

September 10, 2015
HP Spins Out Trafodion to Power Transactional Hadoop

The feasibility of running transactional workloads side by side with analytical workloads on Hadoop got a little clearer this summer when Hewlett-Packard spun out Trafodion, a “webscale SQL-on-Hadoop” solution. The new company behind Trafodion, called Esgyn, has a simple yet bold goal: unite analytic and transactional workloads onto a single SQL-loving Hadoop platform.
Transactional and analytical workloads have different characteristics, by definition. Transactional systems are usually heavy on the writes and require strong consistency and availability, while analytic systems are heavier on the reads and don’t require that strict ACID adherence. These differences led companies to run transactional workloads on row-oriented relational databases like Oracle and DB2, while column-oriented databases MPP databases like Teradata and Greenplum powered analytics.
Those old walls are now breaking down thanks to a confluence of trends and a period of rapid technological evolution. While ERP systems continue to chug away as they have for 30 years, the notion of what constitutes a “transaction” is changing before our eyes, and the strict lines separating analytic and transactional workloads are becoming harder and harder to discern. Increasingly, customers want to co-mingle all of their data to reduce the latency involved in decision making and close the loop on operational analytics. This is what SAP wants to do with HANA and what Oracle and IBM are aiming for with their respective databases. And there are similar attempts to do this on Hadoop.
That’s where the folks at Esgyn see themselves operating. The company (whose name is pronounced with a soft “g,” as in “go”) is bullish on the prospects for Trafodion, the open source OLTP database engine for Hadoop that’s currently incubating as an Apache project. HP Labs retooled the software, which was originally a massively parallel processing (MPP) analytic database, to provide full ANSI SQL and ACID capabilities atop HBase, along with a parallel execution engine and a SQL query optimizer. The company sells a version of Trafodion called EsgynDB.![]()
Rohit Jain, the CTO of Esgyn and the main backer of Trafodion while at Hewlett-Packard, recently talked about the prospects for running transactional and operational workloads side by side on Hadoop. “The sweet spot for us is the operational data store,” Jain tells Datanami. “People need that structured data to be co-located [with the semi-structured and unstructured data] to do the analytics.”
Consider the case of an Esgyn prospect in the banking industry. The bank has transactions coming into the core banking system, which stores maybe a day’s worth of data. As the transactions mount, they’re piped over to a separate mainframe system that can comfortably store perhaps a month’s worth of data.
The bank’s users are hitting that core banking system and the mainframe to get daily and end-of month data, Jain says. “But what they really want to have is five to 10 years of transactions available,” Jain says. “If they take an operational data store approach and basically… stream that data onto the Hadoop system with sub-second latency, now you can offer your customers all sorts of capabilities.”
For the bank, the key is the mingling of the structured data (i.e. the transactions) with the unstructured data, which could be the GPS location of an ATM machine, the frequency of pharmacy visits, or monthly statements stored in PDF format. This is a form of operational analytics that falls somewhere between the two traditional camps of transaction processing and analytical workloads.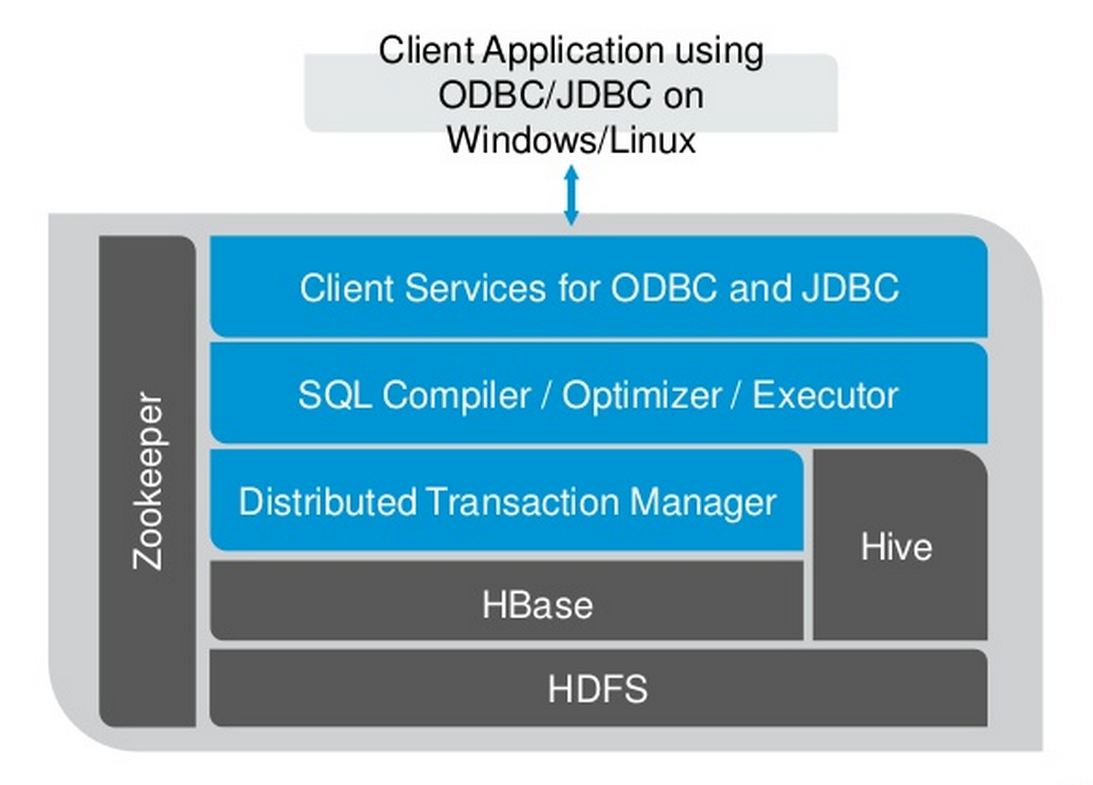
HBase, which is a key-value store built atop HDFS, is very good at operational analytic, such as tracking the status of orders or tracking customer activity. “You’re looking at things from a customer perspective or an order perspective or from a supplier perspective,” he says. “You’re not trying to do huge scans and trying to generate some intelligence against, it like BI and analytics generally tend to do.”
Since Hadoop has become the place where companies store unstructured and semi-structured data, it seems logical to store the structured data that’s need for operational analytics too. “There’s lot of value in being able to integrate all that in one place,” Jain says. “People are looking for a solution where they can integrate those things, rather than have completely separate systems.”
In addition to powering operational analytics, Esgyn eyes the possibility of doing full-on OLTP (online transaction processing) on Hadoop at some point in the future, which is something that Hadoop creator Doug Cutting has talked about before. (The folks at Esgyn were quite happy that Cutting mentioned Trafodion in a recent interview for the British publication Computing.)
“You’re not necessarily going to move your mission-critical applications day one onto this,” Jain says. “But at the same time, that’s exactly what one of our customers has done.” That customer—a telecommunications company–has adopted Trafodion for its eCRM system, he says.
Esgyn, which is Welsh for “soar” (Trafodion is Welsh for “transaction”), offers technical support, services, and training for Trafodion users. The company also plans to offer some closed-source extensions to the core Trafodion product, which it calls EsgynDB.
The company has grown quickly since being founded in early July. It currently has about 50 employees (mostly from HP) thanks largely to a Series A round of funding from 3Z Capital, and the company is looking to grow both of its offices, in Milpitas, California, and Shanghai, China.
Related Items:
HP Throws Trafodion Hat into OLTP Hadoop Ring
OLTP Clearly in Hadoop’s Future, Cutting Says
Applications:
Predictive Analytics
Technologies:
Middleware
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States