

June 24, 2014
How T-Mobile Got More from Hadoop
When T-Mobile’s engineering department filled up a pair of 1 petabyte Netezza appliances from IBM, the cell phone carrier naturally turned to Hadoop. But when Hive and Pig turned out to be less than ideal query mechanisms on a cluster with half a trillion rows, the company searched for a suitable replacement, which it found from RainStor.
T-Mobile had what you would call a big problem with its data warehouse; namely it was growing too fast. The cell phone company stores all activity data generated from its 40 million subscribers in a data warehouse so that its RF engineering team can dream up new things to sell the customers. That database, which stores the last month of activity data, is growing at a rate of 5 percent per month, which means it increases by 2.5x every 18 months.
“Only massively parallel architectures can handle this kind of growth and allow us to query on it,” T-Mobile principal architect Art Popp says in a recent video. “Since the time of color on cell phones, no conventional database was suitable for these sorts of queries, so we’ve been trying the different massively parallel architectures.”
The IBM Netezza MPP appliances initially fit the bill quite nicely, but when the data just kept growing and it was time to expand the appliances, the bill caused minor fits. “With Hadoop clusters, we can get one-fifth the cost per petabyte, so it was time to look at Hadoop,” Popp says. “We evaluated it and got 2PB worth of Hadoop cluster.”
The company selected the Hadoop distribution from Hortonworks, and it worked well for the most part. But one thing that stood out was the difficulty in developing queries for the cell phone usage data. “You have to be really good to make efficient queries on Hive and Pig on Hortonworks,” he says. “And that limits the number of people who can make use of this data in the company. We have 20,000 internal employees so we would like a broader audience than 10.”
The security of the Hadoop data was the other main concern for T-Mobile. “Our risk management and legal folks previously required us to have all of our infrastructure on a completely private network segment with its own private switches and gateways in between to keep people from being able to get at all the boxes,” Popp says. Security folks are a hard group to satisfy.
So Popp set out in search of a solution that could address T-Mobile’s twin Hadoop concerns of security and query simplicity. He liked what he found in IBM’s Hadoop distribution, BigInsights, which also offers a more SQL-like query language, tight integration with Netezza, and enough Big Blue security to fulfill your compliance officer’s wildest dreams. But then again, that solution came with an IBM-esque price tag on it, too.![]()
Then T-Mobile evaluated Hadoop software from RainStor. The San Francisco, California-based company was founded in 2002 to exploit technology originally developed by the United Kingdom’s Ministry of Defence to store big data. More than 100 large banks, telecommunications firms, and enterprises have used the software running on NAS and big storage arrays.
“Our customers tell us they want to be able to do trending and historical analysis and compare to what happened X years ago,” says Deirdre Mahon, vice president of marketing for RainStor. “They also want access to all the data, the detailed raw history. They don’t want to access aggregated data. At same time, legal and finance departments want to look back and replay what happened five years ago, especially if there’s a lawsuit.
In 2012, the company debuted its first Hadoop solution, and today RainStor bills itself as an archiving application for Hadoop that just happens to have top-notch query and encryption capabilities built into it.
RainStor’s secret sauce lies in its compression algorithm, which reliably shrinks the size of structured and semi-structured data files stored in HDFS by up to 40x. The software also encrypts this data, without requiring additional software. And for its third act, it queries encrypted data using industry standard SQL, and does it twice as fast as MapReduce-based Hive and Pig, the company claims.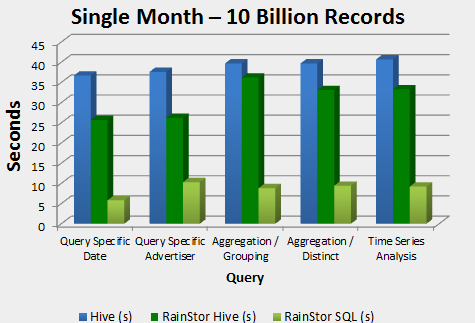
T-Mobile bought the RainStor product and started benefiting immediately, especially when it comes to optimizing queries. “We like that it solves a problem that we didn’t anticipate,” Popp says. “We wanted what we had with real databases, which was a query optimizer that could order the joins and make sure that the selects were narrowest first and used the least amount of memory possible. And RainStor has that, and that’s not part of the Hadoop promise.
“It’s very hard to point at a lot of the nice BI tools that are out there at a Hive kind of database, because they expect a query optimizer on the other end,” he continues. “They don’t have the visibility of the data to make a query hat doesn’t take forever. And now we have our pick–a smorgasbord of great BI tools that are available to us that weren’t available before.”
One concern of adding compression and encryption to the Hadoop mix was that it would slow query speeds. The company tested different RainStor configurations, and found there was a five to six percent hit from compression, 10 percent at most, “a trivial expense to pay to have the legal people be happy,” Popp says.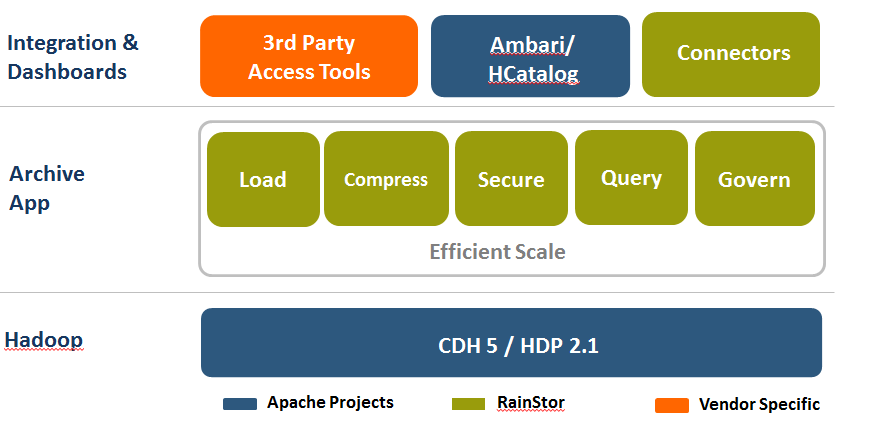
The company had finally found the kind of centralized security apparatus that would allow the RF engineering department step out from the shadows. “We can give out access to our system like we’re handing out Frisbees,” Popp says, “because we can mask out the data that marketing people shouldn’t see and only RF engineers can see, and vice versa.”
Today RainStor is launching version 6 of its Hadoop archive solution. The big news here is that the software supports Hadoop 2 and its YARN resource scheduler. YARN support has been on the minds of its prospective Hadoop customers, as well as its close Hadoop partners, Hortonworks and Cloudera, which are both quite bullish on YARN and the promise it holds for allowing Hadoop clusters to do more than one thing at a time.
RainStor version 6 also brings support for HCatalog, which should enable the archive to work with data stored by other tools, as well as support for Ambari monitoring. On the query side, RainStor gets support for SQL 2003 as well as support for XQuery. The software is tested and supported on the latest Hadoop distros from Cloudera and Hortonworks, including CDH 5.0 and HDP 2.1.
Related Items:
RainStor Brings Database to Hadoop
Rainstor Offers Mastery of Time and Schema
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
Call & Contact Center Expo
 April 24 - April 25Las Vegas NV United States
April 24 - April 25Las Vegas NV United States -
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States