

February 10, 2014
Enterprise-class real-time stream analytics for Big Data
Sponsored Content
The Problem
Since the beginning of the information age, enterprises have relied on processing data to gain insights and make business decisions. In the past decade, significant advances in technology have fostered the dramatic increase of data complexity in volume, variety, and velocity – the ‘three V’s’ of Big Data.
For example, 9 billion devices are connected to the Internet today– from laptop and desktop computers to tablets, smartphones, even home entertainment systems and thermostats. By 2020, that number is expected to be 50 billion. With such a dramatic increase in connected devices, a significant increase in data generation and processing will naturally follow.
This massive increase in data workloads has led to advances in new parallel processing frameworks that use distributed computing on distributed data sets, such as MapReduce on Hadoop. Hadoop, in turn, has seen rapid adoption because it is much cheaper than traditional mainframe proprietary storage solutions.
Even though the Big Data problem is addressed by Hadoop, enterprises still must wait many hours or even days for jobs to be done because of its batch nature. At the same time, enterprises are finding that they need to get their data insights earlier and earlier to stay competitive. The sooner the data insight, the more valuable it is to the business. While there are recent tools to make “real-time queries” in Hadoop, the data must first go through a batch job before queries can be made. For many enterprises, this is too late. To extract the maximum benefit that data can provide, enterprises need to derive insights seconds after that data arrives.
The Need
There are many use-cases for Big Data processing in real-time. Here are a few examples:
- A financial services organization, such as a credit card company, has a 2% fraudulent transaction ratio, resulting in a loss of hundreds of millions of dollars every year. With real-time streaming analytics, they discover patterns and certain indicators that enable detection of those fraudulent transactions and subsequently reduce the fraud rate by half. This would be the ROI in enterprise-class, real-time streaming analytics.
- An online retailer finds that improved product offerings to certain buyers’ segments would result in double the transaction size from its online store. Being able to improve product recommendations or even pricing to certain visitors with the help of data generated and analyzed in real time has a direct impact on the business’ revenue.
- In telecom and networking, real-time call data record (CDR) processing and real-time network monitoring and protection can help organizations instantly discover if calls are being dropped or if capacity has suddenly been reduced, allowing them to take immediate corrective actions that keep connectivity in place and ensure minimal (if any) downtime for the phone system.
Enterprises with these types of applications need the ability to ingest massive amounts of structured and unstructured data, perform arbitrary processing logic to calculate key performance indicators (KPIs), detect current or potential anomalies, and take corrective actions within sub-seconds of the triggering events. This necessity has given rise to an exciting new type of platform that combines Big Data with real-time stream processing. However, to truly support the mission-critical services of the enterprise, a platform such as this must overcome eight key challenges:
1. Ultra-fast Performance
The platform should be able to handle throughput of up to billions of events per second, with latencies in the sub-seconds.
2. Scalability
All streams of data should be expected to grow, and the platform ought to be able to scale linearly with them. Any substantial and consistent increase in data volume, variety, or velocity should be facilitated by adding more nodes to the cluster with minimal diminishing returns.
3. Fault Tolerance
There are bound to be node outages and service disruptions in any distributed computing environment. The platform should be able to automatically compensate for these occurrences without data loss, state loss, or human intervention. A robust checkpointing and recovery mechanism is an absolute must-have.
4. Dynamic Load
Many data streams experience peaks and lulls throughout the day. The platform should be able to dynamically scale horizontally with this ebb and flow in order to conserve energy and resources.
5. Run-time Application Changes
Applications relying on continuous streams are, by definition, long-running or even never-ending. This means that stopping and starting an application in order to make small changes may prove very costly for many enterprises. The platform should allow for reasonable changes to the application logic at run-time to avoid such interruptions.
6. Support Complex Algorithms
Most real-world applications are not simple, and require significantly complex logic. Application developers should not be limited by a restrictive API that limits their capabilities. Ideally, a developer should be able to harness the power of an established programming language and/or paradigm to build out their business logic.
7. Security
Any software used in earnest by large enterprises must be highly secure. The platform should rely on industry-standard technologies and best practices for authentication and authorization mechanisms.
8. Easy to Write and Maintain
Long-lasting, successful applications can only be possible if they are easy to write and maintain. Developers should never have to write code that manually accounts for any of the previous requirements in this list. They should only be concerned about the business logic of their application, and the platform should do the rest.
The DataTorrent Solution
DataTorrent (www.datatorrent.com) has been built from the ground up with these eight principles in mind. Processing billions of events per second with sub-second latency, the platform’s unparalleled performance and enterprise-grade capabilities make it the most powerful platform for real-time analytics on a massive scale. By harnessing the power of Hadoop 2.0’s cluster resource management component, YARN, DataTorrent can scale outwards to meet any data size requirement. Additionally, as a native Hadoop application it enables enterprises to leverage their investments in Hadoop for real-time computations.
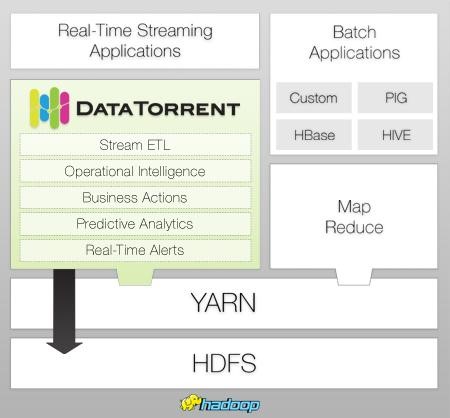
Fault-tolerance is covered: Highly efficient and distributed automatic state snapshot recorded to HDFS enables checkpointing with minimal impact on latency. When an application’s load increases at run-time, logical units of that application (called operators) are automatically partitioned to accommodate for the change. Conversely, partitioned operators are merged when load decreases to a lower level. Changes can be made to an application’s behavior at run-time, allowing for long-running applications to be updated without redeployment. Application code is written entirely in Java, which provides the developer with all the tools he/she is accustomed to when implementing complex algorithms. Further, DataTorrent is continuously building a library of open-source operators, reducing the work required by application developers. As for security, DataTorrent uses the Kerberos Protocol for authentication, which is the protocol used by Hadoop itself.
The time for Big Data real-time stream analytics has arrived. With new stream processing technology options available, it is crucial for enterprises to choose the platform that possesses all the capabilities required to deploy production-quality applications.
Vendors:
DataTorrent
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States