

April 7, 2015
AtScale Claims to Mask Hadoop Complexity for OLAP-Style BI

AtScale came out of stealth mode today with new software designed to trick business intelligence tools into thinking that Hadoop is a standard database upon which they can perform OLAP-style analysis, as opposed to the huge distributed file system that it really is.
Business intelligence tools like Tableau, Qlik, TIBCO Spotfire, and Microstrategy weren’t designed with Hadoop in mind, but they’re commonly used to analyze data stored in HDFS just the same. In response to this demand, the Hadoop community and distributors like Cloudera and Hortonworks are funneling a massive amount of time and money into improving the performance of the SQL query engines that feed those BI tools, via enhancements to Hive, Impala, Spark SQL, among other SQL-on-Hadoop projects.
While this focus on SQL-on-Hadoop performance has yielded real improvements, there’s still a sizable gap between the expectations of the BI tool users and what the BI tools can actually deliver when running on Hadoop, according to the folks at AtScale and many other experts familiar with SQL-on-Hadoop.
The problem today, AtScale says, is that users must make tradeoffs when using BI tools and BI concepts in the Hadoop world. The first tradeoff is that users typically must move the data, via standard ETL processes, out of HDFS and into the RAM of a data mart in order to analyze the data. This is anathema to the Hadoop approach, which holds that you should neither have to move nor sample your data.
The second tradeoff, AtScale says, involves the data transformation stage. To get the data into a shape that BI tools can query typically requires developers with advanced skills, perhaps even data scientists themselves. The problem is, these skills are not readily available in most organizations, where business users skilled in Tableau and your average Excel junkie are making business decisions.
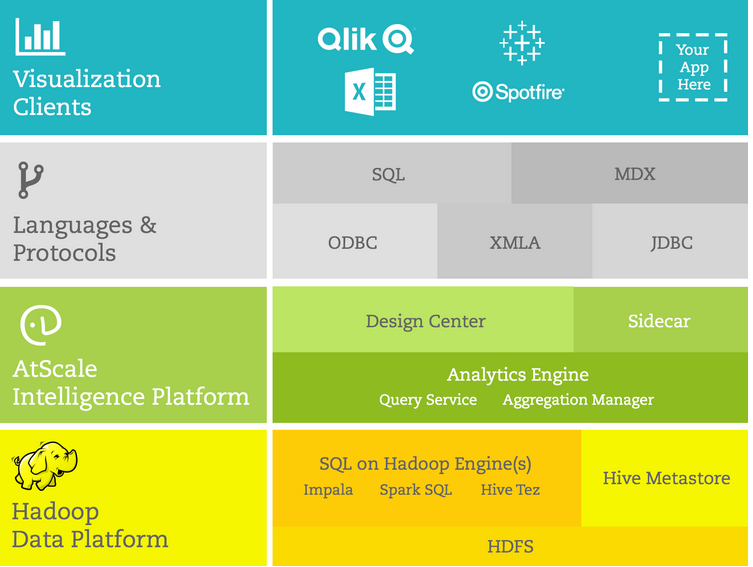 AtScale says it addresses these challenges by making Hadoop appear to be just another standard data mart that average data analysts can now query, without sampling or moving the data, and without involving IT or embarking on a unicorn hunt.
AtScale says it addresses these challenges by making Hadoop appear to be just another standard data mart that average data analysts can now query, without sampling or moving the data, and without involving IT or embarking on a unicorn hunt.
At a high level, AtScale does this by emulating the well-understood OLAP approach that dominated the BI world before words like “big data” and “Hadoop” entered the lexicon. In OLAP, analysts painstakingly arranged the data they wanted to analyze into multiple dimensions (perhaps a dozen or more, including the all-important time-series data) that could be queried later. This allowed analysts to get different views on the data to tease out trends, but the OLAP “cubes” could be temperamental and difficult to manage.
