

September 9, 2015
Spark Is the Future of Hadoop, Cloudera Says

Apache Spark should be considered the default engine for Hadoop workloads going forward, taking the job that MapReduce held for many years, Cloudera announced today. The Hadoop distributor also announced its “One Platform Initiative” to highlight the investments it’s making in Spark to boost its enterprise capabilities.
The rapid rise of the Spark juggernaut has been a mixed blessing for Cloudera and other Hadoop distributors. On the one hand, the open source technology–which can run up to 100 times faster than MapReduce and lets programmers work in languages like Scala–has been a boon to productivity for its users.
But Spark has also brought a fair bit of confusion about the future of Hadoop–namely how Spark and Hadoop will interact, and what role each will carry in the big data stack of the future. Some analysts have even postulated that Spark could eventually replace Hadoop. But that is clearly not on the agenda for Cloudera, which sees the two technologies co-existing peacefully and complementing each other.
“There’s so much buzz and press about Spark right now,” says Cloudera’s Chief Technologist, Eli Collins. “Unfortunately a lot of it is asking question that are confusing things rather than helping things. What we want to do is be really crisp about what we’re investing in and why.”
The goal of the One Platform Initiative is simple: Close any gaps that exist between Spark and Hadoop, and give Spark the enterprise chops it needs to be the default engine for workloads in Hadoop, thereby taking the mantle from MapReduce, which for years had been the go-to technology for a range of Hadoop frameworks, from Pig to Hive.![]()
“We see Spark as the future of Hadoop,” Collins tells Datanami. “Spark today is an integrated part of the platform but how do you go from making it…one that’s great for specific use cases to being the default engine not just for MapReduce core workloads but also for partner products?”
With its One Platform Initiative, Cloudera will seek to improve Spark in four areas:
- Security – Cloudera is working on bolstering Spark’s security in several key areas, including fine-grained authorization and role-based access controls. That will bring Spark up to par with the security capabilities in Cloudera’s distribution, Collins says. “If Spark doesn’t have support for the same security model you’ve already been using, then it’s hard to use by default,” he says. “We want to bring the full security model we’ve been working on for the rest of the Hadoop ecosystem and get Spark integrated with that.” The work is about 50 percent done, he says.
- Scale – One of Spark’s biggest bugaboos has been scaling to the same vast heights where MapReduce has proven itself, which means breaking the 1,000-node barrier that seems to exist in Cloudera’s customers today, and getting it up to 10,000 nodes or so. “There are definitely bugs at scale,” Collins says. “We saw the same thing with MapReduce.”
- Management – Cloudera will work to ensure that Spark is fully integrated with other management points on the Hadoop platform, including YARN and proprietary tools like Cloudera Manager. “If you are a native Hadoop user today, you want the same kind of quality of experience you’ve had automation metrics, monitoring, access controls and so on,” Collins says.
- Streaming – Bolstering Spark Streaming isn’t so much addressing a weakness than emphasizing what Cloudera sees as a major potential strength, especially as the Internet of Things brings a billion more analytic use cases to our doorsteps. Currently, Spark streaming “is relatively more immature than core Spark,” Collins says.
Cloudera is no Johnny-come-lately when it comes to Spark. In fact, Cloudera makes a solid case that it has been the most adamant supporter of Cloudera among the three pure-play Hadoop distributors, including Hortonworks and MapR Technologies. The company was the first to ship Spark with its Hadoop distribution and the first to offer technical support for Spark.

