

April 15, 2015
The Big Data Behind Shell’s Super-Efficient Car Races

Most Americans are interested in the fuel efficiency of automobiles these days, a byproduct of higher gas prices and the growing acceptance of manmade climate change. But for the students who participated in last weekend’s Shell Eco-marathon in Detroit, getting 100 miles per gallon–or even 1,000 MPG–may not be enough to win.
More than 1,000 high school and college students from the U.S. Canada, Mexico, Brazil, and Guatemala descended upon the Motor City last weekend to put their fuel-efficient creations to the test. The students designed and built more than 110 cars running on seven types of fuel, and raced them in two main categories: Prototypes, or hyper-efficient cars of the future, and more practical cars in the UrbanConcept division.
Two cars in the Prototype division delivered fuel-efficiency in excess of 3,000 miles per gallon during last week’s race, according to Shell’s race results page. (While that is commendable, it’s less than half the efficiency that some European teams have demonstrated in last year’s Shell Eco-marathon in The Netherlands.)
The winner in the UrbanConcept division, meanwhile, could go 450 miles on a gallon of gasoline. Similar results were posted in other fuel categories, including diesel, ethanol, hydrogen, CNG, GTL (or gas-to-liquid) and electric batteries. While each car must maintain a minimum speed of 15 miles per hour over the 10-mile course, speed was not the goal of the race.
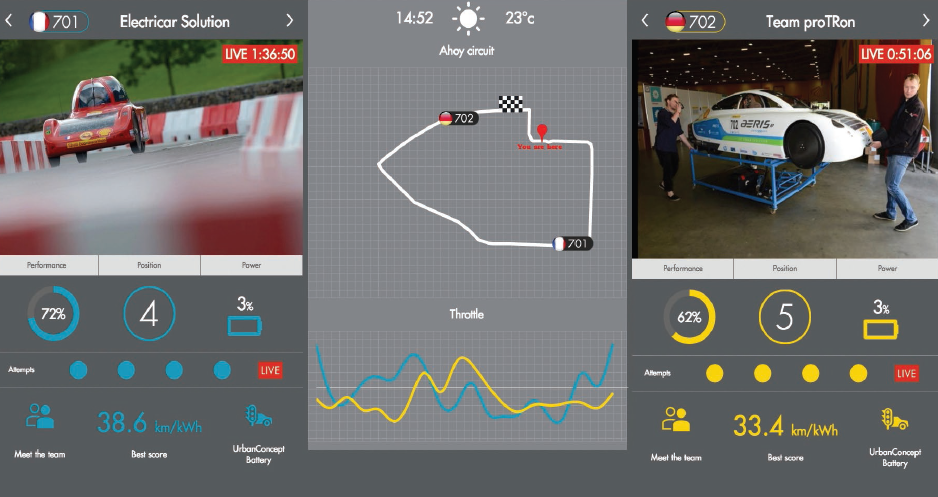
Screenshot of big data dashboard HP built for Shell’s Eco-marathon races
Keeping all the race-related data straight is no easy task. In fact, one could make the case that it qualifies for the “big data” treatment. For Shell’s IT partner in the Eco-marathon series, Hewlett-Packard, the challenge called for the use of its HAVEn big data platform.
HP used its Vertica data warehouse component of HAVEn to store and process the structured telemetry data coming from the cars, such as speed, throttle position, fuel-consumption, number of laps and attempts, and power generated by the engine or motor.
It also used the HP Analytics and Data Management Services offerings in this deployment. Meanwhile, the HP Explore product was used to provide social media sentiment analysis in real-time. The visual analytics platform uses IDOL (Intelligent Data Operating Layer) technology HP obtained with its Autonomy acquisition to index data arriving from hundreds of distinct repositories and data sources, ranging from Twitter and Microsoft Exchange to SQL.
Finally, HP Cloud platform hosted the whole setup, which took eight weeks to prepare. Norman Koch, technical director for the Shell Eco-marathon, says HP’s technology was instrumental in running the Shell Eco-marathon.
“A lot of data is generated by testing and live track performance and we wanted to open it up so everyone could feel part of the event,” Koch said following last year’s Shell Eco-marathon in Rotterdam. “There are up to 200 teams at each event and 30 on the track at any given moment. Before they qualify to race, teams must pass a 10-step ‘scrutineering’ stage, with over 100 technical details on the check-list. We create a large amount of data, and teams and supporters are hungry to see this.”![]()
To be sure, the students handled and manipulated a lot of data themselves as they designed, built, and tested their fuel-efficient cars. And while professional racecar teams may have a lot more data and computing power available to them to continuously tweak their motors, suspension systems, and bodies, helping Shell to execute and promote the its Eco-marathon gets us one step closer to reaching society’s fuel-efficiency goals.
Related Items:
Data Driving Formula 1 Racing to New Heights
HP Leverages Acquisitions, Firms Up Big Data Approach
Sectors:
Other
Vendors:
Hewlett-Packard
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States