

March 10, 2015
FPGA System Smokes Spark on Streaming Analytics

Technologists with decades of experience building field-programmable gate array (FPGA) systems for the federal government today unveiled a commercial FPGA offering it claims holds 100x performance advantage over Apache Spark for specific streaming analytic jobs.
By all appearances, the Ryft One looks like just another general-purpose X86 Linux server. Indeed, the 1U device sports an Ubuntu OS and Intel processor, largely for purposes of familiarity. But as you dig beyond that generic façade and into its more exotic innards, you’ll see it packs a serious punch, thanks to a hefty serving of FPGAs, twin parallel server backplanes, up to 48 TB of SSD-based storage, and custom software primitives designed to tackle specific analytic workloads.
“Think of it as a Linux server that everybody knows and understands,” says Bill Dentinger, vice president of products for Ryft, “but it acts as a high performance computer.”
A 1U Super?
Ryft developed the FPGA-based system to handle specific analytic workloads against historical and streaming data. The system currently does only three things—exact search, fuzzy search, and count frequency (the equivalent of Word Count in Hadoop and Spark parlance) to be exact. But it does them extremely fast, says Pat McGarry, vice president of engineering for Ryft.
 “Unlike most of the Spark and Hadoop clusters, which are based almost entirely on X86, we have only a single X86 processor in the box and that runs on that Linux front-end,” McGarry says. “Everything else is our hardware parallel platform, and that’s built with FPGA technology. What we’ve done is abstracted that entirely away so the end user thinks they’re running on a standard Linux X86 box, but it’s anything but in the end.”
“Unlike most of the Spark and Hadoop clusters, which are based almost entirely on X86, we have only a single X86 processor in the box and that runs on that Linux front-end,” McGarry says. “Everything else is our hardware parallel platform, and that’s built with FPGA technology. What we’ve done is abstracted that entirely away so the end user thinks they’re running on a standard Linux X86 box, but it’s anything but in the end.”
Ryft is targeting the FPGA machine at customers who need real-time insights from both streaming and historical data sets, using both structured and unstructured data, Dentinger says. The Ryft One excels at workloads where the velocity of the data is higher than the ingest rate of the analytic system, or where the data changes more rapidly than the indexes can be changed.
“In many cases, data has a short half-life. It’s only relevant for a short period of time and thus rapid decisions are needed before the data becomes stale,” Dentinger says. “So a lot of pre-processing to get to the decision is very difficult to support in many of these environments.
Breaking Von Neumann
McGarry describes Ryft One as a systolic array that transcends the boundaries posed by traditional Von Neumann architectures.
“Basically with any sequential architecture, your constrained by the amount of RAM you have, you’re constrained by the I/O in and out of that processor to get the data to the compute elements,” he tells Datanami. “We eliminate that in that with our balanced architecture. With the FPGA fabric, instead of having general-purpose silicon gates, we put in that fabric exactly what we need to solve particular analytics problems.”
 The Ryft One, interestingly, features very little RAM, which aren’t necessary using this architecture. The device features about a million programmable gates, and uses FPGAs manufactured by Xilinx. McGarry says the Xilinix FPGAs offer a superior partition reconfiguration fabric, which allows Ryft to switch between the primitive functions (the algorithms) within milliseconds or nanoseconds.
The Ryft One, interestingly, features very little RAM, which aren’t necessary using this architecture. The device features about a million programmable gates, and uses FPGAs manufactured by Xilinx. McGarry says the Xilinix FPGAs offer a superior partition reconfiguration fabric, which allows Ryft to switch between the primitive functions (the algorithms) within milliseconds or nanoseconds.
“Internally, in FPGA speak, we call that making sure we don’t stall the pipeline,” he says. “As soon as you stall a pipeline in FPGA fabric, you lose performance. If you can make sure your pipelines don’t stall, you can get great performance.”
The Ryft One ingests data via dual 10Gb Ethernet cards (potentially upgradeable to 40GbE or Infiniband). Once the data is in the box, a unique dual backplane that uses PCIIE and Serial RapidIO (SRIO) technologies keeps the FGPAs saturated. The Intel processor is mainly used to provide that familiar face to the outward world.
Speed is the name of the game here. “It can simultaneously operate on the full bandwidth of 48 TB of storage locally and the 10Gb Ethernet links to analyze data at speeds up to and exceeding 10GB per second,” McGarry says. “Ten gigabytes per second can be literally hundreds of servers you can replace for certain applications.”
