

November 4, 2013
Making Hadoop Into a Real-Time SQL Database
One of the great things about Hadoop is that it’s open source, which allows developers of all stripes to lash their code to the beast and give it a whirl. One of the big data software startups riding Hadoop is the San Francisco company Splice Machine, which claims to have built the industry’s first real-time, transactional, SQL-on-Hadoop database.
![]() Hadoop rose to prominence several years ago for its capability to run massively parallel analytic workloads in a batch environment. Today we’re seeing Hadoop evolve in other directions, especially with the advent of the HBase NoSQL database that can ride atop Hadoop and provide real-time transactional capabilities. SQL is also getting bigger on Hadoop through Hive and other open source and commercial projects.
Hadoop rose to prominence several years ago for its capability to run massively parallel analytic workloads in a batch environment. Today we’re seeing Hadoop evolve in other directions, especially with the advent of the HBase NoSQL database that can ride atop Hadoop and provide real-time transactional capabilities. SQL is also getting bigger on Hadoop through Hive and other open source and commercial projects.
But according to the folks at Splice Machine, what the market really needs is a way to bring all these capabilities together in seamless manner. If Hadoop is going to be the center of the big data universe–and it certainly seems to be heading in that direction, if Cloudera gets its way with its enterprise data hub strategy–then getting Hadoop to run in a real-time manner, speak SQL, and deliver the consistency of a standard relational database would be good things to have.
Splice Machine says its eponymous offering answers that need. Its offering, which is still in beta, actually runs on top of HBase. On top of HBase, it adds the Apache Derby relational database to deliver the foundations of a SQL parser, planner and execution system. And then on top of that, it provides its own secret sauce–a distributed transaction execution engine that provides the ACID-icity and transactional consistency to run atop HBase and access the big data lake at the bottom of the stack.
“In a nutshell, we build the only real-time transactional SQL in-Hadoop database,” Splice Machine CEO Monte Zweben tells Datanami. “It allows our customers to scale to the petabytes and still get real-time performance to power their big data applications.”
So, why exactly does Splice Machine take this approach? What’s the matter with HBase?
According to Zweben, HBase is great at providing a scalable real-time layer, but it has shortcomings that prevent it from being more widely used. For starters, it doesn’t have a declarative query language. “So therefore you can’t leverage the SQL tools in the organization. You can’t leverage the SQL code and SQL training,” he says. Getting a SQL layer on top of HBase is critical because SQL is the “paradigm that IT has invested in,” he says.
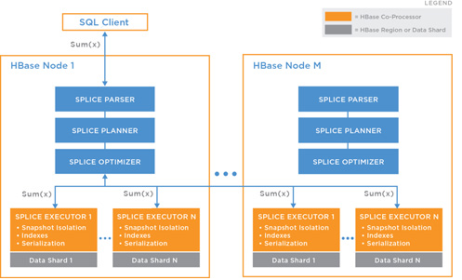
Also, HBase doesn’t support multi-record transactions, which limits its usefulness in real-world applications, Zweben says. “HBase does not have joins. It does not have transactions beyond a single record in a table,” he says. “What does that mean? It means if you have a bunch of data coming in from an order, and that orders has five line items in it, and you’re updating the database with what’s in that order, HBase can make sure you write one record into the database in a consistent, durable manner.” But there’s no guarantees for the other four.
HBase also doesn’t support secondary indexes, which applications use for doing quick look-ups. Instead, an application must scan the entire HBase database to get anything out of it, Zweben says. Granted, a NoSQL database like HBase can fly through that look-up process much faster than a traditional relational database could. But it’s not an ideal situation, he says.
“NoSQL databases are great at one thing, which is scale out,” Zweben says. “HBase lets you do very high fidelity reads and writes quickly. It definitely crosses the ground into real-time, but it lacks SQL. Here we come along and layer all the features on top of HBase, and you get the best of both worlds. Being built on Hadoop and HBase, we get the same principle, but we don’t throw the baby out with the bath water.”
 |
|
| Monte Zweben has a long history in the IT business. He started out as a Deputy Branch Chief of the Artificial Intelligence Branch at NASA Ames before founding Red Pepper Software, a supply chain management software company acquired by PeopleSoft in 1996. In 1998, he founded the e-commerce firm Blue Martini Software, which made him a billionaire after an IPO at the height of the dot-com bubble in 2000. Zweben lost hundreds of millions of dollars after the crash, but continued to lead companies, including SeeSaw Networks, Clio Music and now Splice Machine. | |
The idea is to trick an application into thinking it’s talking in SQL to a good old relational database, when in fact Hadoop and HBase are doing the heavy lifting under the covers. It’s a novel idea, and one that could ultimately bear fruit.
“The good thing is we’re just a standard SQL database with ODBC and JDBC connectors,” Zweben says. “We fit into today’s database world intimately and immediately. So if there’s somebody using Informatica or other ETL tool, or if they’re using Microstrategy or Tableau today, we fit into that.”
Splice Machine has raised $4 million to date, and hasn’t sold any software yet. In late October, Splice Machine announced that it is opening the door for an additional 50 customers to try the software out in limited availability.
Zweben said he got some takers at last week’s Strata + Hadoop World conference. “We had a very successful conference,” he said. “We were very impressed with the kinds of prospects who came by–very large enterprises with clear problems they wanted to [address]. They had real use cases.”
In the meantime, Splice Machine continues to develop its software. Every night at headquarters, the company runs unit tests of the Splice Machine database against the three major Hadoop distributions, Cloudera, Hortonworks, and MapR Technologies. The goal is to have certifications in place for those distributions before the company announces GA, hopefully this winter.
Related Items:
Top Three Big Data Startups at Strata
Cloudera Articulates a ‘Data Hub’ Future for Hadoop
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
Call & Contact Center Expo
 April 24 - April 25Las Vegas NV United States
April 24 - April 25Las Vegas NV United States -
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States