

July 14, 2014
HP Throws Trafodion Hat into OLTP Hadoop Ring

Hewlett-Packard last month quietly unveiled Trafodion, an ANSI-compliant relational SQL database that’s now available as an open source product. With two decades of development at HP and the new capability to run on top of HBase, Trafodion could provide a big boost to efforts to run transactional workloads on Hadoop.
The database technology behind Trafodion (which is Welsh for “transaction”) has been around for a long time at Hewlett-Packard, but it was dancing perilously close to the waste bin of computer history before being given a second life by HP Labs.
Trafodion started life more than 20 years ago as a massively parallel processing (MPP) data store behind HP’s enterprise-grade NonStop transactional clusters. In 2007 HP broke the analytical portions away from the online transaction processing (OLTP) portions and created the NeoView enterprise data warehouse, which formed the basis for HP’s own internal EDW efforts. Today, the company is moving its EDW off NeoView (since renamed Seaquest) in favor of Vertica, which it acquired in 2011 and which today is HP’s strategic EDW platform.

How Trafodion components (in blue) fit into Hadoop (in grey).
But instead of mothballing the powerful NeoView/Seaquest technology, which HP has dozens of patents for and which represents $250 million in investments by the company, it decided to rejuvenate it as an OLTP engine and retrofit it to run on top of HBase, the NoSQL-esque key value store that runs on Hadoop. Available now as an open source product at www.trafodion.org, the software, currently in public beta, could form the basis for an enterprise offering later this year as part of HP’s latest commercial open source venture.
HBase with ACID
Trafodion fills a gap in Hadoop when it comes to ANSI-compliant and ACID-supporting transactional databases, says Rohit Jain, a distinguished engineer at HP who’s the chief technologist for Seaquest and Trafodion.
“We took our transactional heritage and experience and IP [intellectual property] and brought it down to HBase, because HBase doesn’t have the transactional support,” Jain tells Datanami. “It has ACID support only at the row level. We bring full-blown ACID for cross-row, cross-table, cross statement-type transactions. Essentially this is a little niche that has not been filled yet by anybody. We’re effectively saying you can use Hadoop for all workloads, all the way from OLTP to analytics.”
Trafodion supports ANSI SQL core 99, plus some 99 packages and 2003 syntax support, Jain says. It comes with a sophisticated query optimizer and support for many types of joins. If your HBase implementation is missing standard RDBMS (relational database management system) fare like triggers, user defined functions (UDFs), and referential integrity, then you’ll be happy to find them in Trafodion.
The parallelism of the Trafodion query optimizer and join functions will be good matches for Hadoop’s massive parallelism. “When you need to invoke parallelism, we start up multiple processes on behalf of the query, just like a MapReduce query would,” Jain explains. “And then we would scrub that and decide the degree of parallelism you need to be able to do that scanning. And then if you’re doing joins and all that, we again decide what degree of parallelism you need for the joins and the aggregations etc.”
