

August 14, 2014
AMPLab’s Tachyon Promises to Solidify In-Memory Analytics
U.C Berkeley’s AMPLab first landed on the radar screens of data scientists with Apache Spark, which promises to provide an in-memory data processing framework to replace or augment MapReduce. More recently, the tech wizzes at AMPLab have whipped up Tachyon, a new distributed file system that sits atop HDFS and aims to allow multiple Hadoop or Spark applications and jobs to access the same data at memory speeds without fears of corrupting it.
The rapid rise of Apache Spark demonstrates the widespread desire in the analytics community for faster processing and more granular iteration of analysis. If the first generation of Hadoop, which leaned heavily on batch-oriented MapReduce jobs, gave us a taste of what was possible with big data analytics, then Spark and its in-memory framework are viewed as the vehicles that will take us to the promised land of interactive and real-time analytics.
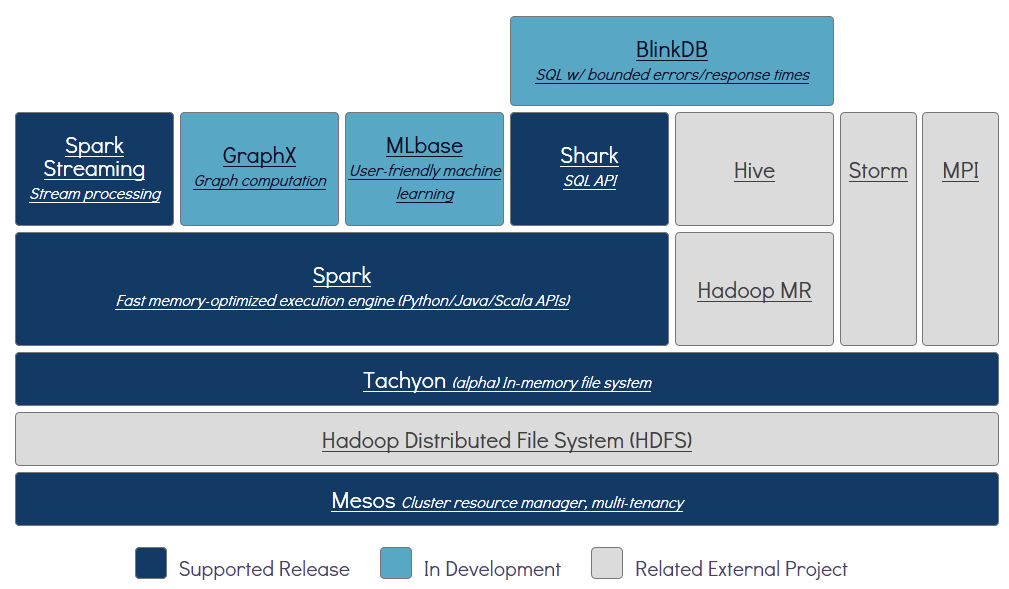
Tachyon buffers data as it flows between Spark and HDFS
The in-memory nature of Apache Spark is critical to achieving the big speed-ups over first-gen MapReduce applications that enterprises demand. The more memory that’s available, the more data can be kept up in the air, and the more value can be extracted from it. But problems creep up when the data needs to be written to a file system, where it can be picked up by an application in the next stage of the pipeline. To maintain fault tolerance, the data is typically written to disk via HDFS. But this slows down the whole process and eliminates some of the benefits of using in-memory processing in the first place.
Tachyon provides a potential solution to that dilemma by enabling data to be written to a file system while still in memory, without giving up the fault-tolerance that writing to spinning disk via HDFS has provided.
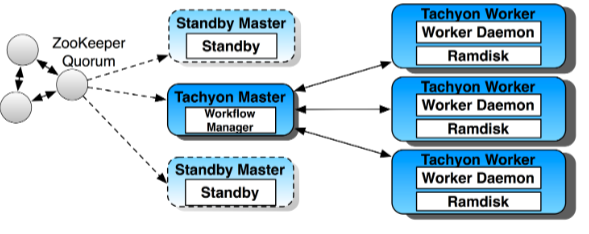
Tachyon uses a distributed architecture to provide resilience
According to the official Tachyon website at tachyon-project.org, Tachyon provides a memory-centric distributed file system that enables reliable file sharing at memory-speed across cluster frameworks, like Spark and MapReduce. “Tachyon caches working set files in memory, and enables different jobs/queries and frameworks to access cached files at memory speed,” it says. “Thus, Tachyon avoids going to disk to load datasets that are frequently read.”
