

August 12, 2015
Inside the Zestimate: Data Science at Zillow

If you’re like most homeowners, you probably sneak a peek at your ‘Zestimate’ from time to time to see how your home’s value might have changed. Getting a Zestimate is very easy and straightforward for users, but behind the scenes, there’s a hefty amount of data science that goes into the equation.
The Zestimate is a core part of Zillow’s offering, and is critical for the company’s business model. The figure is an estimated market value that’s based on a number of public and user-submitted data, including physical attributes, like location, lot size, square footage, and number of bedrooms and bathrooms. Historical data like real-estate transfers and tax information is also factored in, as are sales of comparable houses in a neighborhood.
Three times per week, Zillow updates its Zetimate for 110 million homes in the U.S., as well as the Rental Zestimate for 100 million homes. The company has also gone back in time to create historical Zestimates, which help it to track how property values have changed over time and improve the current Zestimate.
The more data Zillow has on a given home, the more accurate the Zestimate, the company says. The Zestimates are usually accurate to within 10 percent in most American metro areas, Zillow claims. Nationally, the median error rate 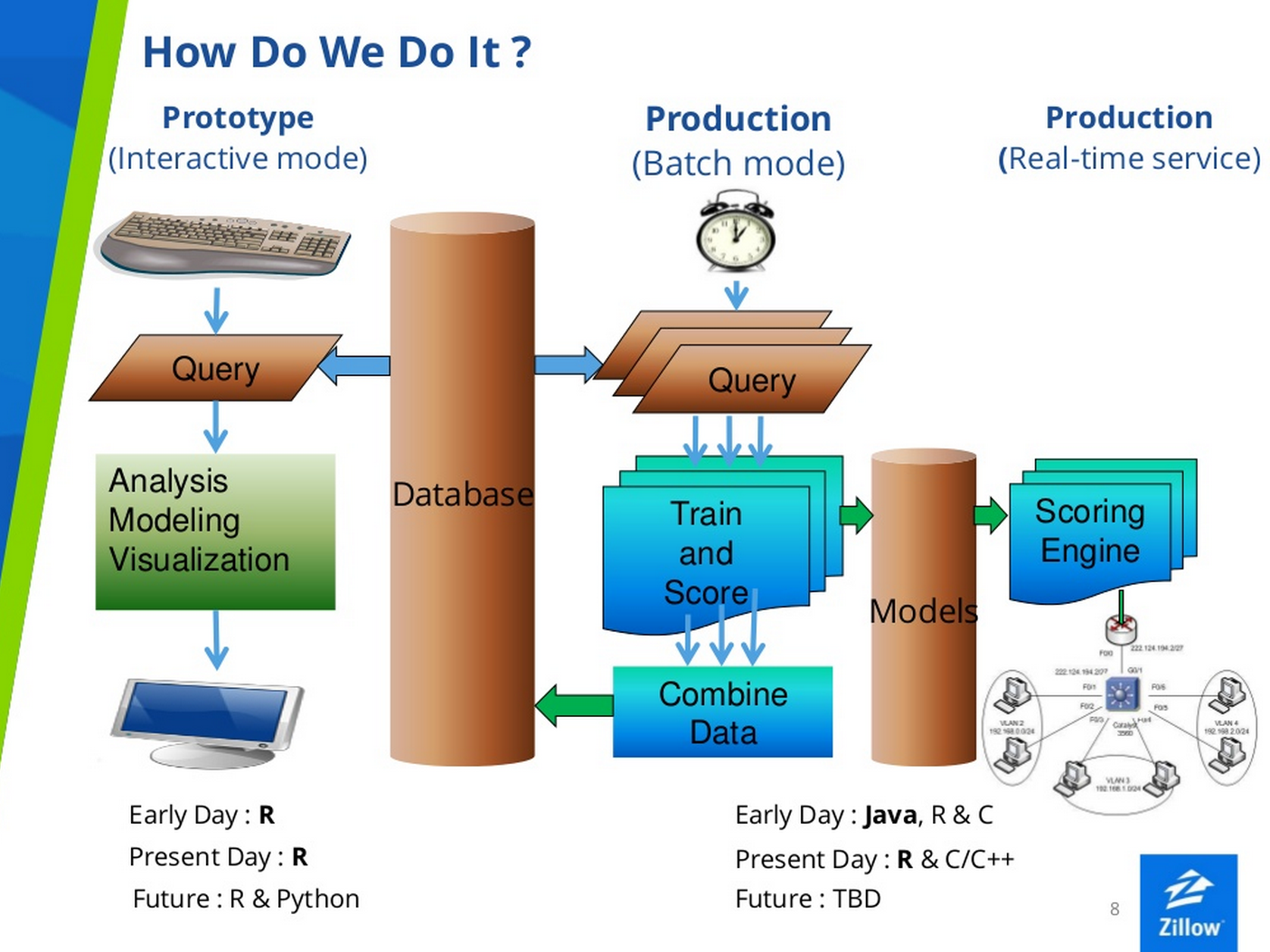 is 8.3 percent, the company says. The company lets homeowners submit additional information that is not available through public sources, such as the existence of remodels or major upgrades.
