

October 14, 2014
Cloudera Trots Out Impala 2.0 With Latest Hadoop
The modern Hadoop stack is so broad and so deep that it is hard to encapsulate the update to a commercial distribution of the data analytics platform in one fell swoop. But if you had to do it with the Enterprise 5.2 update coming out of Cloudera this week at Strata + Hadoop World, then the message would be broader and deeper SQL support and more automation to deploy Hadoop onto public clouds.
The Cloudera Enterprise 5.2 release is based on the most current CDH 5 code, which is in turn based on the Apache Hadoop project’s core analytics stack. This implementation supports the new MapReduce 2.0 (MRv2) resource management and job scheduling framework running atop YARN as well as the old MapReduce 1.0 for backwards compatibility. The core Hadoop has been certified to run on Canonical’s Ubuntu Server 14.04, which is a so-called Long Term Support release from that Linux distributor. There are a lot of other tweaks relating to the stability and reliability of elements of the Hadoop stack in the core CDH 5.2, including important changes for the YARN Fair Scheduler to have it make better scheduling decisions. The stack includes HBase 0.98.6, a fairly minor update to the database layer for the Hadoop Distributed File System (HDFS), and Hive 0.13, the data warehousing layer for HDFS that includes an SQL-like query language, and the Apache Spark/Streaming 1.1 layer for managing streaming data.
Cloudera Enterprise builds on top of the core CDH, and in this case the most important thing to come with the 5.2 release is Impala 2.0, which Clarke Patterson, senior director of product marketing at Cloudera, says is a major release. Impala is a massively parallel query engine that sits atop HDFS or Hive and allows for ad hoc queries to be run against that information at something approaching the speed of interactive relational databases. The Impala effort was spearheaded by Marcel Kornacker, who was one of the key developers of the F1 fault tolerant, distributed relational database developed by search engine giant Google as the foundation of its AdWords advertising system. Impala was launched as a project at Hadoop World two years ago, and started shipping about 18 months ago inside of the Cloudera Enterprise distribution.
Patterson tells Datanami that there have been over 1 million downloads of the Impala add-on for Hadoop, including both open source and commercial versions, and that over 60 percent of customers deploying the top-end Data Hub Edition of Cloudera Enterprise have deployed this analytic SQL layer to support applications. Rival MapR Technologies has adopted Impala for its distribution, and Oracle is also using it in its Big Data Appliance, which uses a Cloudera distribution of Hadoop.
“We are enhancing the multiuser experience, and making sure that we can run more concurrent workloads and act as a highly interactive system for multiple people,” says Patterson of the improvements in Impala 2.0. To help cope with resource constraints relating to Impala, Cloudera added some disk-based query processing routines – allowing joins and aggregations to spill out of memory and into disks – and also has come up with balancing resources better across a larger number of requests. The precise throughput improvements were not available at press time.
Cloudera has not put the finishing touches on its Impala 2.0 benchmarks yet, but only a few weeks ago did divulge some performance metrics of Impala as it outran Sparc SQL, Presto, and Stinger Hive on Tez on single-user and multiuser workloads. The multiuser tests are probably the most important, and here is what that looks like:
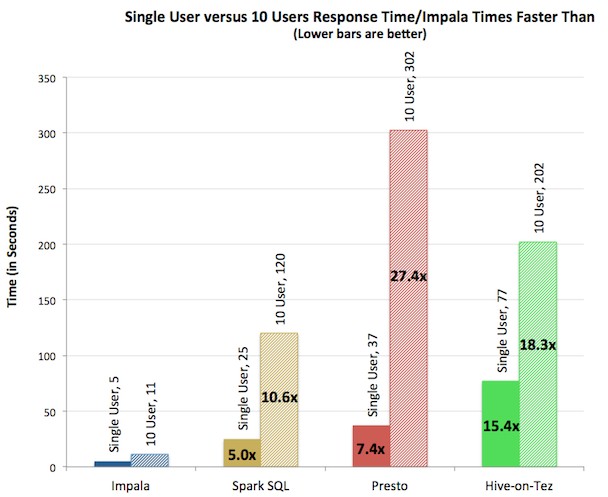 These tests were run on a 21-node cluster with 64 GB main memory footprints; each node had two 12-core Xeon E5-2630L processors from Intel and a dozen disk drives with an effective capacity of 932 GB each. The comparisons are on a 15 TB dataset and the application implements a decision support application that is derived from the TPC-DS test. The Impala cluster was able to do 2,333 queries per hour, which was 8.7X that of Spark SQL, 13.3X that of Hive on Tez, and 22X that of Presto. The performance gap with Impala 2.0 is expected to widen even more.