The open source product, which was first released in 2013, is compatible with existing Spark, Shark, and MapReduce programs, and uses the same HDFS standards for file operations, such as create, open, read, write, close, and delete. But instead of writing to disk, it keeps it all in memory for as long as possible. In addition to HDFS, it supports Amazon S3, GlusterFS, and single-node local file systems as the underlying file system for resiliency purposes, and more file systems are slated to be supported in the future.
The secret sauce in Tachyon is how it recovers from errors. It uses a lineage-based approach that involves logging the data transformations used to build a data sets, and then using those logs to rebuild the data if needed. “Tachyon achieves memory-speed and fault-tolerance by using memory aggressively and leveraging lineage information,” says Haoyuan Li, the lead developer for Tachyon at the AMPLab, in a summary of his upcoming Strata + Hadoop World talk.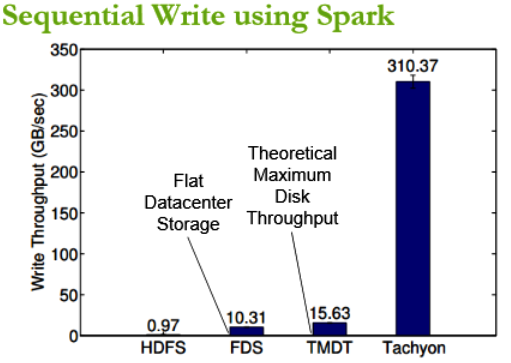
Initial results show that Tachyon can attain wri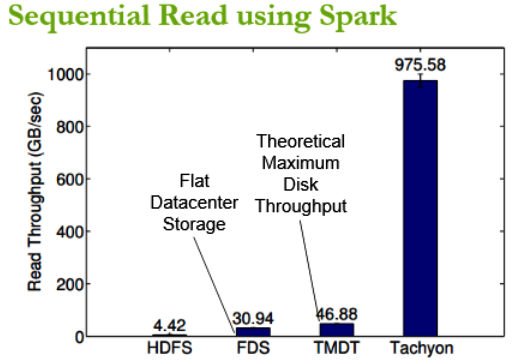 te throughput 300x higher, and speed up jobs more than 10x, over HDFS. It does this in a reliable manner by avoiding the use of synchronous data replication to disk, and writing data to disk asynchronously, only after it’s been written to memory.
te throughput 300x higher, and speed up jobs more than 10x, over HDFS. It does this in a reliable manner by avoiding the use of synchronous data replication to disk, and writing data to disk asynchronously, only after it’s been written to memory.
This approach could help enterprises implementing big data analytic systems to overcome disk and network I/O limitations. “More importantly, we believe that due to the inherent bandwidth limitations of replication, a lineage-based recovery strategy like Tachyon’s might be the only way to make cluster storage systems match the speed of in-memory computations in the future,” Li and his fellow AMPlab co-developers Ali Ghodsi, Matei Zaharia, Scott Shenker, and Ion Stoica and Hortonworks developer Eric Baldeschwieler write in a November 2013 paper titled “Tachyon: Memory Throughput I/O for Cluster Computing Frameworks” (click here to see a copy).
While Tachyon is still in Alpha, it’s a supported component of the AMPLab’s Berkeley Data Analytics Stack (BDAS), along with Spark, Shark, Spark Streaming, and Mesos. It’s the default off-heap storage medium for Spark and is included in the Fedora distribution from Redhat. Momentum is building for the software, which saw a 0.5 release unveiled less than a month ago.
Today, the Tachyon project involves more than 40 contributors from over 15 institutions, including Yahoo, Intel, Hortonworks, and others. It’s received backing from Cloudera, Databricks, ClearStory Data, Palantir, Conviva, GE, Facebook, Cisco, Ericsson, and others. The software, which is distributed under an Apache 2.0 license, is commercially supported by Atigeo, and has been deployed in at multiple companies.
It appears that Tachyon is well-positioned to help solve one of the impediements to the move to in-memory computing. As Apache Spark and in-memory competing gain momentum on Hadoop, chances are good that you’ll be hearing more about Tachyon in the months ahead.
Related Items:
Now and Then: The Evolution of In-Memory Computing
Where Does Spark Go From Here?
Databricks Takes Apache Spark to the Cloud, Nabs $33M
Sectors:
Academia
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
Call & Contact Center Expo
 April 24 - April 25Las Vegas NV United States
April 24 - April 25Las Vegas NV United States -
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States