is 8.3 percent, the company says. The company lets homeowners submit additional information that is not available through public sources, such as the existence of remodels or major upgrades.
How does Zillow handle all these data sources to come up with the Zestimate? Earlier this year, members of Zillow’s data science team shared some of the secrets behind the Zestimate.
Machines Learning About Houses
The data behind the Zestimate is stored in a database that’s 20TB in size, according to this presentation by Zillow’s Senior Data Scientist Nick McClure. The company tracks 103 attributes for each property going back 220 months, and there’s about a two-week time lag in the raw data itself.
The Zestimate is generated through a series of processes built using various tools, including heavy doses of R, Python, Pandas, Scikit Learn, and GraphLab Create, the graph analytics software developed by Seattle-based Dato (formerly GraphLab).
The company makes extensive use of R, including the development of a proprietary software package called ZPL that functions similar to MapReduce on Hadoop, but runs on a relational database. The company is increasing its use of Python, which Zillow data scientists say is better than R for some things, such as conducting GIS analysis.
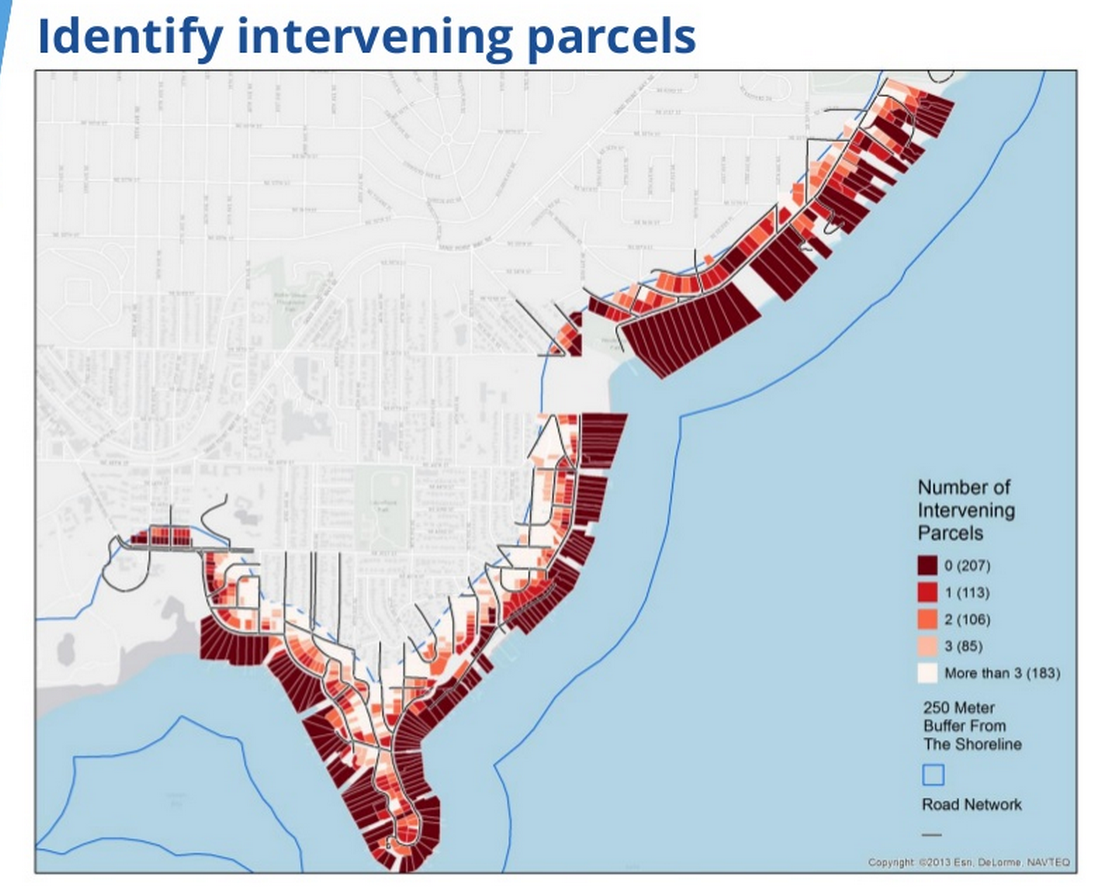
For example, a Zillow GIS analyst, Mike Babb, uses a R and Python to create a GIS model that determine whether a house is a waterfront property. Houses close to the waterfront (within 250 meters) are priced differently than non-waterfront houses, Zillow says. But determinations must be also made regarding proximity and access (i.e it may be close to the water, but there may be other properties or streets between it and the water).
 Zillow is also using machine learning to improve the accuracy of error and fraud detection. Like any popular online resource, Zillow attracts its share of thieves and con-artists. The data science team uses a combination of Scikit Learn, a collection of Python-based data mining and machine learning tools, as well as Dato’s GraphLab Create to flush out bad guys.