AtScale borrows from this approach with its product, the AtScale Intelligence Platform, which installs directly on Hadoop and sits between the SQL layer on Hadoop and the BI tool. Instead ETL-ing the data out of Hadoop, as would normally be the case with Tableau or other tools, AtScale creates pre-generated aggregates of the data that the BI tool can access directly. Queries against these aggregates, or pre-defined tables, typically return results in less than a second, AtScale says.
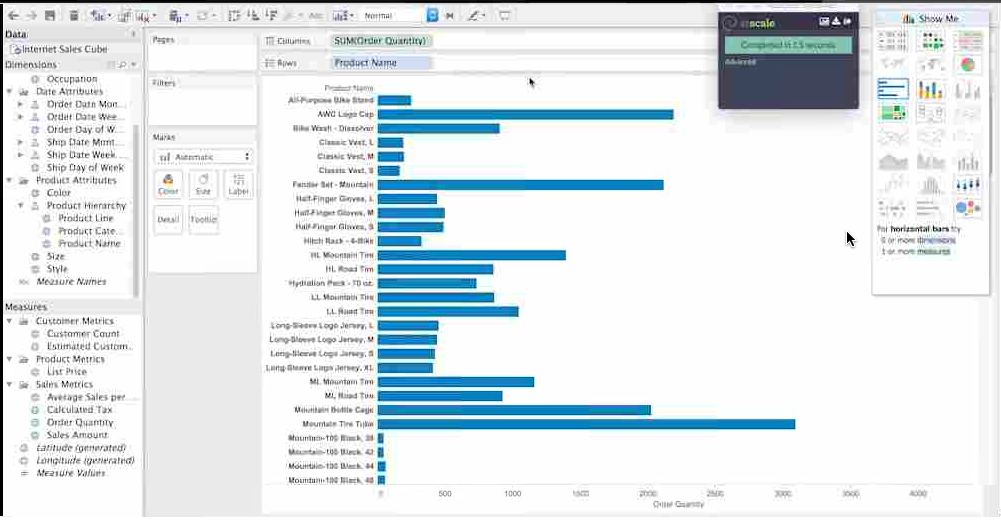
Users tell AtScale what types of data they want to analyze in the Design Center
The trade-off to using AtScale is that users must tell the tool what aggregates to generate. They do that using the Design Center component of the AtScale Intelligence Platform, which the company describes as a “semantic layer” for modeling data. After the users has told the tool what data they want to query using the Design Center, the AtScale Aggregation Engine automatically generates the aggregates, which it does by generating YARN-compatible MapReduce 2 routines (yes, dear reader, MapReduce is alive and well).
(By the way, while these aggregates function similarly to the fact tables of dimensions and measures that OLAP users are accustomed to using, they’re not actually OLAP cubes–the company uses the term OLAP for comparison purposes only.)
AtScale will work with any SQL-on-Hadoop engine on any Hadoop distribution, and its aggregates can be accessed by any BI or visualization tool using protocols like ODBC/JDBC to MDX and XML.
AtScale was founded two years ago by David Mariani, who worked on Yahoo‘s engineering team when it created Hadoop. “We started AtScale not just to make Hadoop work for business intelligence, but to put an end to the compromises we have come to accept,” AtScale CEO Mariani says in a recent blog post. “Why do we need to choose what data is worthy for analysis? Why do we need to structure our data for the questions we have today?…. At AtScale, we built the world’s only business intelligence platform that turns Hadoop’s ‘schema on read’ abilities into a truly dynamic, real-time OLAP cube.”
The San Mateo, California-based company is now selling it software. The company has already inked partnerships with all three independent Hadoop distributors, Spark backer Databricks, and the BI vendors. It already has several customers, including EBay and Yellow Pages.
Related Items:
Tableau Aims to Speed Analytics with V9
Does Hadoop Need a Reality Check?
Wanted: Intelligent Middleware That Simplifies Big Data Analytics
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
Call & Contact Center Expo
 April 24 - April 25Las Vegas NV United States
April 24 - April 25Las Vegas NV United States -
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States