

November 19, 2014
Teradata Has Hadoop Covered with MapR Partnership

Teradata completed a trifecta of sorts today when it announced a strategic partnership with MapR Technologies. The partnership comes on the heels of similar deals Teradata formed with the two other pure-play Hadoop providers, Cloudera and Hortonworks. But this deal is different insofar as what MapR can bring to the table, the new partners say.
As part of the deal, Teradata will become a reseller for all of MapR‘s products and services, which is similar to the reseller deals it has for Cloudera and Hortonworks. Teradata will also work with MapR to build a special QueryGrid connector that allows its customers to push analytic workloads down from Teradata and Aster databases into MapR clusters, which is also similar to the reseller deals it has for Cloudera and Hortonworks.
Just about the only structural difference among the three distributor partnerships surrounds the Hadoop appliance that Teradata sells. For now, only Hortonworks is allowed to provide the Hadoop software that runs atop the appliance, although that could change in the future, Teradata says.
While the partnerships Teradata has with the three distributors look the same on paper, there are meaningful differences in terms of the Hadoop software that each vendor brings to Teradata customers, says Chris Twogood, vice president of product and services marketing for the Dayton, Ohio-based company.
“We have QueryGrid integration with all three, but the distributors themselves have different approaches in terms of how they bring distributions to market,” Twogood says. “MapR has spent a lot of time and focus on the file system and making that world-class and scalable. Hortonworks is really focused on staying as close to the core of open source as possible. Then Cloudera is focused on other areas…They’re focusing on access with Impala” and the Cloudera Manager tool.
That sentiment was echoed by Jack Norris, chief marketing officer for MapR. “While the connection itself is not unique, the way we leverage that is unique because we do continuous random read-write updates into the platform,” Norris says. “It’s not a batch-append, write-once data load. ….[B]ecause we’ve done that architectural work underneath, it’s vastly different and really appreciably different in terms of how data gets continually updated.”
Teradata and MapR have at least a dozen joint customers across six industries, including a financial services firm that’s running MapR on a 1,700-node Hadoop cluster and a retailer with a 2,000 node setup. There are likely many more Teradata customers testing MapR and other Hadoop distributions in sandbox environments.
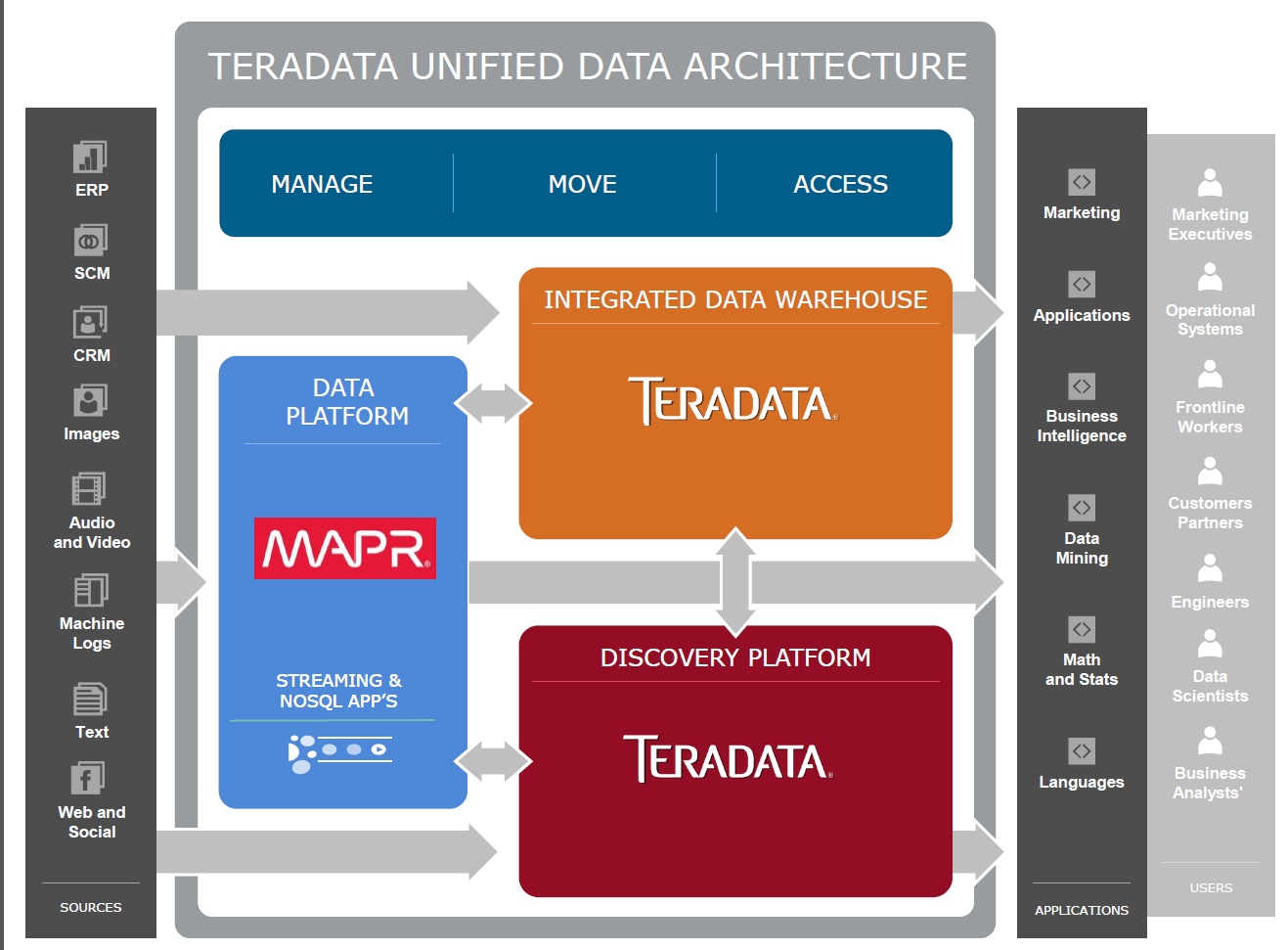 The partnership will give Teradata salesmen additional software to sell existing customers as they wrap up their proof of concepts (POCs) and start to roll out Hadoop into production. While it’s true that all of the Hadoop distributors have sought to add the interactive SQL capabilities that would enable it to mimic some functions offered by data warehouse products like Teradata’s, one shouldn’t expect Hadoop to displace existing Teradata investments.
