recent years, as MapReduce has shown its age, the company has adopted newer technologies, like Apache Spark.
With the launch of Big Data Discovery 5.0, Platfora has heavily adopted Spark to do most of the heavy lifting, particularly for data blending and discovery tasks, says Peter Schlampp, vice president of products for Platfora.
“With Spark in the background it’s just faster,” Schlampp tells Datanami. “You can work with more data at any given time, and we’re able to calculate these statistics in real time and guide people in the decisions they need to make.”
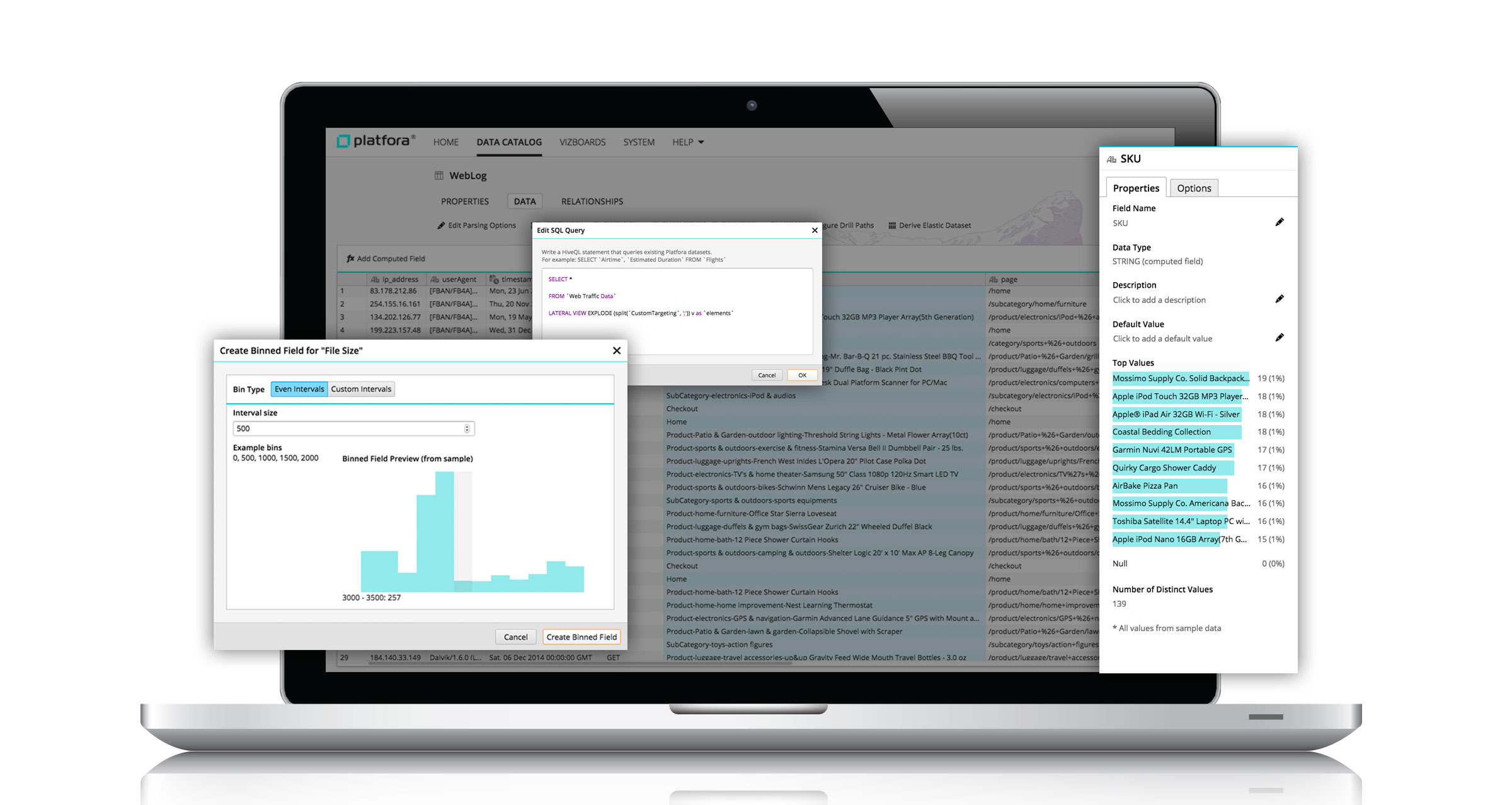
Platfora’s data preparation facility is now powered by Spark
In previous releases, the data prep component of Platfora’s tool could show 20 lines at a time, giving the user an idea of how the transformation would be carried out. With Spark under the covers and a new UI, Platfora is now able to incorporate samples of 10,000 or even 100,000 rows, Schlampp says.
