

June 24, 2015
How Apache Spark Is Helping IT Asset Management

There’s been a lot of energy focused on how big data technology can improve the sales, marketing, service, and support departments of corporations. Tools like Hadoop, Spark, and NoSQL databases are changing the rules for how work gets done, and it’s very exciting. But big data tech is slowly creeping into the IT department itself, which might need it most of all.
While the typical IT department may be familiar with big data concepts and technologies, they’re typically working with it in support of other department. But as it turns out, the $2-trillion IT industry suffers from some of the same sorts of problems—such as the existence of individual data silos, data inconsistencies, and lack of integration—that big data technology is helping to solve in other departments.
One vendor at the forefront of using big data technology in the IT department is Blazent, which develops “data intelligence” offerings used by large IT departments and IT service providers to get a handle on the myriad of different software, hardware, and networking assets that companies rely on. The company developed what essentially is a configuration management database (CMDB) that helps IT departments standardize data so they can make good decisions. Some of Blazent’s customers in the financial services industry can lose up to $60 million per minute if core IT services suffer an outage.
According to Blazent CEO Gary Oliver, it’s not uncommon to find IT officers basing critical business decisions on data that is simply wrong.

Blazent’s five-step data evolution process
“It’s absolutely amazing that, while all these organizations spend millions of dollars on very specific toolsets to do very specific things in IT–whether that’s security or antivirus or asset management or service management or financial management–when it comes to making those key decision across the top, we find they’re up to 40 percent off on their data,” Oliver tells Datanami.
Every large enterprise has multiple systems, and those systems operate largely independently as their own “buckets” of data, he says. “We bring data together that’s never been brought together before to provide that complete context for decision making across IT, whether that’s around risk management or service management or financial management or operational excellence or billing,” he says.
When the Silicon Valley company was created 12 years ago, it designed its software around the three-tiered architecture that was cutting edge at the time. The company’s intellectual property was implemented in an Oracle-based system that could harmonize and rationalize the different data that IT departments needed. Keeping the data consistent and correct across these various systems required extensive ETL processes running around the clock.
Fast forward to 2015, and Blazent’s old three-tiered architecture is simply not able to keep up with the data volumes that its 70-plus customers are starting to throw at it, says Michael Ludwig, Blazent’s chief product architect.
“To be honest, we reached the vertical scalability of the solution we were running it on,” Ludwig says. “Any given attribute for any given entity might require 100 or more transforms and a bunch of I/O operations….The only way to bring it forward, especially to handle the explosion of data that’s occurring, was to move to a cluster-based system.”
Today Blazent announced that new system, dubbed the Blazent Data Intelligence Platform. Based on a combination of Hadoop, Spark, and NoSQL data stores Cassandra and Redis, the new platform will allow Blazent’s customers to move from batch-oriented data rationalization processes closer to a real-time process.
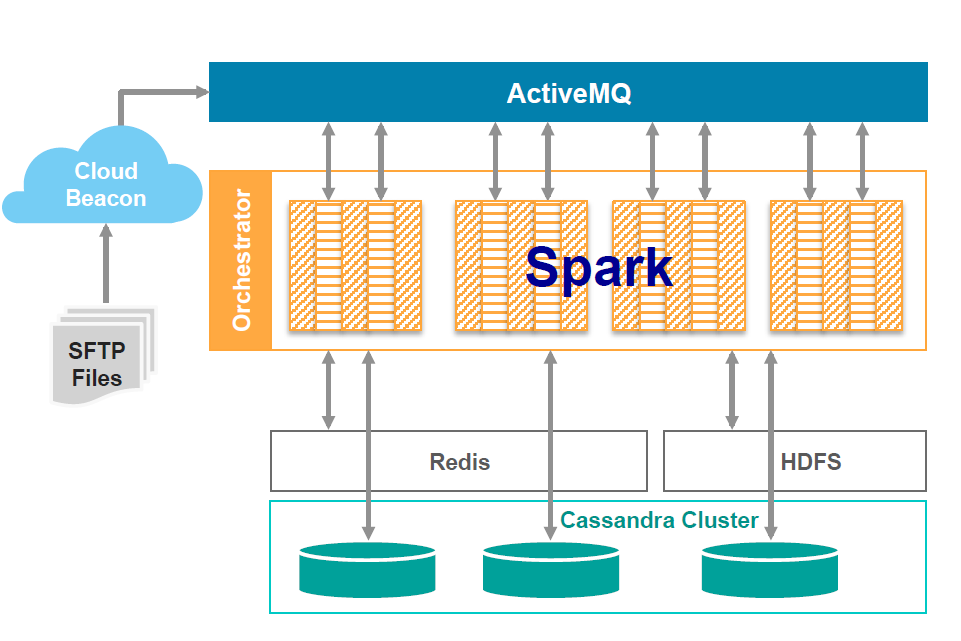
The Blazent data engine’s new architecture
According to Ludwig, it was taking some of Blazent’s largest customers upwards of 35 hours to complete the ETL process against data sets topping 31 million records. With the new clustered solution, those 31 million records can be normalized in just 17 minutes.
“We’re hearing from clients that analytics need to be as near-time as possible,” he says. “We have a very sophisticated canonical flow that’s operating here, and Spark is the key to it. Even if we tried to do utilize a big data stack with MapReduce, for example, we would not be able to achieve the speed that’s necessary for the way we see the analytics developing.”
The new system offers pre-built interfaces to more than 230 discrete data sources, including IT service management (ITSM) systems like ServiceNow; procurement, billing, and operational tool stacks; and “shadow IT” sources like spreadsheets. “Poor IT data quality is the reason that 40 percent of all IT projects fail to achieve targeted benefits, and 30 percent of servers are underutilized and in many cases not backed up or secure–leaving organizations challenged in managing risk, providing effective operations, and controlling costs.”
In addition to the new Hadoop- and NoSQL-based platform, the company is launching two new analytic solutions that sit atop the platform, including Data Explorer and GLOVE. Data Explorer will provide dashboards and reporting tools, while GLOVE (which stands for governance, lifecycle operational validation, expenditure) will offer higher level analytics for IT service providers.
Later this year, the company will launch predictive and prescriptive analytics that take advantage of machine learning algorithms.
Related Items:
Forget the Algorithms and Start Cleaning Your Data
Beyond Big Data: Addressing the Challenge of Big Applications
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States