The partnership will give Teradata salesmen additional software to sell existing customers as they wrap up their proof of concepts (POCs) and start to roll out Hadoop into production. While it’s true that all of the Hadoop distributors have sought to add the interactive SQL capabilities that would enable it to mimic some functions offered by data warehouse products like Teradata’s, one shouldn’t expect Hadoop to displace existing Teradata investments.
“I’ll have one customer who spent three years trying to create a data warehouse out of Hadoop–not MapR but another distribution,” Twogood says. “Finally they gave up and bought Teradata. I had another customer that says I want to replace Teradata, and they gave another distributor multiple millions of dollars to make it happen and after three months said I can’t do it.
“Hadoop is just not mature enough and doesn’t have all the capabilities and functionality,” he continues. “It’s really not about ‘Will Hadoop replace the warehouse?’ or ‘Will the warehouse replace Hadoop?’ The market has evolved. It’s not a single system anymore. It’s really about an analytical ecosystem and what vendors need to do is to focus on the software that makes that integration easy and seamless. Because customers don’t want to do this themselves.”
MapR has an edge over other Hadoop distributors when it comes to supporting random read-write updates and NFS-resident data, as well as its integrated NoSQL database. This may prove advantageous when it comes to running applications designed to make sense of log data generated by devicces in the new “Internet of Things” world. There is still a perception in the marketplace that what MapR has done is proprietary, which is somewhat true–although it’s also true that MapR supports open data formats with its proprietary modifications to Apache Hadoop.
As Teradata’s Twogood pointed out, the market is still young and is evolving. “A lot of it for us is customer choice,” he says. “Customers will look at that which ones are best in the environments they’re going into.”
The Teradata Connector for Hadoop (TDCH) is available now allows customers to move data to and from MapR or any other Hadoop environment. The first QueryGrid adapter will enable users of Teradata 14.1 to push queries down to MapR version 3.1.1, and will become available in January.
Teradata will follow that up with a QueryGrid adapter that connects Teradata 15 (the latest release) with MapR 3.1.1 and MapR 4.0, and another QueryGrid adapter that connects Aster 6.10 and MapR 3.1.1 and 4.0.1. Those adapters are slated to become available in the first half of 2015, Teradata says.
Related Items:
Teradata Edges Closer To Hadoop
MapR’s Hadoop Offering the Strongest, Forrester Says
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States