

April 11, 2014
Faceboook Gets Smarter with Graph Engine Optimization
Last fall, the folks in Facebook’s engineering team talked about how they employed the Apache Giraph engine to build a graph on its Hadoop platform that can host more than a trillion edges. While the Graph Search engine is capable of massive graphing tasks, there were some workloads that remained outside the company’s technical capabilities–until now.
![]() Facebook turned to the Giraph engine to power its new Graph Search offering, which it unveiled in January 2013 as a way to let users perform searches on other users to determine, for example, what kind of music their Facebook friends like, what kinds of food they’re into, or what activities they’ve done recently. An API for Graph Search also provides advertisers with a new revenue source for Facebook. It’s likely the world’s largest graph implementation, and a showcase of what graph engines can do.
Facebook turned to the Giraph engine to power its new Graph Search offering, which it unveiled in January 2013 as a way to let users perform searches on other users to determine, for example, what kind of music their Facebook friends like, what kinds of food they’re into, or what activities they’ve done recently. An API for Graph Search also provides advertisers with a new revenue source for Facebook. It’s likely the world’s largest graph implementation, and a showcase of what graph engines can do.
The company picked Giraph because it worked on their existing Hadoop implementation, including HDFS and its MapReduce infrastructure stack (known as Corona). Compared to running the computation workload on Hive, an internal Facebook test of a 400-billion edge graph ran 126x faster on Giraph, and had a 26x performance advantage, as we explained in a Datanami story last year.
When Facebook scaled its internal test graph up to 1 trillion edges, they were able to keep the processing of each iteration of the graph under four minutes on a 200-server cluster. That amazing feat was done without any optimization, the company claimed. “We didn’t cheat,” Facebook developer Avery Ching declared in a video. “This is a random hashing algorithm, so we’re randomly assigning the vertices to different machines in the system. Obviously, if we do some separation and locality optimization, we can get this number down quite a bit.”
Well, Facebook has started that locality optimization work, and it’s starting to pay dividends. In a blog post last week, Facebookers Alessandro Presta and Alon Shalita discussed how the company optimized its graph to enable computations that were previously difficult to process without incurring high latency.
The problem with randomly sharding information about Facebook users in a multi-node cluster is that the connections between Facebook users are not random. People have a certain group of friends who are closely connected, and when you break these bonds by distribute them to randomly selected nodes in an n-tier cluster, queries must traverse those nodes, which leads to an increase in network traffic, which leads to an increase in latency.
 |
|
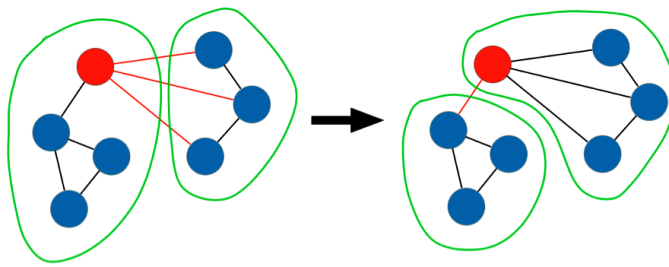
| By grouping connected vertices on the same server, Facebook can reduce latency in its Graph Search engine | |
So instead of randomly distributing the Facebook users and their data, Facebook needed to figure out a way to keep the cliques relatively intact. The question is: How do you do this in a cost-effective and efficient way, without allocating too many people to the same machine and creating new bottlenecks?
The answer, as Presta and Shalita explains, has multiple parts. “The high-level strategy behind our algorithm is not new: start with an initial balanced partitioning, and then iteratively swap pairs of vertices in a way that increases local edges [see Kernighan–Lin_algorithm]. We borrowed some key ideas from an algorithm previously developed at Facebook by Lars Backstrom and Johan Ugander called balanced label propagation. In order to make it faster on our largest datasets, we adapted it to fit Giraph’s model of distributed computing.”
Each vertex sends messages to its neighbor vertexes to see how many of its neighbors are assigned to each partition. If a partition contains many more neighbors than the current one, the vertex may choose to relocate to another server to keep the workload in balance. But instead of immediately moving (which could produce an imbalance all by itself), the vertexes will first communicate their desire to move, and a centralized controller determines when and where to move, the Facebookers say.
“A useful property of this algorithm is that, as new users join and form new connections, we can incrementally update the partitioning with minimum effort–we simply initialize the algorithm with the previous partitions [e.g., computed the day before] and run it on the new version of the graph,” Presta and Shalita write. “Within a couple of iterations [typically one suffices], the original edge locality is restored.”
 |
|
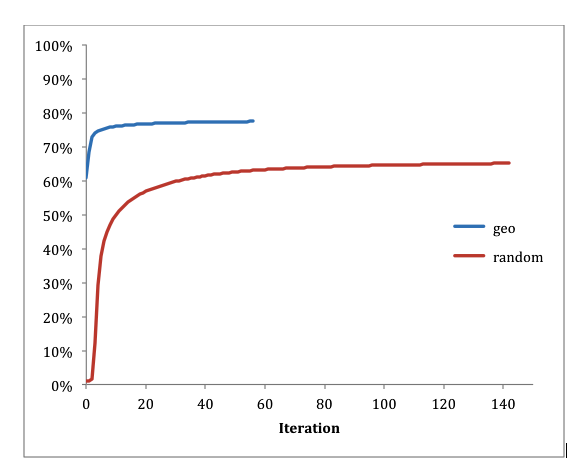
| Starting the graph with geographic groupings instead of random assignments reduced the number of iterations necessary to achieve balance | |
To get the graph started, the company chose to assign users to nodes in the 200-server cluster based on geographic proximity. This works well, because Facebook users tend to be friends with people who they live close to. “With random initialization, the percentage of local edges went from 1 percent to 65 percent in 137 iterations,” Presta and Shalita write. “When initialized using geographical information, the starting point was 60.8 percent local edges, which our algorithm improved to 76 percent in just 10 iterations and 77 percent within 31 iterations.”
This technique can be applied in other areas too. For example, Facebook used Giraph to run the PageRank algorithm using 100 servers in the node. According to Facebook, each iteration of the PageRank algorithm took an average of 363 seconds using standard hash-based partitioning, whereas it took just 165 seconds using its special portioning technique. That’s a 2x speedup.
Facebook’s tech team says others can emulate the tweaks they made to boost the performance of their own graphs. “It can be run on any graph in principle, but it’s mostly beneficial with sparse graphs that exhibit some kind of community structure. Many real-world graphs are like that,” Presta and Shalita tell Datanami via email.
Graph datasets in general can benefit from this kind of partitioning, they say. “Even if the system is not serving the data in a graph format (vertices and edges), but the underlying data elements are related to each other in a form that can be described as a sparse graph, then balanced partitioning can help optimize that system (e.g. in terms of fanout, cache efficiency, utilization of memory hierarchies, etc.),” the Facebookers say.
Graph engines are becoming a very popular way to process big data, particularly big social data. The groundbreaking work that Facebook is doing with graph can be a benefit to others as they ramp up their graph initiatives.
Related Items:
Facebook Graph: More Than a Trillion Edges Served
Data Science Has Got Talent as Facebook Launches Competition
Facebook Advances Giraph With Major Code Injection
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States