

July 9, 2015
Teradata Supports CDH and HDP with New Hadoop Appliance

Teradata today announced that customers can get its Hadoop Appliance pre-loaded with a distribution from either Cloudera or Hortonworks. The fifth generation of the analytics giant’s appliance also features more configuration options, including different types of nodes designed to run different workloads.
Even though Hadoop was designed to run on low-cost, commodity Lintel servers that most IT folks are familiar with, some customers still don’t want to deal with the cost and hassle of procuring their own cluster to get started. And even some customers who are familiar with Hadoop get tired of the IT aspects of managing a cluster, and just want to focus on the data science.
These customers have two options: Move to the cloud or adopt an all-in-one appliance. Interestingly, it appears that customers are adopting both options in equal abundance, according to a study from Enterprise Strategy Group cited by Teradata (see figure 1, which obviously doesn’t take Amazon Elastic MapReduce [EMR] into consideration).
It can be hard to get started with Hadoop, which is why some customers are best served by leaving it to the experts, says Chris Twogood, vice president of product and services marketing for Teradata.
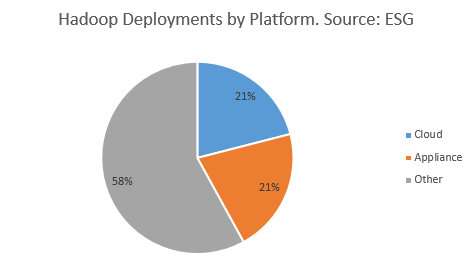
Figure 1
“Not everyone wants a do-it-yourself Hadoop project,” he tells Datanami. “A lot of people in Silicon Valley do. But what we’re seeing is a lot of people don’t want to deal with the technology complexity, where you have to deal with different versions and compatibility of software, deal with optimization between I/O rates off of disk drives into what are the right NIC cards and drives associated to the CPU, and how do you build all this out with complete stack with all the adapters and cabling and infrastructure.”
Building your own Hadoop cluster can take up to six months, according to Twogood, and then you must maintain it, which consumes even more time going forward. By comparison, a Hadoop appliance ships from the factory with a pretested combination of hardware and software, and Teradata will maintain it for you (with level three and four support coming from the distro vendors).
“Now don’t get me wrong–there’s a segment of the market that will always do it themselves,” Twogood continues. “But there’s another segment, from what we’re seeing, that want it to be simpler and want it to be more of a turnkey-type of solution.”
The new Hadoop Appliance that Teradata unveiled today is bigger and more configurable than previous versions. For starters, customers get a choice of Hadoop distributions from Cloudera and Hortonworks. Previously, the company only supported Hortonworks Data Platform (HDP) on the platform, but decided to add Cloudera’s Distribution of Hadoop (CDH) due to customer demand.
The Teradata Appliance for Hadoop ships as a full 42U rack that customers can just drop into their data centers, turn on, and starting storing or processing data. Each appliance supports up to 18 nodes, and customers can string together more than 100 of them to build a cluster with up to 2,048 nodes.
The new appliance that Teradata unveiled today also sports a configurable mix of different data node types, including:
- Capacity Data Nodes, featuring dual 8-core Intel “Haswell” processors, twelve 3.5-inch 4TB SAS drives spinning at 7.5k, and 128GB to 256 GB of memory
- Balanced Data Nodes, featuring dual 12-core Intel “Haswell” processors, twelve 3.5-inch 4TB SAS drives spinning at 7.5k, and 256GB to 512GB of memory;
- And Performance Data Nodes, featuring dual 12-core Haswell processors, twenty-four 2.5-inch 1.2TB drives spinning at 10k, and 256GB to 512GB of memory.
Having different node types helps Hadoop appliance customers run different workloads, Twogood says. “When you put things like Spark or Storm or SQL on Hadoop, you need a node that’s high performance,” he says. “Depending on the workloads your running, this application has a lot of flexibility to meet those needs whiter its performance or capacity or balance.”
Teradata has hundreds of Hadoop Appliance customers, according to Twogood, and the clusters are getting bigger. “For a while we’d see people who were deploying appliance in the 50- to 100- node range. Now we see customers with greater than 100 nodes saying I want to look at an appliance,” he says.
 Teradata has other features up its sleeve that other Hadoop appliance vendors don’t: advanced connectivity with other analytic environments via InfiniBand connections.
Teradata has other features up its sleeve that other Hadoop appliance vendors don’t: advanced connectivity with other analytic environments via InfiniBand connections.
“We have pre-built integration into the UDA [Unified Data Architecture] so with the InfiniBand fabric backbone, you can plug Hadoop nodes in that fabric, as well as Teradata and Aster nodes and then our QueryGrid software technology does the high-speed dynamic integration of queries at runtime across that foundation,” Twogood says.
While most Hadoop implementations are done in Ethernet, Teradata sees enough demand for the higher bandwidth that InfiniBand offers to make it a standard part of the offering (although customers can get regular 10Gbe if they want). “We find that it’s not overkill for a couple reasons,” Twogood says. “A lot of the customer we deploy into are going to connect Hadoop into the broader ecosystem, meaning they’re going to connect it to Teradata or Aster box. The 40Gb network provides that high-speed interconnect so you get really good performance.”
The company also offers a Hadoop-native archive and query product that it acquired recently from RainStor, and which also plugs into the UDA and QueryGrid scheme of things. It also offers Loom, which handles metadata management for Hadoop, and can bring it all together with services from its ThinkBig Analytics acquisition.
Another product that’s getting the UDA treatment is the Hadoop distribution from MapR Technologies, with whom Teradata announced a partnership in late 2014. There’s no word yet on if, or when, the MapR distro will be offered on the appliance.
Cloudera is eager to partner with Teradata to tackle the growing market for Hadoop appliances. According to Clarke Patterson, senior director of product marketing for Cloudera, there are some customers that are predisposed to taking the appliance route.
“Admittedly, it’s new technology, it’s 7 years old, some things can be complicated depending on what you’re trying to do,” he tells Datanami. “In an engineered system, a lot of the deployment configuration, and everything else is already taken care of. So the appliance gives them that alternative to really get them up and running and have an impact very fast.”
Bringing Cloudera in also ensures a more diverse array of technologies available to Teradata customers, such as support for Apache Kafka, the distributed messaging system that is poised to explode as real-time analytics and the Internet of Things go mainstream.
“Kafka is one we do have in 5.4 distribution. Spark as well,” Cloudera’s Patterson says. “Storm we don’t support. You will find it in the Hortonworks distribution. It’s essentially an alternative of sorts to the stuff we’re doing in Spark. We have identified Spark as the one area we’re moving forward with. That’s where the difference between the distributions start to come in.”
Teradata’s fifth-gen appliances will ship later this quarter, and start at $75,000 for a 100TB configuration. That may sound steep, but it pays off in the long run, Twogood says. “The initial price is higher but as you add in other costs, your TCO [total cost of ownership] over three to five years is lower.”
Related Items:
The Real-Time Future of Data According to Jay Kreps
Teradata Bets Big on Presto for Hadoop SQL
Teradata Has Hadoop Covered with MapR Partnership
Tags:
appliance, big data, CDH, cloudera, engineered systems, Hadoop, hdp, Hortonworks, mapr, querygrid, Teradata, Unified Data Architecture
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
Call & Contact Center Expo
 April 24 - April 25Las Vegas NV United States
April 24 - April 25Las Vegas NV United States -
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States