Why does having so much more data in the system matter? “When we have more data, we’re able to guide you better on the decision you need to make in terms of preparing the data,” he says.
Platfora would have liked to have gotten rid of MapReduce completely. In fact, a year ago the company built a prototype that was completely built on Spark. But the performance of the MapReduce-less product just was not there.
“We realized pretty quickly that there’s some things that Spark does amazing well,” Schlampp says. “It’s really fast and makes our lives easier. It’s easier to program against Spark than MapReduce. But at the same time, there’s some things that Spark doesn’t do as well as MapReduce.”
That comment may go against the popular notion that Spark is superior to MapReduce in every way. But that just doesn’t jibe with reality as Platfora sees it.
“MapReduce is better…when you’re dealing with lots of very large files that need to be pulled from disk,” Schlampp continues. “Spark is a great technology when you’re able to fit all the data in memory. But when you can’t, it starts to slow down.”
![]() That’s not to say that Platfora isn’t committed to using Spark. “We are 100 percent on the Spark bandwagon and have contributors here at Platfora,” Schlampp says. “We’re big advocates. But we want to be pragmatic about using the right technology for the right thing.”
That’s not to say that Platfora isn’t committed to using Spark. “We are 100 percent on the Spark bandwagon and have contributors here at Platfora,” Schlampp says. “We’re big advocates. But we want to be pragmatic about using the right technology for the right thing.”
In addition to the improved data preparation, Big Data Discovery 5.0 brings several other new features, including tighter integration with the CDH Hadoop distribution from Cloudera.
For starters, Platfora is how adopting Apache Sentry, the user authorization component of the Apache Hadoop stack that was written by Cloudera. Sentry has been integrated with other parts of the Hadoop stack, such as Hive, Pig, and MapReduce, but it hasn’t been adopted much by third-party applications. Platfora hopes to change that.
