

February 4, 2014
Shining a Light on Hadoop’s ‘Black Box’ Runtime
Let’s face it: Writing MapReduce processes is not very fun. That’s the main reason that the Cascading framework is gaining such a big following–because it abstracts away the difficult part of MapReduce with an easy-to-use Java API and library. With today’s launch of a new product called Driven, the company behind Cascading is enabling users to instrument the data analytic apps developed with Cascading, in pursuit of faster troubleshooting and higher performance.
![]() There is some serious momentum building up behind Cascading. According to Concurrent–the commercial open source company founded by Cascading creator Chris Wensel to sell support for Cascading–the open source framework is being downloaded 130,000 per month. What’s more, 6,000+ companies have deployed Cascading-built applications on production Hadoop clusters, including big names like Twitter, Kohl’s, and Nokia.
There is some serious momentum building up behind Cascading. According to Concurrent–the commercial open source company founded by Cascading creator Chris Wensel to sell support for Cascading–the open source framework is being downloaded 130,000 per month. What’s more, 6,000+ companies have deployed Cascading-built applications on production Hadoop clusters, including big names like Twitter, Kohl’s, and Nokia.
The way that Cascading allows mortal Java developers with average skills to build MapReduce-based applications that would normally require a super Java coder to construct has made Cascading a staple component of many Hadoop projects. “Being a Java API, the average Java developer can use it,” Wensel tells Datanami. “They can write tests and use their IDE. But also more importantly, they can think about the problem at hand and they don’t have to think in terms of MapReduce, MapReduce, MapReduce.”
While Cascading has helped many organizations build data analytic apps that run on Hadoop, the framework doesn’t address the overall lack of visibility into the inner-workings of Hadoop apps once they’re placed into production.
“One of the big problems in Hadoop today is it’s just a black box,” says Concurrent CEO Gary Nakamura. “Most people today deploy their applications and pray. What we’re doing [with Driven] is providing the visibility so you can actually see what’s going on, and if there’s a failure, we’ll take you to the exact spot that failure happened, so a developer can try and figure out what to do.”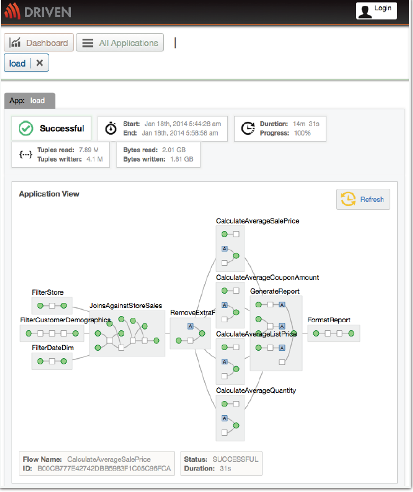
From its GUI, Driven will show users exceptions and track traces in their Hadoop app, and track all the filters, joins, and other functions that are taking place within the software. “You’ll be able to see all of the details in your data application, the units of work and how it all ties together,” Nakamura says. “You’ll be able to see them in real-time, running on Hadoop, and see how your application is progressing.”
Nakamura says the software will help users, operators, and developers collaborate on improving their Hadoop applications–not only with broken apps, but with the working apps that could use a little optimization.
“We expect Driven to provide the capability to build more reliable applications,” he says. “Developers and operators will be able to look at those things and say, ‘Hmmm, we should have somebody take a look at this because everything else takes 5 minutes and this takes 25 minutes. We ought to be able to optimize that down to something more reasonable.'”
As Cascading grows in use, so will Driven, Nakamura syas. “The next version [3.0] of Cascading will support other fabrics like Spark, Storm, and Tez,” he says. “So that means applications that have been built using Cascading will be portable across the supported frameworks, across the supported fabrics.” As these Cascading-developed applications start moving to different fabrics, Driven will follow and provide the same type of troubleshooting and optimization capabilities.
The first release of Driven will focus on helping developers monitor, debug, and set alerts on their Hadoop apps. Later, Concurrent will add more operational capabilities to their Hadoop jobs, including setting service level agreements (SLAs), enforcing quality of service (QoS), and ensuring the integrity of data lineage.
The first beta release of Driven is available now as a cloud service. The service is free for development use. A paid enterprise version is in the works that will support production use and be installable on-premise; it’s expected in the second quarter.
Driven supports Cascading version 2.08 (it’s currently at version 2.5) and includes popular domain specific languages like Lingual (ANSI SQL), Pattern (PMML), Scalding (Scala), and Cascalog (Clojure).
Related Items:
The Future of Hadoop Runs on Tez, Hortonworks Says
Concurrent Completes the Big Data Hat Trick for Hadoop Applications
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
Call & Contact Center Expo
 April 24 - April 25Las Vegas NV United States
April 24 - April 25Las Vegas NV United States -
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States