

March 5, 2014
Avoiding Big IT Outlays with Cloud-Based Analytics
If your organization has adopted a big data strategy, chances are good that it’s also making big capital outlays to support that strategy. One firm that’s hoping to short-circuit the hardware and software investment cycle is GoodData. Today the San Francisco company announced the addition of Hadoop to its cloud-based big data analytics stack, giving it the capability to ingest and store a whole new level of data.
![]() GoodData was founded seven years ago with the idea of giving customers mashups that used data stored in their cloud-based apps. The software as a service (SaaS) market was just beginning to heat up, and Roman Stanek, the CEO and founder of GoodData, realized a good living could be made pulling data from clients’ Salesforce.com and Marketo implementations, combining it with data from other sources, and presenting it to them via intuitive Web-based dashboards.
GoodData was founded seven years ago with the idea of giving customers mashups that used data stored in their cloud-based apps. The software as a service (SaaS) market was just beginning to heat up, and Roman Stanek, the CEO and founder of GoodData, realized a good living could be made pulling data from clients’ Salesforce.com and Marketo implementations, combining it with data from other sources, and presenting it to them via intuitive Web-based dashboards.
A few years later, when the fascination with Web 2.0 sort of morphed into big data, GoodData evolved and starting delivering pre-built analytic capabilities for sales and marketing organization. Backed by venture capital firms like Andreessen Horowitz, the company started investing more in big data R&D.
The company developed something called “multi-dimensional analytics query language,” or MARQL, to access data stored in its proprietary data engine, which combines traditional SQL and ROLAP (relational online analytics processing) technologies and in-memory processing adopt an HP Vertica column-oriented database. It developed its own data connectors, ETL, data cleansing, integration, and visualization layers. It added support for R and predictive and prescriptive analytics.
In short, it developed its own big data analytics stack–all engineered to run in the cloud, without much (if any) assistance from your IT organization.
It’s all about driving insight from data as quickly as possible, says GoodData’s new head of marketing Jeff Morris. “We created this end-to-end, fully operationalized analytic platform as a service that goes from whatever data governance activities your organization is going to have, to supporting whatever data discovery activities your end user are going to require,” he tells Datanami.
Heap Big Data
It’s common knowledge that data volumes are getting bigger. But some may not be aware that the rate of growth is also itself getting bigger. This sort of geometric growth in data is a huge concern for many in the IT community–especially those tasked with storing and managing that data. But for the folks at GoodData, that data growth presents a market opportunity.
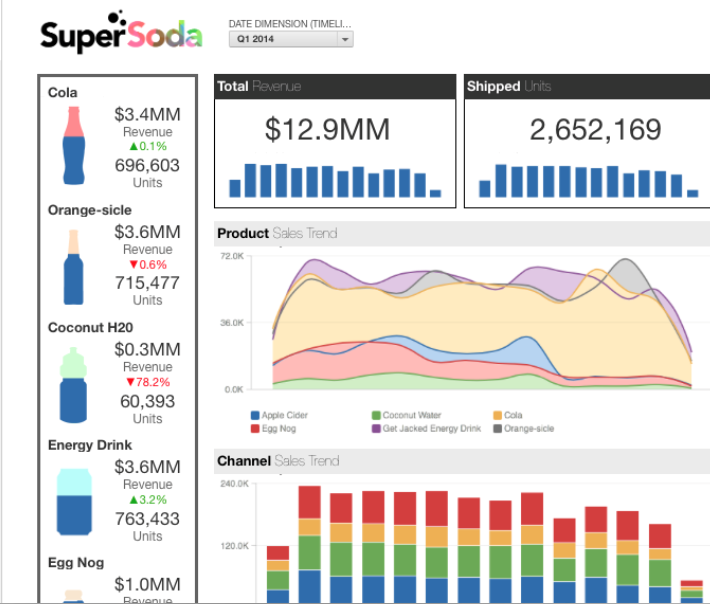 |
|
| An example of a GoodData dashboard | |
“We look at the world from the standpoint that customers are just not using enough data,” Morris says. “They should be using more to gain competitive advance and to make sure they’re serving their user communities in as agile a manner as possible.”
Saying “you know, we really just don’t have enough data” might be grounds for a 48-hour psychiatric hold in your typical IT organization that’s drowning in data. But with GoodData, customers don’t have to worry about the drudgery of data management, and instead can skip right to the fun, value-add part.
“With GoodData, you get to focus on your data model and on cleaning up the data. These are the activities you’re supposed to be doing and adding value to your organization,” Morris says. “You focus on the analytics you’re presenting to your end users and the ways you’re presenting it to them. We give you a log-in to that environment and eliminate all the administrative overhead. We’re managing everything that’s operating upon your data, but allowing you the opportunity to focus on the value that the data you’re putting into the system offers.”
Riding Hadoop
The data volumes that GoodData manages for customers at Rackspace will go up considerably as a result of today’s unveiling of the Open Analytics Platform. The big takeaway of this launch is that GoodData is positioning itself as an all-purpose analytics platform for enterprise-level organizations. The days of serving simple mashups of sales leads and forecast for data housed in Salesforce.com are long gone.
 As part of the Open Analytics Platform, the company has adopted Hadoop to be both a place to ingest large amounts of data, but also to be a long-term data archive. “It’s the staging area and archive at the same time,” Morris says. “We load it all in, snapshot it, index it and add our own metadata tagging to it so we know where it came from, whose it was, what it contains.”
As part of the Open Analytics Platform, the company has adopted Hadoop to be both a place to ingest large amounts of data, but also to be a long-term data archive. “It’s the staging area and archive at the same time,” Morris says. “We load it all in, snapshot it, index it and add our own metadata tagging to it so we know where it came from, whose it was, what it contains.”
So far, the company is not doing a lot of processing with Hadoop. It provides some basic MapReduce jobs to extract meaning from unstructured data before loading it into the Vertica-based warehouse for analysis. But Hadoop is very important for supporting the data volumes–both streaming and bulk data loads–that GoodData expects to support.
Big data can be a big competitive advantage for those who leverage it correctly. For that reason, the biggest firms have elected to build and run their own big data infrastructures. As big data technologies mature, a standard stack will emerge, and the competitive advantage from running your own gear will decrease substantially.
As big data evolve, we’ve seen a standard stack starting to emerge. GoodData has done the grunt work of assembling the various pieces of this stack and running it for customers. And if a customer wants to run their own R algorithms, Tableau reporting tool, or homegrown ETL processes, GoodData lets them.
The company has been rewarded to the tune of 30,000 deployments and more than 130,000 users, about half of them via white-label and OEM deals through the likes of Twitter, Box, and Hootsuite. With a Series D round of funding last year, GoodData’s has $75.5 million to play with. It claims to be able to run a big data project at one-half to one-third of the cost of a typical data warehouse implementation. If you’re just getting started with big data, it probably makes sense to check out a cloud-based vendor, such as GoodData.
Related Items:
GoodData Strategizes for Big Data Monetization
To Hadoop, Or Not to Hadoop? That is the Question
A Peek Inside Cisco’s Hadoop Security Machine
Technologies:
Cloud
Vendors:
Startups and More...
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
Call & Contact Center Expo
 April 24 - April 25Las Vegas NV United States
April 24 - April 25Las Vegas NV United States -
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States