Zillow is also using machine learning to improve the accuracy of error and fraud detection. Like any popular online resource, Zillow attracts its share of thieves and con-artists. The data science team uses a combination of Scikit Learn, a collection of Python-based data mining and machine learning tools, as well as Dato’s GraphLab Create to flush out bad guys.
Specifically, Zillow uses a gradient-boosted random forest to match features on known fraudulent listings against new listings. The output from the machine learning algorithm is scored as actual fraud or not, and added back into the fraud model every week.
Now Dato’s fast graph analytic engine is helping with fraud. Previously, it took taken Zillow up to 33 days to run a k-Nearest Neighbors algorithm against a dataset composed of 2 million properties in Los Angeles County, according to a McClure’s presentation.
When McClure brought in GraphLab Create, he could get the same job done in about 20 to 40 minutes. What’s more, the model could run on an eight-core desktop machine, and the accuracy rate was boosted to about 97 percent, up from figures as low as 65 percent.
The company is also using GraphLab Create to track month over month (MOM) changes in Zestimates, with an eye for identifying “problematic Zestimates,” McClure writes in his presentation. “We now have a tool that can slice and dice the Zestimate and look at all of our data by any number of factors,” he writes.
Zillow has since put Dato’s software into production. “I’ve found that Dato deeply understands the needs of the data scientist,” says Andrew Bruce, Senior Director of Data Science at Zillow. “The ease of use and scalable performance, which is not limited by the memory of the machine, are allowing us to innovate and advance at an astonishing pace.”
Related Items:
Dato Aims to Unleash Machine Learning
The 3 Key Steps to Building a Predictive App with Machine Learning
The Rise of Predictive Modeling Factories
Technologies:
Middleware
Sectors:
Retail
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
Call & Contact Center Expo
 April 24 - April 25Las Vegas NV United States
April 24 - April 25Las Vegas NV United States -
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States