These tests were run on a 21-node cluster with 64 GB main memory footprints; each node had two 12-core Xeon E5-2630L processors from Intel and a dozen disk drives with an effective capacity of 932 GB each. The comparisons are on a 15 TB dataset and the application implements a decision support application that is derived from the TPC-DS test. The Impala cluster was able to do 2,333 queries per hour, which was 8.7X that of Spark SQL, 13.3X that of Hive on Tez, and 22X that of Presto. The performance gap with Impala 2.0 is expected to widen even more.
The other big thing with Impala 2.0 is broader support for SQL functions, and this time around analytic window functions, security permissions through GRANT/REVOKE statements, and subqueries are being added to be compliant with ANSI SQL standards and so are other datatypes (CHAR and VARCHAR are two of them), as well as popular vendor-specific SQL extensions. The release notes are out so you can see the details there, but better still Cloudera did outline the evolution of SQL compatibility for the Impala layer in a blog back in August. That also shows the SQL functions expected to be added to Impala 2.1 in 2015.
“Our goal here is to meet SQL standards in their most robust form, so we are constantly adding and iterating so that every type of query you can run in a non-Hadoop environment you can do in Hadoop in the future,” says Patterson. “We end up deploying alongside data warehouses a lot, and companies will want to do a data warehouse archive such that data that is not being accessed in their relational system will be pushed down into our Data Hub, but they still need a way to retrieve it for ad hoc reporting or compliance purposes. So we want to be able to support whatever kind of query that would run in that data warehouse environment.”
In addition to the core CDH 5.2 and Impala 2.0, Cloudera also announced a new graphical tool called Cloudera Director, and administrative tool for spinning up and managing Hadoop on public clouds. The first iteration of the tool can setup Cloudera’s Hadoop on the Amazon Web Services cloud, and support for other clouds will no doubt be coming in the future. With a number of large, data-driven companies standardizing on AWS as their infrastructure, Cloudera has no choice but to treat AWS as it would any on-premises platform. But because AWS capacity is not always persistent and is accounted for differently from investments in hardware and software for the datacenter, deploying to AWS requires a different interface than the Cloudera Enterprise management console provides. Cloudera Director us free to download and use and will be supported through a subscription to Cloudera Enterprise. Presumably it will next support clouds based on VMware ESXi/vCloud and OpenStack.
Cloudera’s software is available in a number of different editions, as follows:
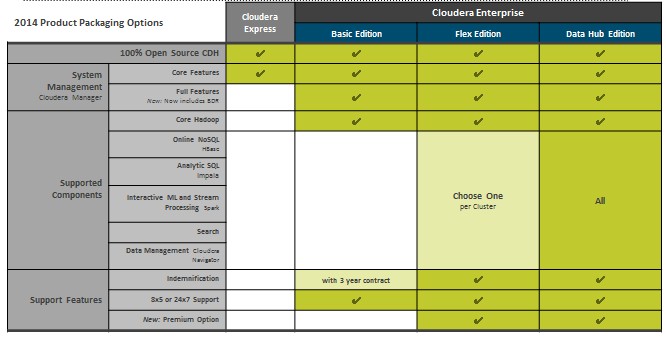 The Cloudera Express Edition has the core Hadoop components and add-ons is free. The Basic Edition adds some more features, and the Flex Edition allows customers to add one module of NoSQL database (HBase or Accumulo), interactive SQL (Impala), interactive analytics (Spark), search or governance and auditing (Navigator) to the Basic Edition. The Data Hub Edition has the whole enchilada rolled in. Cloudera does not publish its prices, but Patterson says licenses are charged on a per-node basis and the scale is non-linear as functions are added.
The Cloudera Express Edition has the core Hadoop components and add-ons is free. The Basic Edition adds some more features, and the Flex Edition allows customers to add one module of NoSQL database (HBase or Accumulo), interactive SQL (Impala), interactive analytics (Spark), search or governance and auditing (Navigator) to the Basic Edition. The Data Hub Edition has the whole enchilada rolled in. Cloudera does not publish its prices, but Patterson says licenses are charged on a per-node basis and the scale is non-linear as functions are added.
Related Items:
Cloudera Touts Near Linear Scalability with Impala
Cloudera Articulates a ‘Data Hub’ Future for Hadoop
Cloudera Releases Impala Into the Wild
Applications:
Data Mining
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
Call & Contact Center Expo
 April 24 - April 25Las Vegas NV United States
April 24 - April 25Las Vegas NV United States -
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States