

February 17, 2015
Pivotal Throws in with Hortonworks and Open Source

Pivotal today pulled the plug on its proprietary big data strategy and uncorked a major repositioning that involves making core products like HAWQ, Greenplum, and GemFire open source and aligning its Hadoop fortunes with one-time rival Hortonworks. The software company also was revealed to be a founding member of the new Open Data Platform, which also launched today.
Pivotal’s partnership with Hortonworks has several components, including product integration, joint engineering, and technical support. While Pivotal will continue to develop its Hadoop distribution, called Pivotal HD, the company will march to the beat of the open source drum instead of following its own path. Also, Pivotal will allow other Hadoop distributions (namely Hortonworks Data Platform) to run in version 2 of its Pivotal Big Data Suite, which was unveiled today.
Pivotal says its moves will combat “fragmentation and vendor lock-in,” which it says are some of the big data industry’s biggest challenges. “We’ve been encouraged by the positive reception we’ve received from our largest customers/partners, and hope that it will represent a significant turning point for an industry that has been traditionally dominated by closed, proprietary database products,” Pivotal president Scott Yara says in a press release.
Hortonworks has also agreed to provide “escalation level support” for Pivotal HD. The two companies will also work together to ensure that Pivotal HAWQ (an interactive SQL engine similar to Hive) and Pivotal GemFire (an in-memory NoSQL database) are fully integrated with Apache Hadoop.
Today’s announcement doesn’t signal the end of the Hadoop road for Pivotal, which was spun off from EMC less than two years ago with a $105-million investment from General Electric. But the move does indicate an acknowledgement by Pivotal that it has struggled to gain market share in a rapidly evolving market for big data software and services.
Signing Pivotal is a major coup for Hortonworks, which has long claimed that its Hadoop distribution is the closest to the main trunk of pure open source Apache Hadoop (a claim that competitors often question). It’s also a sign that the Hadoop business may be nearing a phase of consolidation, which began last year when Intel bowed out of the Hadoop race and aligned its fortunes with Cloudera.
“Pivotal is joining Hortonworks in our belief that the best way to deliver infrastructure platform technology today is completely in open source,” Hortonworks Vice President of Corporate Strategy Shaun Connolly says in a press release. “Moreover, we believe that collaborative open source software development under the governance model of an entity like the Apache Software Foundation (ASF) is the best way to accelerate innovation…”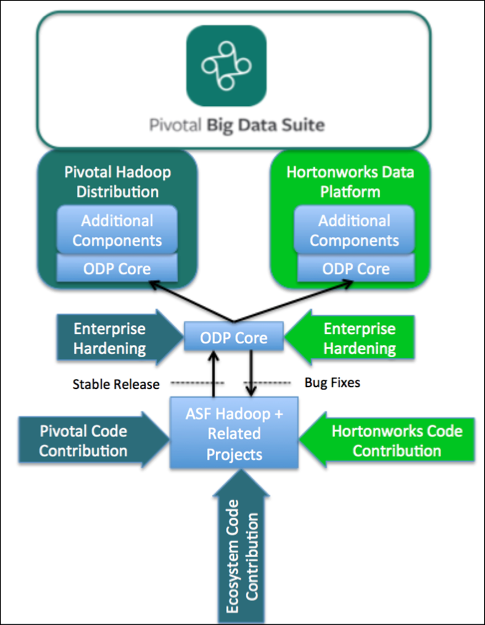
The creation of the Pivotal-Hortonworks partnership comes against the backdrop of the unveiling of the Open Data Platform (ODP) on the eve of Strata + Hadoop World, which opens tomorrow. The group’s goal is to promote big data technologies based on open source Apache Hadoop software for the purpose of optimizing testing among and across the ecosystem’s vendors.
The rapid proliferation of software in the Hadoop ecosystem has undoubtedly helped fill the big data needs of customers, but it has also created major headaches when it comes to ensuring that various Hadoop products are compatible with one another. To that end ODP aims to create a single standard that software developers can use to test their products. It’s a “test once, use everywhere” approach, and it starts with core Apache Hadoop and Apache Ambari, among other “related Apache source artifacts.”
Pivotal and Hortonworks are both “platinum” members of the HDP. Other platinum members include IBM (which also has a Hadoop distribution), GE, Infosys, SAS, and an unnamed telecommunications firm. Gold members include Altiscale, Capgemini, CenturyLink, EMC, Splunk, Verizon Enterprise Solutions, Teradata, and VMware.
Pivotal’s announcement raises certain questions about the ownership of the products it has placed in the open source realm. “Our detailed plans are still being finalized,” Pivotal senior vice president Michael Cucchi says in a blog post, “but we plan to begin release and incubation of Pivotal GemFire, Pivotal HAWQ, and Pivotal Greenplum Database in a quarterly cadence. We’re closing in now on the structure of ownership of GemFire, Greenplum Database, and HAWQ code to the most appropriate entity for working with the big data community.”
Pivotal will continue developing Pivotal HD in adherence to the ODP, Cucchi says. “As a result, Pivotal’s next version of Pivotal HD will also be significantly advancing as a result. This next version will include all of the available Apache projects, including support for Spark, making Spark’s distributed, in-memory analytics processing available to our customers,” he says.
Obviously there’s a lot going on at Pivoital these days. But one hidden gem that should not be overlooked is that Greenplum is now open source. “Open sourcing Greenplum Database is great news for the industry,” says Joe Hellerstein, founder and Chief Strategy Officer at Trifacta. “For the first time, there’s a serious enterprise grade, full featured, massively parallel database engine that’s available to everyone. And let’s not forget that the Greenplum codebase and APIs remain close to their roots in PostgreSQL, so a major open source community now has a clear upgrade path to Big Data.”
Pivotal will be hosting a call today at 11 a.m. PT to share more news about the various announcements.
Related Items:
Pivotal: Say No to Hadoop ‘Tax’ with Per-Core Pricing
Don’t Overlook the Operationalization of Big Data, Pivotal Says
Pivotal Launches With $105m Investment From GE
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States