

February 27, 2014
Bridging the Old BI World with Big Data Analytics
We’re in the middle of a revolution in data analytics, where old beliefs and approaches are being discarded as new technologies emerge. One data analytics software company that’s aiming bridge the gap between the old and the new is Looker, which today unveiled new software designed to help companies retain the richness of big data without overwhelming users with all the gory details.
![]() The big data revolution has brought us amazing new technologies, like the massive parallelization of Hadoop, the incredible speed of column-oriented analytic databases like Vertica, and insanely accessible analytic DBs like RedShift (built on Actian’s technology). However, in the rush to adopt these technologies, organizations have neglected to address their basic informational needs, says Looker CEO Frank Bien.
The big data revolution has brought us amazing new technologies, like the massive parallelization of Hadoop, the incredible speed of column-oriented analytic databases like Vertica, and insanely accessible analytic DBs like RedShift (built on Actian’s technology). However, in the rush to adopt these technologies, organizations have neglected to address their basic informational needs, says Looker CEO Frank Bien.
“While they have answers for big data issues in Hadoop, solutions for the next SaaS replacements, or advanced analytic stuff in in R, they don’t have basic controls over their business data,” Bien tells Datanami. “We have transactional data coming out of our core systems. But we’ve just lost track of how to actually manage it and get value out of it.”
Software vendors are partly at fault for the disconnect, says Bien, the former Greenplum VP of BD who now heads the young Santa Cruz, California, startup. “We as technology vendors got interested in things that were intellectually challenging for us in this big data world, rather than what customers actually needed,” he says. “We’re routinely going into companies–billion dollar companies–and they don’t have control over inventory, they don’t have control over revenue predictions and things like that, because nobody’s implemented the old traditional BI tools anymore.”
You might as well implement a legacy BI product like SAP BusinessObjects, IBM Cognos, or MicroStrategy–or, gulp, install an AS/400 (now called IBM i for Power Systems), Bien says. “Nobody is doing that anymore.”
 |
|
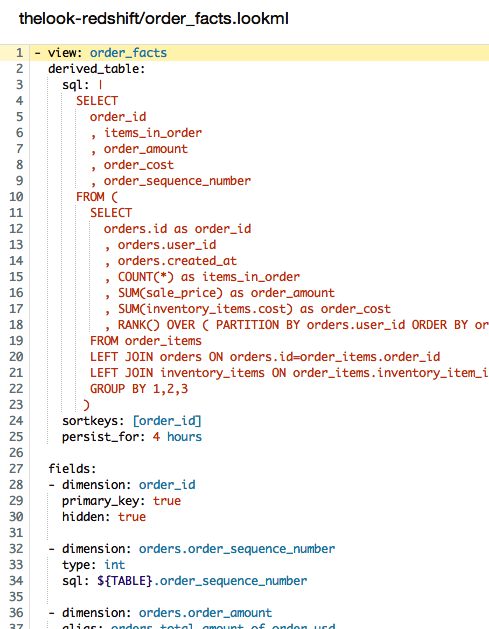
| An example of LookML code. | |
Instead, Looker is aiming to deliver the core informational control that those legacy BI products provided in the areas of revenues, inventory, and forecasts, but to do so in a much more automated way that’s fashioned for the brave new big data world. “It’s really about a new way that people can explore data with a different kind a lens,” he says. “We refer to it as a high resolution view into data.”
The company’s flagship Datafold Engine implements a development environment based on its LookML language, which works on top of SQL. The software itself is designed to reside within the relational databases–either traditional row-based databases like PostgreSQL, MySQL, or SQL Server, or new column-oriented and in-memory databases, like Greenplum, Netezza, Vertica, Vectorwise, or Amazon Redshift.
LookML allows people to reuse and componentize SQL, Bien says. “It’s a layer of abstraction on top of SQL that allows people to define elements of data, measures, and dimensions one time, and then re-use them across an entire data schema,” he says. When an organization has adopted Looker, the data analyst defines something one time, and “without even knowing about it, it becomes useful to people who want to use it in different ways.”
Looker avoids the traditional data warehouse approach that requires constant pulling and normalizing of data into a dedicated analytic system. Extract, transform, and load (ETL) is time-consuming and restrictive. Instead, Looker advocates the ELT approach–that is, extract, load, and transform in place. Instead of normalizing data when it’s loaded into the schema, the data is normalized at query time. Web-based dashboards deliver the final product directly to the end users.
“Business intelligence has been so non self-service because people have to go back and re-ingest data or go find stuff in these source systems and move it over into a Tableau or a MicroStrategy,” Bien says. “We say, look at how much easier it is to transform it at query time, as opposed to getting things perfect when they go in. Because the questions are always changing. The end user thinks they want X, but really when they start looking at it, they want Y.”