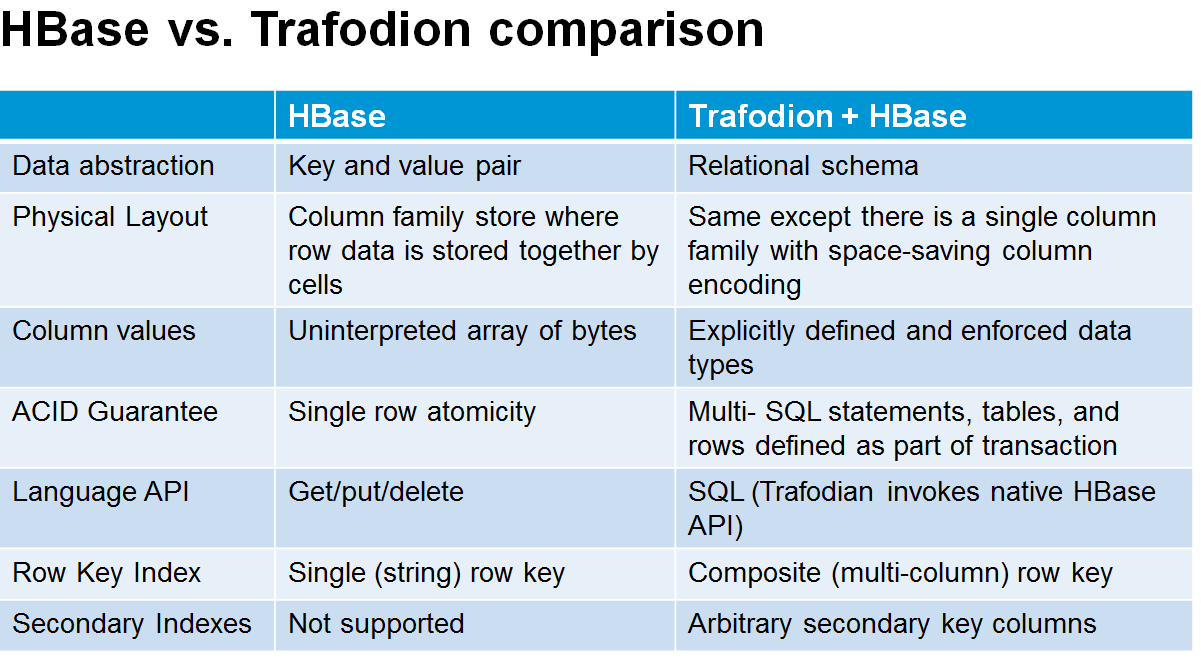 The goal is to position Trafodion as the data store for standard structured data that typically go into transactions, and to leverage HBase for the less-structured data that are also used in today’s Web-scale applications, such as images and text. Because Trafodion sits on top of HBase, users can target that data store with a single SQL query, thereby query simplifying development.
The goal is to position Trafodion as the data store for standard structured data that typically go into transactions, and to leverage HBase for the less-structured data that are also used in today’s Web-scale applications, such as images and text. Because Trafodion sits on top of HBase, users can target that data store with a single SQL query, thereby query simplifying development.
“You can have structured, semi-structured, and unstructured data, and it can all be analyzed with a SQL query,” Jain says. “If you try to do that with a typical relational technology, you have to stuff the data object into a BLOB or large objects into a CLOB. You can’t do the sentiment analysis as easy as you could with, say, just HDFS.”
One potential use of Trafodion is to use it in e-commerce applications, where its ACID support will give companies the confidence that it will process credit card transactions correctly. As customer comments are added to the website, other Hadoop applications could perform sentiment analysis on the text.![]()
At the HP Discover conference last month in Las Vegas, where HP unveiled Trafodion, the company demonstrated the software running an open source shopping cart application that was originally designed for MySQL. HP made a few modifications to Trafodion to get it to look like MySQL to the application. While the company is not, at this time, touting Trafodion as a plug-in compatible storage engine for MySQL, that appears to be in its future.
“Why not make Trafodion a storage engine for MySQL,” Jain asks. “If you’re just using MySQl or MySQL cluster, [running it on Trafodion via Hadoop] allows you to scale, because Hadoop can scale.”
Why Transactional Hadoop
While Hadoop is generally thought of as a platform for running big data analytic workloads, there is a sub-current of thought that says Hadoop and its distributed file system, HDFS, will eventually (and perhaps inevitably) be used for running OLTP workloads too. Hadoop creator Doug Cutting is among those who see OLTP coming to Hadoop.
