

June 11, 2015
Hortonworks Tightens Up Its Distro for Enterprise Adoption

Hortonworks unveiled the first new release of its Hadoop distribution in six months earlier this week. With Hortonworks Data Platform (HDP) 2.3, the company is focusing on strengthening security, governance, and operations, and just generally making Hadoop easier and more visual to use.
A lot has transpired since Hortonworks shipped HDP 2.2 last December, including the company’s IPO in December, the formation of the controversial Open Data Platform (ODP) industry consortium in February, the opening of a new headquarters in Santa Clara, California, the creation of the Data Governance Initiative (DGI), the acquisition of Sequence IQ, and a continued hiring binge.
The Hadoop distributor closed 105 new customer deals for HDP 2.2 in the first quarter, which was six more than it logged in the fourth quarter of 2014, giving it roughly 400 paying HDP customers at the close of the first quarter (most of which are running HDP 2.1 or 2.2). If you know anything about enterprise software, closing more deals in Q1 than Q4 is quite a feat, and it’s a strong indication of not just of how hot Hadoop is five-and-a-half months into 2015, but how well Hortonworks is executing in product development and support.
Instead of adding major new data analytic features–which the additions of Apache Storm and Apache Spark in HDP 2.2 last year arguably provided–the company instead devoted HDP 2.3 mostly to improving existing products and projects and making Hadoop align more closely with enterprise requirements, with some exceptions.
Hortonworks co-founder and architect Arun Murthy said the enhancements in HDP 2.3 are all about making Hadoop easier to use.
“The easier we make it, the more use cases come onto Hadoop, and people see more value out of Hadoop,” he said. “Right now a lot of focus is not technology for technology’s sake. It’s about how to get end-to-end use cases deployed, managed, and operated on in an easy fashion. It’s not just about Hadoop or Hive or Spark. It’s about how can we put it all together so that it can solve easily and operationally solve business use cases.”
When Murthy got started in Hadoop 10 years ago, there were two components: HDFS and MapReduce. Today’s HDP ships about 25 different components, and keeping all of those in synch and integrated can be a challenge.
“In some way we have too many technologies,” he told Datanami this week at Hadoop Summit, which was hosted by Hortonworks and Yahoo. “The more technologies you put in, you create all these end-to end connections.”
The company says it added more than 100 new features with HDP 2.3, which is about the same number that it delivered in HDP 2.2. Here are the highlights of the latest release:
- Apache Hadoop 2.7.x – When it ships, HDP 2.3 will include some version of Hadoop 2.7.x (but not 2.7.0, which is unstable). Major features include support for rolling upgrades, support for SSD and memory tiers, and better encryption.
- Apache Ambari 1.7 — The operations console for HDP is much more “guided” and “opinionated” than it used to be and comes with pre-build configurations for HDFS, YARN, HBase, and Hive. The company has also fleshed out the Ambari Views Framework, which it launched with HDP 2.2 (but without any views). The dashboards functionality has also been improved.
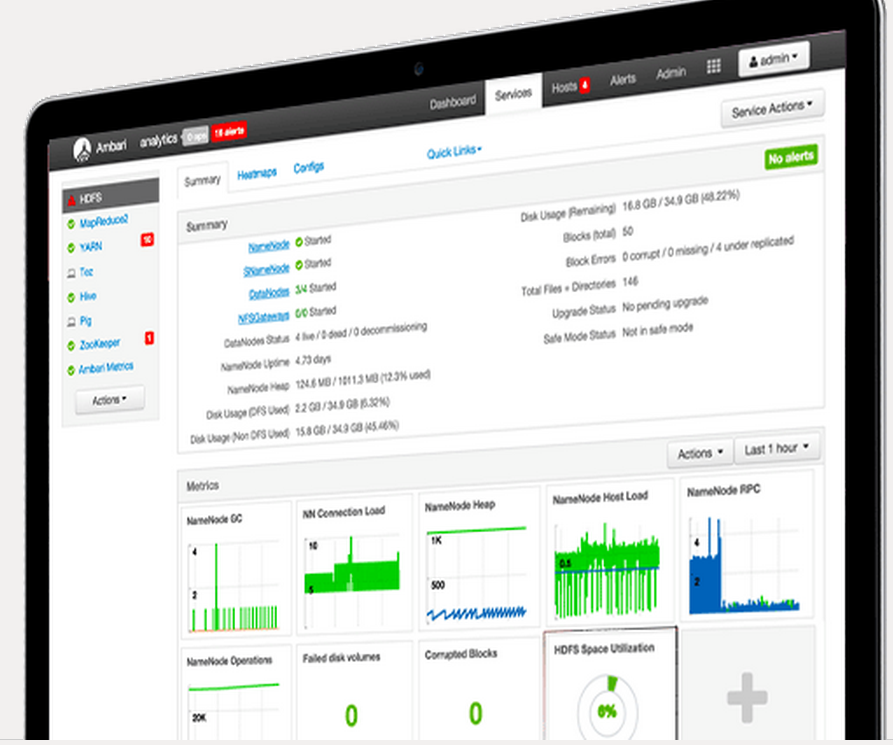
Ambari is much more visual with HDP 2.3
- Apache Falcon UI – Configuring the data governance engine previously required advanced XML handiwork. But the version of Falcon that ships with HDP 2.3 brings a graphical interface to the experience.
- YARN Capacity Scheduler – Like Falcon, using the YARN Capacity scheduler previously required fiddling with XML documents. Now, the scheduler (which allows the Hadoop operator to define minimum capacity guarantees) should be much easier to use thanks to a new Web interface.
- Hive SQL Builder – The new editor makes developing SQL queries in Hive easier, queries
- Pig Latin Editor – Hortonworks say the new Pig Latin Editor brings a “modern browser-based IDE experience” to the Pig scripting environment.
- HDFS File Browser – The new file browser gives developers a way to peruse the file system in a visual manner.
- Apache Atlas – The addition of Atlas counts as a major net-new capability in HDP 2.3. Atlas, which stems from the company’s Data Governance Initiative launched in January, is designed to help users get a handle on their data cleanliness and organization with lightweight master data management (MDM) capabilities.
- Solr on YARN – Hortonworks is providing a tech preview of the Solr search engine running on YARN (via Slider, thanks to Lucidworks) Despite the growing popularity of predictive analytics and advanced machine learning algorithms, sometimes you can’t beat a good old search engine for doing what you need to do.
- Spark 1.3 – The latest release of Spark gives HDP users access to compelling functionality, such as new machine learning algorithms and the DataFrame API.
- High Availability configurations – Apache Storm, Apache Ranger, and Apache Falcon can now run in a high availability configuration on HDP 2.3.
- SmartSense – Not a product feature per se, but a new feature of an HDP support agreement. With SmartSense, HDP phones home data about product usage to Hortonworks, which aggregates it and looks for patterns (using Hadoop, of course) that it will use to improve its products in the future.
Instead of adding more technology and capabilities, Hortonworks appears to be trying to solidify what it already has and make it ready for enterprise adoption. Hadoop has evolved into a powerful platform, but enterprises are still wary of issues like security, governance, and more automated operations. HDP 2.3 is aimed squarely at addressing some of those concerns.
For more info, see Hortonworks’ blog post about HDP 2.3.
Related Items:
Taming the Wild Side of Hadoop Data
Hadoop Opportunity ‘Never Been Bigger’ Says Hortonworks CEO
Hortonworks Files for IPO, Will Trade Under ‘HDP’
Technologies:
Middleware
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
Call & Contact Center Expo
 April 24 - April 25Las Vegas NV United States
April 24 - April 25Las Vegas NV United States -
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States