

June 9, 2014
Facebook Adds Another 9 to HBase Availability

As one of the largest users of Hadoop in the world, Facebook knows a thing or two about running the big data platform for a high degree of availability. Last week, the social media giant’s engineering team explained how it built something called HydraBase to boost the reliability of the HBase data store to a mainframe-like 99.999 percent, or just five minutes of unexpected downtime per year.
Facebook has been using the HBase key-value store for a variety of applications since 2010. Attracted by HBase’s horizontal scalability, high read and write throughput, built-in availability features, and strong consistency, the company started using HBase for Facebook Messages, which integrates SMS, chat, email, and messaging applications. Since then, Facebook has expanded HBase into other areas, including its internal monitoring system, the “Nearby Friends” feature, search indexing, streaming data analysis, and scraping data into a warehouse.
With so much riding on HBase, it behooves the company to maximize the technology’s reliability and its resilience against failures. The company had been running HBase in a master-slave setup whereby data is asynchronously replicated from the master cluster to the slave clusters. While this setup provided some degree of resilience, it had limitations. For instance, failovers from the master to the slave had to be carried out at the cluster level, and failovers would take minutes to complete. And because of the asynchronous nature of the data replication, there was the potential to lose data.
To improve HBase’s availability, Facebook developed HydraBase, which offers a fairly thorough re-architecting of a typical HBase topology. As the Facebook engineering team explains in a recent blog post, HydraBase provides higher availability (from 99.99 percent to 99.999 percent), greater data consistency, and faster failover times than the master-slave replicated setup. The technology is able to do this, without expanding the storage footprint, by effectively “decoupling” the logical and physical replication in HBase, Facebook says.
“Instead of having each region being served by a single region server,” the Facebook engineering team writes, “in HydraBase, each region is hosted by a set of region servers. When a region server fails, there are standby region servers ready to service those regions. These standby region servers can be spread across different racks or even data centers, providing availability across different failure domains.”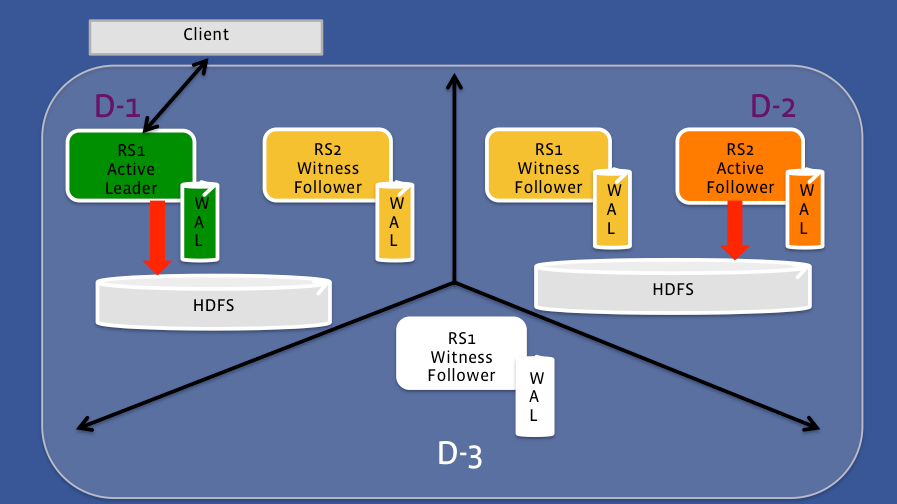
In a typical master-slave replication scenario, there are just two servers: masters and slaves. When the master fails, the slave steps up to perform the work of the master. In HydraBase, Facebook has added another level of resilience to the system by effectively giving the master and the slave nodes their own built-in shadow servers that are ready to step up if needed.
There are at least three servers in a HydraBase group, or quorum, of servers, and three types of servers within that quorum, including active leaders, active followers, and witness followers. The active leader (i.e. the master) has its own witness follower, the active follower (i.e. slave) has its own independent witness follower, and there is a third witness follower for good measure.
The active leaders in HydraBase will do the work of writing data to the in-memory write ahead logs (WALs), performing data flushes from the WAL to HDFS as an HFile, and doing compactions on HDFS to reduce the overhead of reads. The witness node members are only replicating the WALs, but don’t do the other stuff, until they’re called on to replace a failed active member.
In HydraBase, the number of servers in a quorum can be expressed as 2F+1, where F stands for the number of failures the group can withstand. When an active leader dies, its corresponding witness follower immediately kicks in. The fact that it’s been replicating the WALs that eventually get written to HDFS helps to minimize downtime during the failover process here. If the active follower and the witness follower are located in the same data center, and the entire data center goes down (i.e. two failures), having the other three members of that five-member quorum will ensure that the cluster keeps running.
“With HydraBase, we can now fail over at the granularity of a single region,” Facebook’s engineering team writes. “Moreover, the failover time is shorter because we no longer need to do log splitting, given that the corresponding write-ahead logs are already on each hosting region server.”
Facebook plans to roll out the new HydraBase feature to its production Hadoop cluster in the near future. It’s unclear if the company will release HydraBase into the open source community, but it wouldn’t be surprising if it did.
Related Items:
Facebook Drills In Big Data Thinking at Bootcamps
Facebook’s Super Hive-Killing Query Machine Now Yours
How Facebook Fed Big Data Continuuity
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
Call & Contact Center Expo
 April 24 - April 25Las Vegas NV United States
April 24 - April 25Las Vegas NV United States -
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States