

June 19, 2014
Teradata Moves Virtual Data Warehouse Forward with MongoDB

MongoDB and Teradata today announced they’re working to integrate their products to boost the analytic and transactional workloads of their joint customers. The goal of the partnership is to find a better way to feed operational JSON data from Mongo’s NoSQL database into Teradata’s warehouse, enabling faster turnaround of analytic questions.
The new capability leverages Teradata’s newly added JSON data type support and its QueryGrid functionality, which Teradata added in April with version 15 of its eponymous database. The QueryGrid functionality is based on Gartner’s concept of the virtual data warehouse, which enables Teradata-generated queries to be sent to the source system, where they utilize the remote systems’ resources.
Teradata currently has just a handful of QueryGrid connectors, which are bi-directional in nature, including connectors for its Aster system, Oracle, and Hadoop. The promise of a QueryGrid connector for MongoDB‘s leading NoSQL database is expected to be delivered in the first quarter of 2015, executives with the companies told Datanami.
The MongoDB QueryGrid will open up new sources of fresh data for Teradata customers, says Chris Twogood, Teradata Lab’s vice president of product and services marketing.
“Typically TeraData loads data on a batch or mini-batch basis,” he says. “Through the technology we’re working on together, you’re able to at runtime, or query time, say, I’m going to go grab some data from Mongo, and join it together in a query, so you don’t have a delay. You literally have the information as it was just processed in Mongo.”
That opens up some powerful new analytic capabilities for joint customers, particularly in the retail and other consumer-facing areas, such as call centers. An e-commerce application running on MongoDB could make a call to a Teradata system that holds all the data about buyers and their purchase histories, preferences, relative profitability, and complaints. 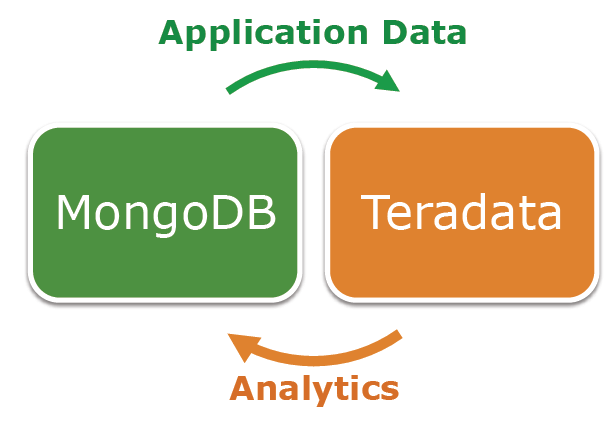 As a consumer browses a site or calls into the call center, the Teradata system could calculate an offer to make the customer based on all interactions with the customer across multiple channels over the last 60 days.
As a consumer browses a site or calls into the call center, the Teradata system could calculate an offer to make the customer based on all interactions with the customer across multiple channels over the last 60 days.
The partnership could also yield better ways of moving and analyzing machine data generated from the Internet of Things, the vendors say. Being able to rapidly pull up the details of trouble tickets or warranty information could allow companies that run both systems to maximize their use of historical customer data. This is doing some of the work that first generation MapReduce applications were built for, but with more of a real-time bent.
The partnership was driven by demand from joint customers to make their Teradata and MongoDB systems play nicely together. “Before, if you didn’t have this level of integration, you’d have to shred through the JSON objects, bring out all the data sets, invoke them and put them into rows and columns,” Twogood says. “You probably have an ETL server in the middle doing a lot of transforms. It just hits a lot of bumps…Because of the JSON data type support, we’re able to stream the data in.”
MongoDB’s use of the JSON data type allows customers to easily add, remove, and change fields in their databases without completely rewriting the database scheme, which would be required in a typical relational database. The ease of development is one of the reasons that MongoDB has become the most popular NoSQL database in the market, and has fueled Mongo’s huge funding rounds and company valuations.
