

May 19, 2014
Tamr Whips Semi-Structured Data Into Shape

Big data startup Tamr today came out of stealth mode with a new product that leverages predictive algorithms and crowdsourcing from subject matter experts to automate much of the work of transforming semi-structured data so it can be more effectively utilized in analytic systems. The company, which is headed by Vertica founders Andy Palmer and Mike Stonebraker, has already chalked up some big-name customers, like Novartis and Thomson Reuters.
The premise for the Tamr product is a familiar one–namely that enterprises are struggling to incorporate highly variable data into their analytic processes without incurring massive manual efforts on the part of humans. That approach simply doesn’t scale, and is a major hurdle in the big data projects at many companies.
Traditional ETL and data curation processes work fine when a company has several dozen of different data types in play, and if those data types are largely structured, Tamr CEO Palmer says. But when you start talking about mixing data from thousands of different data sources, and those sources are loosely structured and possess a high degree of variety, then the automated ETL processes break down and you’re back to manually stitching the sources together.![]()
The net of this is that companies aren’t getting full use out of the data scientists they hire. “They’re supposed to focus their time, energy, and effort on analysis, but instead what they do is spend a lot of their time doing manual data collection and preparing,” Palmer tells Datanami. “It takes a long time to get from start to finish on any project. And as you hire more data scientists, the problem only gets worse.”
For the past four years, Palmer, Stonebraker, and others have been working on Tamr, which originated as a research project in Stonebraker’s graduate class at MIT. Today, the Cambridge, Massachusetts-based company announced that the product is generally available. It also announced $16 million in venture funding led by Google Ventures and New Enterprise Associates (NEA).
There are two main components to the product, which runs on scale out databases such as Postgres, Vertica, and Hbase (the product doesn’t yet run on HDFS, although that is in the roadmap). First, the software uses machine learning and predictive algorithms to automate the process of transforming semi-structured data into something that’s more usable and useful. The second key component is a unique collaboration mechanism that reaches out to human subject matter experts for guidance when the algorithms don’t work as expected. The results of the transformation are exposed through a REST API.
The combination of the algorithms–which can correctly map and match about 90 percent of data sources, the company says–and the human outreach provides a potent one-two punch for knocking out stubborn data transformation and data curation challenges, Palmer says.
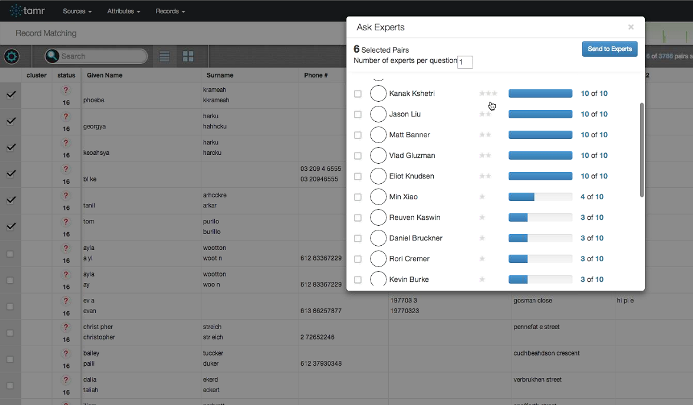
Tamr automatically keeps track of the subject-matter experts available to answer questions about data.
“Under the covers, our system takes in sources that are either structured or semi-structured. The lowest common denominator is something that looks like a CSV file. We run our algorithms against them both on a first-time and continuous basis, to monitor any changes that occur in those sources,” he says.
“And then based on algorithms, we develop a confidence interval for the mappings between the different attributes for these sources, and the matching between the different records,” Palmer continues. “Then our system looks out at a panel of experts–many times those experts being the people who own the sources in the first place–and ask them to help increase the confidence interval between the mapping of the attributes and the matching of the records. It’s this collaborative curation of the data at scale that really helps improve the quality and precision of the data over time.”
Some of the early development on Tamr was done with Novartis, the $59-billion pharmaceutical company. As Stonebraker explains, Novartis struggled to incorporate the bench notes of its team of 10,000 chemists and biologists into a centralized reporting structure.
“Novartis has their traditional customer facing data in a traditional data warehouse loaded using an ETL tool,” he says. “That does their top 20 or 30 data sources. But they’ve got at least 10,000 of what I’ll call the long tail data sources. There’s tremendous value in the long tail data.”
However, that long tail data can be tough to crack. Relying on programmers to configure an ETL tool to know the difference between, say, the term ICU50 and the term ICE50 is simply not feasible. That’s where Tamr’s approach of tapping into the knowledge of human experts is potentially powerful.
“There’s gold in them hills,” Stonebraker says of high-variety “long-tail” data sources from the Web and the IoT.
“They’ve made a crowdsourcing system that will ask experts such curation questions,” Stonebreaker says. “So basically what we designed is a scalable data curation system that completely reverses the typical ETL architecture. There’s not a human programmer with a bag of tricks. It’s an automated system that asks human experts only when necessary.”
Thomson Reuters is another early Tamr customer with positive results. The $12.7-billion news and information services firm employs 500 data curators whose job is to aggregate and transform data from a variety of sources so it can be repackaged and sold.
After deploying Tamr, Thomson Reuters was able to reduce the amount of manual effort by 90 percent, Palmer says. “The result is a radical increase in productivity among the 500 curators and enable those folks to work on highly value add tasks that were really challenging and interesting as opposed to the mundane stuff that they had to do over and over again, that now the Tamr system is doing for them,” he says.
While it physically resides on a scale-out database like Vertica, logically the Tamr product sits downstream of the actual data source and upstream of the analytic engine or other consumption point. Palmer envisions Tamr being particularly useful in demystifying the data held in NoSQL database stores, such as MongoDB.
“We see an incredible challenge in the variety [of data] with the proliferation of MongoDB in the enterprise,” Palmer says. “Many of these MongoDB installs have semi-structure to them. They don’t have really good structure. As a result, running something like Tamr against those sources, oftentimes helps you rationalize or understand all the data that exists across these various JSON data sources.”
Tamr will also find use in any outfit that struggles to makes sense of sensor data from the Internet of Things, clickstream data, or the huge amount of publicly available data, which many customers are storing away in Hadoop clusters.
“We expect to ingest upstream data sources, which may come from the Internet of Things or from the public Web or enterprise databases, and we expect to populate a downstream storage engine, whether it’s Vertica or Data Gravity,” Stonebraker says. “Integrating the rest of your data along with public data source from the Web and the IoT–that’s what we do. That’s what we’re completely focused on. We find that essentially every enterprise on the planet has our problem.”
If Tamr sounds a bit like what Trifacta has done with its recently released product, then pat yourself on the back because you are paying attention. “Joey [Trifacta co-founder Joe Hellerstein] was one of Mike’s grad students,” Palmer points out, and actually collaborated a bit with the Tamr team.
However, the products are not in direct competition, as Trifacta’s software is aimed at lone data scientists working with a small number of data source, whereas Tamr involves itself with many users and many sources of data. “We think [Trifacta’s product] is compelling and complementary to what we do,” Palmer says.
Related Items:
Big Data Going to Waste, Study Finds
Forget the Algorithms and Start Cleaning Your Data
Five Steps to Drive Big Data Agility
Applications:
Data Mining
Technologies:
Middleware
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
Call & Contact Center Expo
 April 24 - April 25Las Vegas NV United States
April 24 - April 25Las Vegas NV United States -
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States