Cloudera customers who run Spark in production
Cloudera has also been a big investor in Apache Spark, including core Spark and sub-projects like Spark Streaming and MLlib, Spark’s machine learning library. The company employs five Apache Spark committers, Collins says, five times as many as other Hadoop distributors. And Cloudera has contributed over 370 patches and 43,000 lines of code to Spark over the years, which is 90 percent more than other Hadoop distributors, he says. The father of Spark, Matei Zaharia, was Cloudera’s first intern back in 2007. “We’re invested in this far more heavily that other Hadoop vendors and we’re going to increase that investment because we heavily believe in Spark,” Collins says.
The investments will be made in the open, via the relevant Apache projects that govern Spark, Collins says. Cloudera isn’t soliciting anybody to join its One Platform Initiative, which isn’t an organization so much as a statement of Cloudera’s direction.
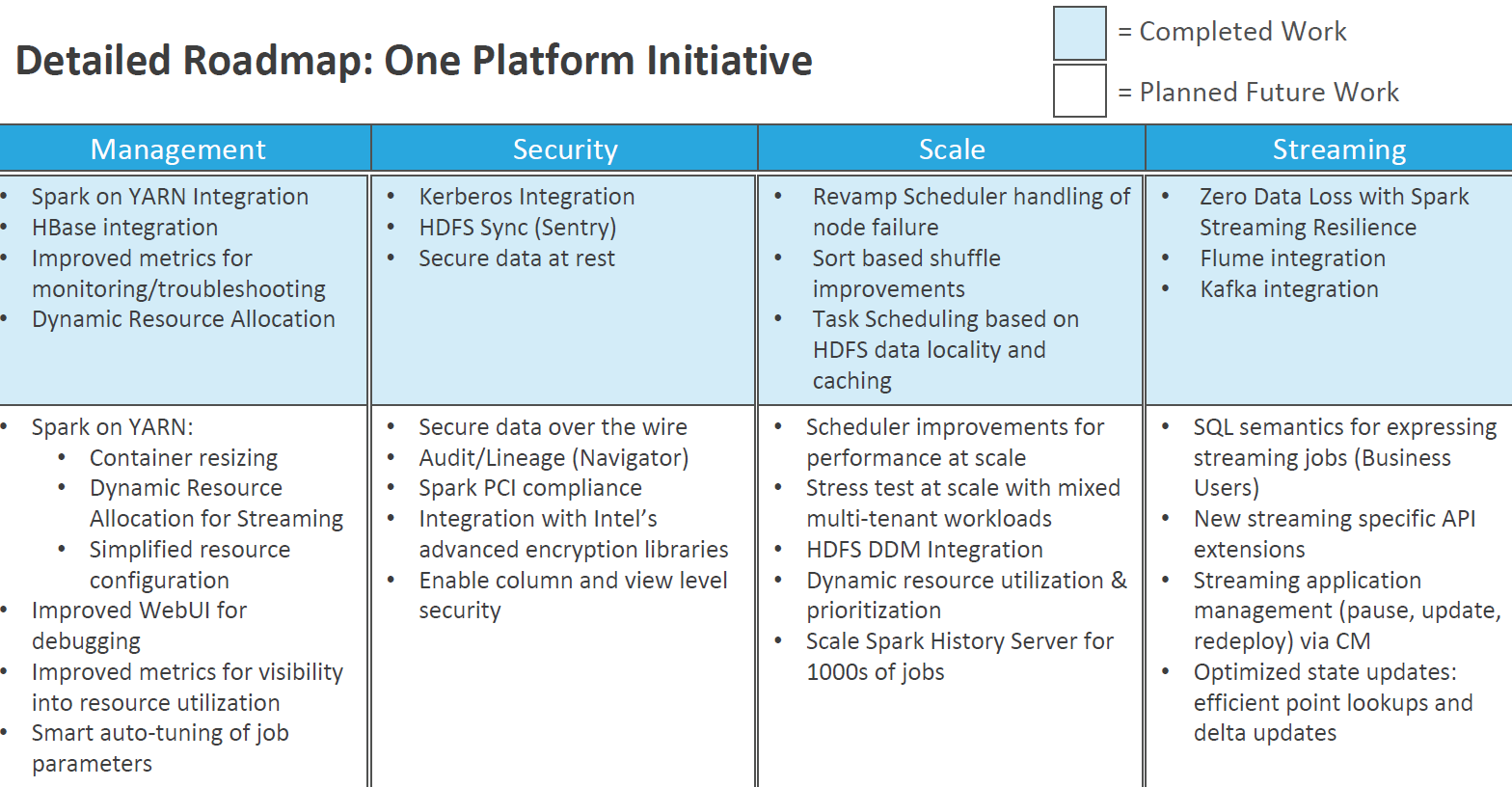
Cloudera provided this detailed roadmap for how it plans to improve Apache Spark
“This is the agenda we’re pushing, but it’s where we’re pushing in the open source project. There’s no government aside from the Apache projects here,” he says, adding that Cloudera employees aren’t “huge fans” of the Open Data Platform (ODP) that rival Hortonworks launched earlier this year. “This is us saying what we think needs to happen. All this work will be contributed in the relevant projects.”
This transition to using Spark as the core engine will take time. Out of 600 paying Cloudera customers, more than 200 of them are using Spark, and 120 are using Spark in production. The company won’t drop MapReduce altogether, but it will look to remove any reasons that customres have for choosing MapReduce for new workloads, and giving them incentives to use Spark, Collins says.
Some see Spark adoption hurting Hadoop. After all, you can run Spark on NoSQL databases like Cassandra, or even on Databrick‘s cloud, without any HDFS or YARN in the mix. But Collins sees Hadoop as a big boat with plenty of room for Darwinist competition among the technological passengers.
“Hadoop is an awesome gateway drug to start using Spark,” Collins says. “The fact that new components come along and compete against each other and replace and augment each other…that’s one of the benefits of the platform.”
Related Items:
Apache Spark Continues to Spread Beyond Hadoop
Hortonworks Hatches a Roadmap to Improve Apache Spark
Apache Spark: 3 Real-World Use Cases
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States