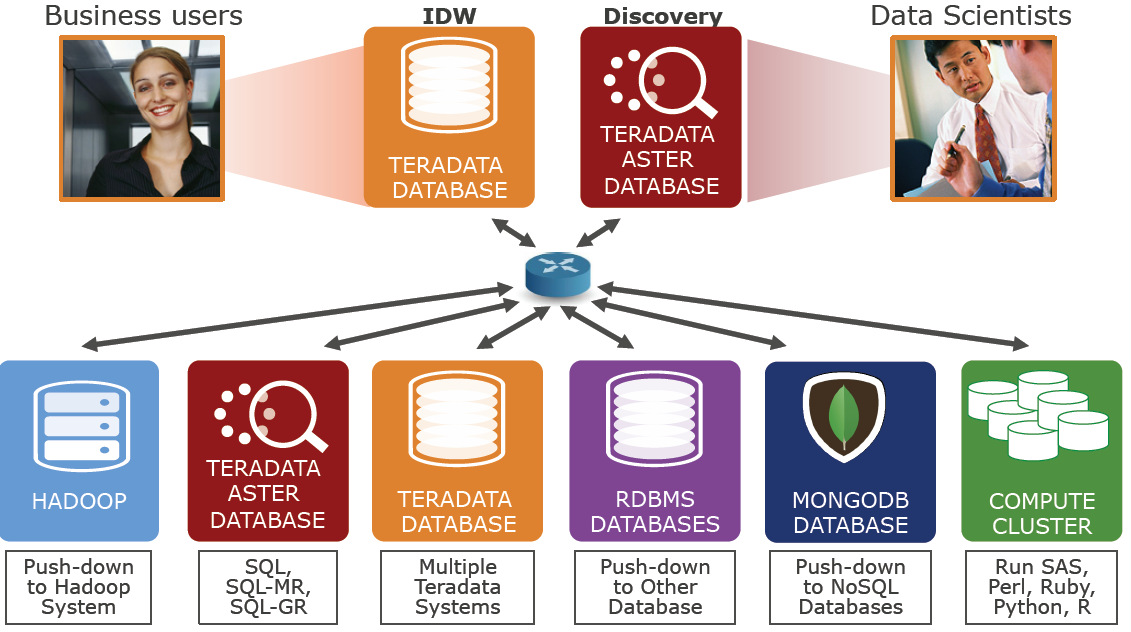
Teradata’s QueryGrid slide just got its first NoSQL inhabitant
“People say, ‘Mongo, hey it’s a schema-less database,’ when in reality JSON gives you this really rich fabric to model data,” says MongoDB’s director of product marketing Kelly Stirman. “Traditionally with rows and columns and tables, if you’re developing an application, you have to make a mental leap from the way your data is represented in your program to the way it’s represented in the database. But with JSON there isn’t the same kind of leap, and it gives you this rich structure with different data types like integers and strings and dates and other things to model data that isn’t always consistent.”
The QueryGrid connector for MongoDB’s NoSQL database will put another feather in Teradata’s virtual data warehouse cap, not to mention powerful new capabilities for Teradata customers. Executives with MongoDB and Teradata say no one database or data warehouse platform can deliver all of the capabilities that customers need (that means you, Hadoop).
“No one company can do it all, although there are some that might try,” Stirman says. “The reality is Hadoop is extremely good for certain things but it just isn’t good for other things. It just can’t be all things to all people. What you see in the Hadoop community across all the different distribution vendors is a strong effort to partner to simplify the end-to-end solution for joint customers. It’s very logical and normal that you’d use Hadoop and Teradata and MongoDB and they all have their rightful place and it’s up to other vendors to make that an easy thing for organizations to deploy and manage cost effectively and reliably and easily. That’s the opportunity for all of us.”
Somebody needs to play traffic cop in the next generation data analytics infrastructure, and with its QueryGrid and the logical data warehouse architecture, Teradata is making a play to be that cop (or one of the cops, anyway). “We see what the Hadoop vendors are doing, especially with Hadoop 2, and some of the things they’re doing with YARN in term of bringing together a lot of the different data engines in their rawest form and then plugging in engines on top of it. Those themselves are not aggregated or coordinated,” Twogood says.
“What we’re driving to in terms of Teradata is the orchestration element from the analytic perspective through leveraging of SQL as part of the overall processing,” he continues. “We do not believe that we’ll have a single architecture that will do all of this.”
While Hadoop will absorb some analytics workloads that previously ran in Teradata and other data warehouses, it won’t absorb all of them. There’s more than enough data to go around, especially with the proliferation of relatively new data types like JSON. Hadoop excels at providing that first step in the analytic and data refinement process, but in many cases customers are going to call in Teradata and other massively parallel, column-oriented and (increasingly) in-memory systems to do the final analysis.
Matching up with MongoDB is a great move for Teradata. Now, if only it had a graph database to go with it.
Related Items:
Moving Beyond ‘Traditional’ Hadoop: What Comes Next?
Why Hadoop Won’t Replace Your Data Warehouse
Teradata Makes Data Warehouse More Hadoop-ish
Technologies:
Middleware
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
Call & Contact Center Expo
 April 24 - April 25Las Vegas NV United States
April 24 - April 25Las Vegas NV United States -
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States