“Now we are adopting it. Now the delegated authorizations capability connects directly to Hadoop,” Schlampp says. “It reads the Sentry permissions and then the permission get propagated into Platfora when you’re accessing data…. It just makes it easier for you to do it one time in Sentry than have to do it in all these different applications and manage it separately.”
Platfora is also now supporting Parquet, the compressed data format that is used by Impala, Cloudera’s flagship SQL query engine for Hadoop. While
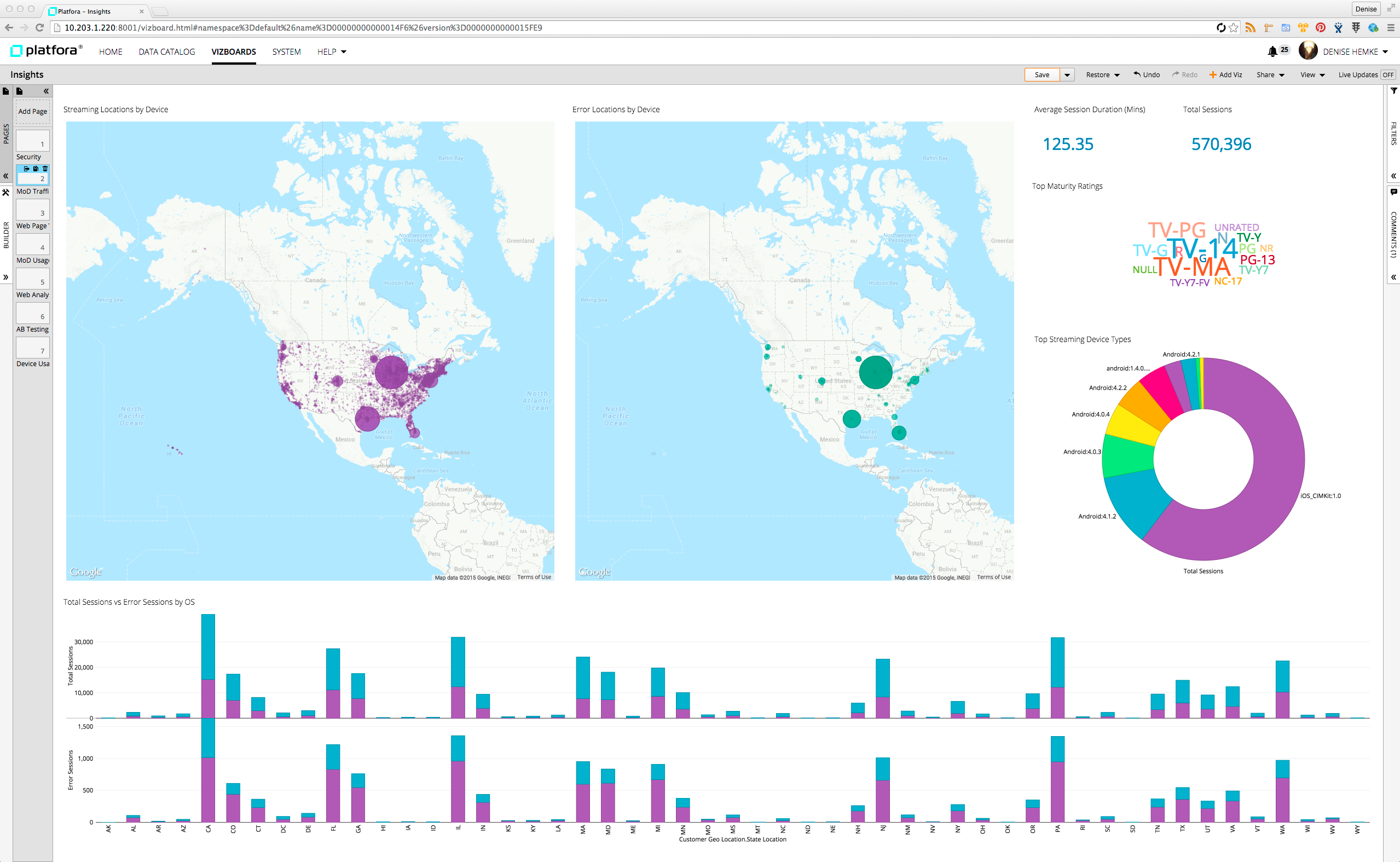
Platfora “vizboards” can now be embedded into any HTML application
Platfora is often used to analyze big data brought into the lake, many customers also want to be able to pull data from their Hadoop data warehouses, so supporting Parquet makes that easier for Platfora customer who have more structured data stored in Impala.
Finally, Platfora is giving customers the capability to embed Big Data Discovery visualizations into any Web applications. This process is completed by allowing cusotmesr to take a “snippet” of HTML code generated by the Platfora tool, and dropping it into any Web page.
This makes it much easier to share the “viz boards” generated by Big Data Discovery insights. The viz boards remain interactive, enabling a range of internal or external users to drill into the data and filter it, but without having to be inside of the Platfora environment proper.
“This is the biggest step we’ve taken to get insights out of Platfora and into other systems,” Schlampp says. “It’s been one of the most highly requested features.” For more info on Big Data Discovery version 5.0, see the vendor’s website at http://www.platfora.com.
Related Items:
Spark Is the Future of Hadoop, Cloudera Says
How to Get a ‘Network Effect’ from Your Big Data Lake
Hadoop ISVs Break Away from MapReduce, Embrace Spark, In-Memory Processing
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
Call & Contact Center Expo
 April 24 - April 25Las Vegas NV United States
April 24 - April 25Las Vegas NV United States -
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States