It’s all about delivering the same level of self-service that Tableau and QlikTech have successfully delivered, but doing it on bigger and more complex data sets, Bien says. “The self service tools from Qlik and Tableau got away from the modeling or understanding the inter-relationships of data by keeping what they service relatively simple,” he says. “What we’re doing is providing that level of simplicity but on much more complex data by enabling a new kind of data modeling.”
 |
|
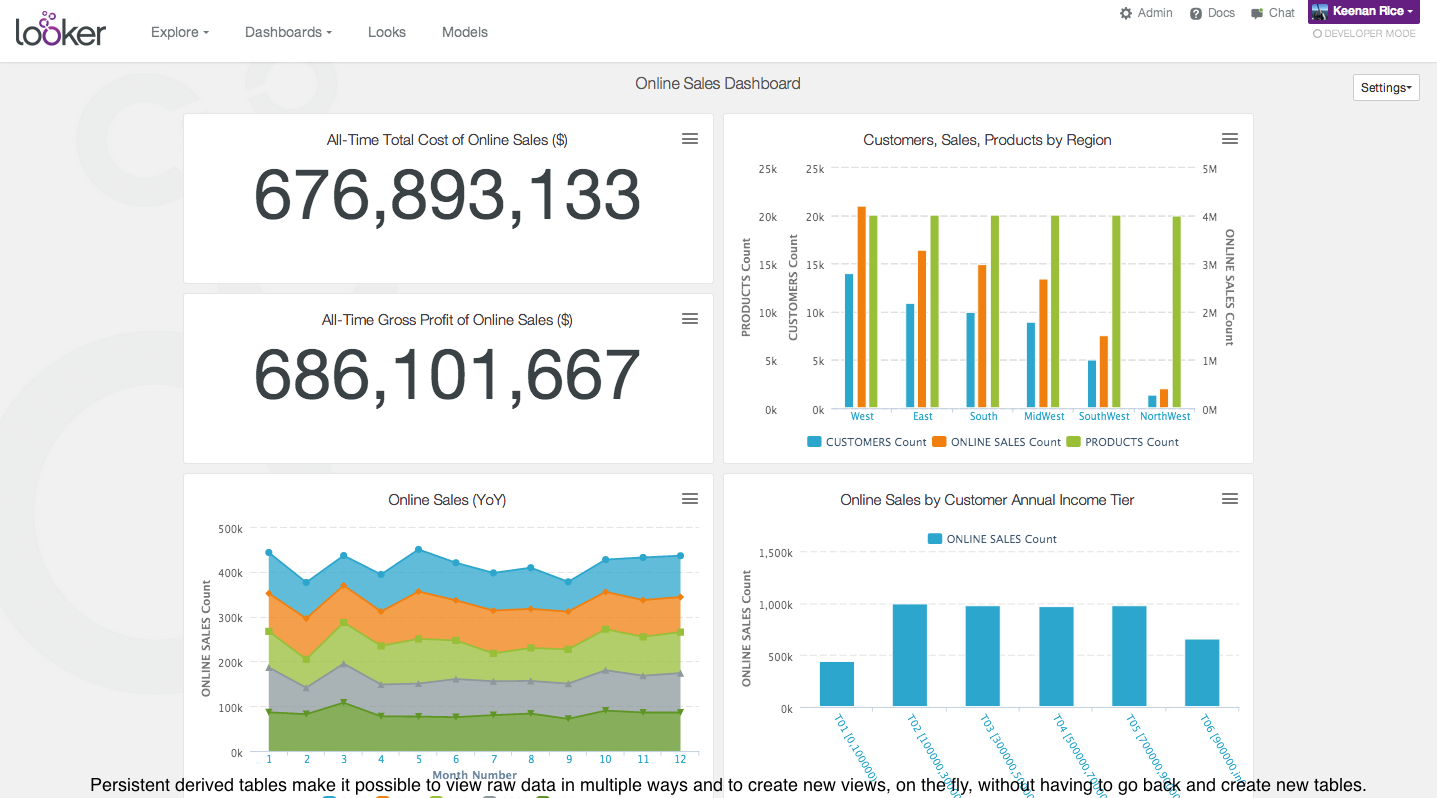
| The Looker dashboard interface. | |
Today, Looker announced support for persistent derived tables, which are data elements that provide easy access to models of complex raw data. Persistent derived tables are useful for delivering to the user metrics, such as “total lifetime value.” These metrics are really hard to calculate (and keep fresh) in a traditional data warehouse, because they pull from so many parts of the database, Bien says.
“Those are things that exist in strange ways in the database, and have to be derived,” he says. “Those are things that are represented in LookML. The data analyst, rather than writing SQL queries–which is what they’re doing today and exporting stuff into other tools–is simply embellishing a model that describes these data elements, then the end-user can consume those elements in our user interface and explore that data.”
Looker’s is an elegant approach to an age-old problem in business intelligence. The vendor isn’t the first to attempt to put an abstraction layer over data to make it easier to understand. But this approach definitely bears further exploration for customers who are feeling overwhelmed and worked over by their big data stores.
Related Items:
How Actian Plans to Take Over the Big Data World
HP Launches Veritca Marketplace
Amazon Goes SSD with RedShift ‘Dense Compute Nodes’
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States