

November 7, 2013
Facebook’s Super Hive-Killing Query Machine Now Yours
Move over Hive. Facebook this week contributed Presto, its new in-memory distributed query engine that is up to 10 times faster than Hive, into the open source realm. With Presto, the social media giant gave itself a way to query its 300-petabyte data warehouse spread across a massive distributed cluster in sub-second manner. And now it can be yours too.
![]() Facebook isn’t one to cast aspersions on Hive, which is really just such a stupendous piece of coding. After all, Facebook originally created Hive back a few years ago to provide an SQL-like engine to query data stored in Hadoop. If you check the Facebook Engineering timeline, you’ll see how awesome Hive was back in the day. Really.
Facebook isn’t one to cast aspersions on Hive, which is really just such a stupendous piece of coding. After all, Facebook originally created Hive back a few years ago to provide an SQL-like engine to query data stored in Hadoop. If you check the Facebook Engineering timeline, you’ll see how awesome Hive was back in the day. Really.
But as Facebook’s data warehouse approaches the exabyte zone, Hive’s batch-oriented architecture was simply becoming too slow for Facebook’s data analysts, according to Martin Traverso, who works at Facebook Engineering. On a good day, an analyst could run maybe six queries using Hive, which works by converting SQL queries into MapReduce jobs that run in batch.
“We try to move fast,” Traverso said in a presentation he gave in June. “There’s a huge need for being able to run queries that produce results very quickly. Historically our analysts have relied on Hive. The problem with Hive is that it’s designed for batch processing. So it’s not a good fit for these kinds of low-latency queries.”
Facebook started developing Presto in 2012, and put it into production this year. The software is already proving itself in production workloads. According to Traverso, 850 Facebook analysts use it every day to run an average of 27,000 queries that process an average of 320 TB of data. It has showed itself capable of returning sub-second responses to simple queries against a data warehouse running on a cluster with more than 1,000 distributed nodes, while more complex queries return in several seconds.
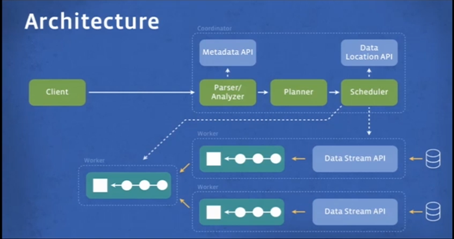
Presto is eight to 10 times faster than Hive, and four to seven times more CPU efficient, Traverso says. How did Facebook do it? “With Presto, we don’t use MapReduce,” he says. “Instead we built a special purpose query execution engine that uses high-level operators and is aware of the semantics of SQL. So that gives us a bit more freedom on the kinds of optimizations we can do, and allows us to [make] better decision in terms of when and where to execute things.”
Presto in-memory execution also gives it an edge over Hive, which uses MapReduce to write data to disk. “Once the data is loaded from the source, it gets processed, buffered in memory if necessary, and then forwarded on to the next worker in the pipeline,” Traverso says. “By avoiding all this unnecessary I/O, we can reduce latency.”
Presto’s unique data pipeline also reduces latency compared to Hive. “Presto can start all the stages at once and can stream all the data through the stages, so they can run concurrently,” Traverso says. “This type of pipeline allows for lower latency for huge number of queries that can take advantage of it.”
Facebook wrote Presto in Java, like much of the Hadoop clan. But for some of the parts of the query, Presto compiles directly to byte code, which allows the JVM to generate machine code that provides much more efficient execution than traditional Java programs. The company was also very careful in how it treats data in memory, which minimizes garbage collection issues that terrorize many poorly written Java apps.
Facebook is in the process of replacing all of its Hive instances with Presto. To that end, it developed plugins and a series of APIs that allow it work with Hive, as well as other query engines. “We decided Presto would be extensible,” Traverso says. “This is not just in terms of allowing people to write custom functions, like with Hive. But it’s also being able to integrate with other external systems.”
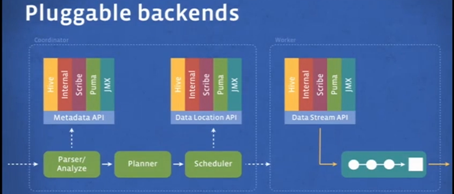 Presto currently supports a large subset of ANSI SQL, “including joins, left/right outer joins, subqueries, and most of the common aggregate and scalar functions, including approximate distinct counts (using HyperLogLog) and approximate percentiles (based on quantile digest),” Traverso writes in a Facebook Engineering post. “The main restrictions at this stage are a size limitation on the join tables and cardinality of unique keys/groups. The system also lacks the ability to write output data back to tables (currently query results are streamed to the client).”
Presto currently supports a large subset of ANSI SQL, “including joins, left/right outer joins, subqueries, and most of the common aggregate and scalar functions, including approximate distinct counts (using HyperLogLog) and approximate percentiles (based on quantile digest),” Traverso writes in a Facebook Engineering post. “The main restrictions at this stage are a size limitation on the join tables and cardinality of unique keys/groups. The system also lacks the ability to write output data back to tables (currently query results are streamed to the client).”
Facebook is working on eliminating the restrictions on joins, aggregation sizes, and output type. It’s also working on a “query accelerator,” that will introduce a new data format that’s optimized for query processing.
The Presto code is available for download at https://github.com/facebook/presto.
Related Items:
Facebook Graph: More Than a Trillion Edges Served
Data Science Has Got Talent as Facebook Launches Competition
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States