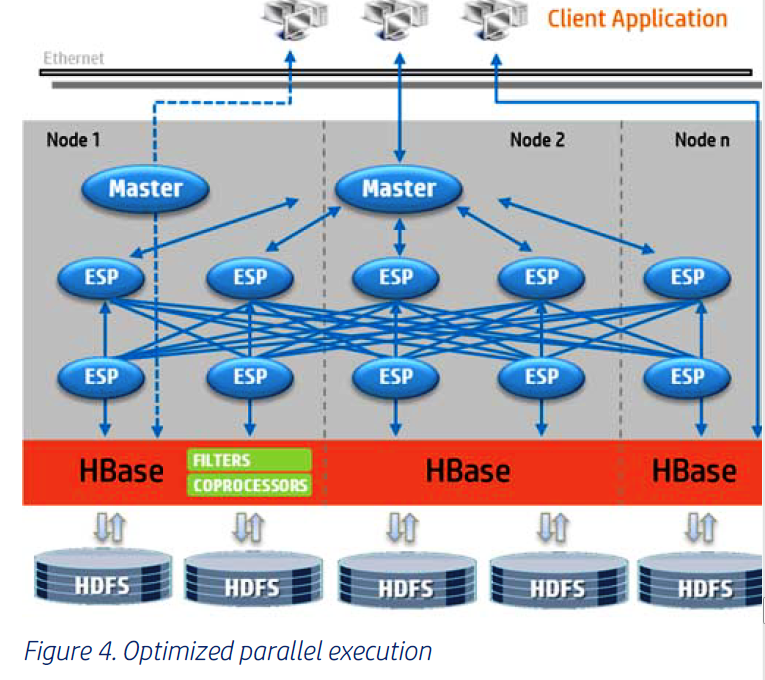
Trafodion can optimize execution of OLTP workloads on Hadoop in a parallelized manner
As data gets too big to move, the thinking goes, and the window of opportunity for analyzing acting on transactions approaches real-time, the difference between what’s OTLP and what’s analytic will begin to disappear. And therefore, the underlying data platforms that these converged OLTP and analytic functions run on–not just Hadoop but converged OLTP and OLAP databases from SAP, Oracle, IBM and Microsoft–will begin to look more and more alike.
The problem that’s driving vendors to this common ground for OLTP and analytics is that, even if your goal is to do big data analytics, you’re going to need lots of data originating in other sources. “It’s not just about big data analytics. It’s about enterprise data,” Jain says. “What you need to do any processing or any analytics is you need the unique master data, and all that master data is structured and sitting on Oracle or SQL Server, and you need to in Hadoop if you want to leverage that.”
In Jain’s view, there are four types of data sitting in enterprise systems, each with different traits and capabilities. “You have operational data, master data, historical data, then external data, which is where the big data stuff comes from,” he says. “To build a complete picture, and to really leverage the data and get insight, you have to leverage the entire stack of enterprise data–maybe not all of it, but certainly a lot of it. Analytics doesn’t sit by itself. It has to sit with the enterprise data, with the historical information, with the master data and so forth. That’s why we believe over time, you’re going to see HDFS becomes the file system and then all these workloads run underneath it.”
Trafodion isn’t the only product aiming to provide relational store on top of HBase. The folks at Splice Machine have taken an Apache Derby database and welded it on top of HBase to provide a place to run OLTP workloads. There is also the Apache Phoenix project, which has gained traction among the Hadoop distributors, including Cloudera. Jain is familiar with both of these efforts, but maintains that Trafodion, with its 20-year development history and advanced functions, has an insurmountable lead.
Part of Jain’s job is to work with the Hadoop distributors to get Trafodion onto their radars. The company has a partnership with MapR Technologies for the Vertica EDW, which has hooks into Hadoop, and has had conversations with Hortonworks regarding using Trafodion for transaction processing on Hadoop.
In the meantime, the Trafodion team will be working to improve the software, including helping to drive performance enhancements into HBase. “You’ll see HBase performance improving dramatic lay in the next year,” Jain says. “We’re going to get involve and we’re contributing to the effort to make HBase a much stronger, much faster, much better storage engine.”
Related Items:
Moving Beyond ‘Traditional’ Hadoop: What Comes Next?
OLTP Clearly in Hadoop’s Future, Cutting Says
Making Hadoop Into a Real-Time SQL Database
Applications:
Complex Event Processing
Vendors:
Hewlett-Packard
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States