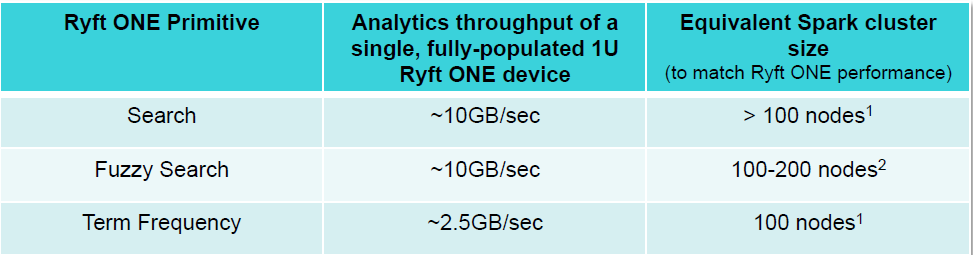
Ryft compares the performance of its primitives against Spark
The company tested the Ryft One against publically available Wikipedia data. On any given day, the additions and changes made to the online encyclopedia account for 45 GB of uncompressed text, McGarry says.
“At 10 GB per second, I can process that with this Ryft One box in just 4.5 seconds. If it changes 5 minutes from now, it takes another 4.5 seconds and I’ve completely analyzed it,” McGarry says. “It’s not indexing. And what’s why we’re really excited about this, because those numbers are unheard of. To match that with an equivalent Spark cluster, if you’re doing a fuzzy search, you’d need about 200 quad-core X86 boxes. That’s close to three racks full of servers, plus top of rack switches, networking, and all the power, compared to our little tiny 1 U pizza box that takes less power than a hair dryer.”
Hadoops Are Hammers, FPGAs Are Screwdrivers
FPGAs were originally developed by the military to process data at speeds that were not possible using traditional ASIC technologies. Today, they’re used in everything from aerospace and telecommunications equipment to automobiles and supercomputers.
The folks at Ryft have more than a decade of experience building FGPAs for federal clients in the Washington D.C. area. With the Ryft One, it’s building on the “blank slate” that FPGAs provide to solve problems emerging with big and fast data workloads.
As McGarry sees it, the problem with traditional analytic systems, such as Spark and Hadoop, is they either don’t work well on large amounts of fast-moving data or they encounter resource bottlenecks as a result of their architecture.
“Hadoop and Spark have become the hammers that people have, and all the problems they see are nails,” he says. “By no means are we trying to supplant the world of Hadoop and Spark. We realize there’s value there. But there’s certain things Spark and Hadoop will never do as well as we’ll be able to do.”
Programming FPGAs is not for the faint of heart. In fact, it’s downright hard. Ryft has attempted to shield users away from that complexity by providing open APIs that allow customers to call the Ryft One functions as needed.
“The way it works is we actually implement these algorithms [the exact search, fuzzy search, and term frequency primitives] in the FPGA fabric, and we wrap the kernel node drivers in Linux and the open API around that, so a user calls what they think is a standard C function,” McGarry says. “It’s mapped automatically for them, without any knowledge of their own, back into our FPGA fabric to run these things at ridiculously high speeds.” A RESTfuli API is also available for calling Ryft One functions over standard Web protocols.
The idea is to give customers an easy way to offload those specific functions from a Spark or Hadoop cluster onto the Ryft One. While it may sound restrictive to have only three functions to work with, they are more useful than they initially appear, McGarry says.
“The primitives in this data analytic space are macro functions that data and computer scientists understand,” he says. “Cloudera thinks the major primitives that things reduce to are search….and term frequency, which is the same thing as word count. Term frequency becomes the foundation of any good machine learning system.”
 Depending on customer uptake, Ryft may choose to add more primitives, such as like serving and image processing, which would open the box up to more uses. In the meantime, potential applications for the Ryft One today include anything that depends on identifying patterns in text, such as fraud detection, log analysis, social media analysis, or genomic indexing.
Depending on customer uptake, Ryft may choose to add more primitives, such as like serving and image processing, which would open the box up to more uses. In the meantime, potential applications for the Ryft One today include anything that depends on identifying patterns in text, such as fraud detection, log analysis, social media analysis, or genomic indexing.
“The fraud space is ripe for this kind of stuff. You have your historical data, historical patterns, across maybe 10 or 12 TB, if you’re a large financial institution,” McGarry says. “Maybe you’re looking at stock quotes while you’re looking at application logs and server logs, and maybe you’re also looking at geological tweets about certain stocks and companies. You can do that effortlessly in a single box. And that’s why we’re so excited, because we think we finally developed something that is no longer forcing people into the hammer-nail problems that they have with today’s clusters.”
The Ryft One will be available in early Q2 2015 as a hosted or on-premises solution. The company is selling it as a service with pricing starting at $120,000 for the first year, along with a one-time $80,000 integration charge.
Related Items:
When to Hadoop, and When Not To
Novel Storage Technique Speeds Big Data Processing
Three Ways Big Data and HPC Are Converging
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
Call & Contact Center Expo
 April 24 - April 25Las Vegas NV United States
April 24 - April 25Las Vegas NV United States -
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States
Overall this looks very similar to the strategy that Convey Computing has / had been pursuing. What are the key differences here?