

September 6, 2013
Cloudera Search 1.0: Like Googling Hadoop
Organizations using Cloudera’s Hadoop distribution have a new search option that promises to make it much easier to find information in Hadoop. In fact, Cloudera claims that its new Cloudera Search 1.0 offering is so easy that a Cloudera vice president compared it to using Google.
 That comparison is funny because, of course, the Hadoop File System itself originated from the Google labs. That it took Cloudera to come up with a way to apply the “just Google it” metaphor to Google’s big data creation is a tad ironic.
That comparison is funny because, of course, the Hadoop File System itself originated from the Google labs. That it took Cloudera to come up with a way to apply the “just Google it” metaphor to Google’s big data creation is a tad ironic.
But the fact remains that Hadoop distributions, such as Cloudera’s, can be quite complex beasts that don’t do “easy” very well and don’t offer “simple” interfaces, such as search functions. According to Cloudera, it’s a laborious, time consuming, and hardware-intensive task to set up a basic search engine to hit its open source CDH or commercial Cloudera Standard and Cloudera Enterprise implementations.
That all changes with Cloudera Search 1.0 and the accompanying add-on RTS (Real-time Search) subscription offering, which are based on the open source Apache Solr search engine. The company rolled out a beta of the software earlier this year and is now supporting as a generally available (GA) product.
According to Cloudera, its new search offering enables people to perform natural language keyword searches against HDFS and Apache HBase without advanced programming knowledge or extensive training. The company says this approach lets users explore their data and discover its “shape” quickly and easily during the data modeling stage.
Cloudera says this search capability is quite valuable to Hadoop users now, considering all the different types of data they’re socking away in the HDFS. But it will become even more useful in the future, as organizations continue to load their Hadoop clusters with data that, in a previous era, would have been destined for a traditional relational data store.
“We’ve taken what was once a relatively complicated and involved freestanding system, requiring its own hardware and operational model, and turned it into a feature of a larger, more ubiquitous open source platform, CDH,” states Cloudera vice president of products, Charles Zedlewski. “With Cloudera Search, Hadoop deployments can now be explored with the same ease of use and speed as a simple Google search engine query, empowering our customers to achieve rapid insights from a fully integrated platform.”
On the front end, the search metaphor is quite easy to grasp: just Google it, after all. This is done via Cloudera Hue, the company’s Web-based UI. On the backend, Cloudera Search employs several components, including two types of indexers. This includes batch indexing of Hadoop and HBase “that is comparable to MapReduce”; and (near) real-time indexing of events via the Apache Flume and the Lily HBase Indexer. The software also features field extraction of Hadoop-optimized file formats, such as Apache Avro. Management of the software is handled with Cloudera Manager.
Cloudera Search is based on the Apache Solr project, but it bolsters it by introducing a new Solr indexer sink, which Cloudera says can be used within arbitrary Flume architectures to offer near real-time document processing and indexing.
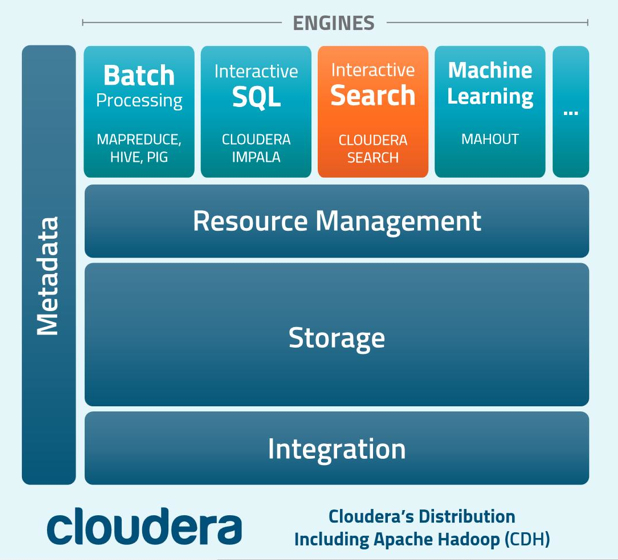
All Cloudera Search components reside on the same cluster as other engines in Cloudera’s distro, including batch processes like MapReduce, Hive, or Pig; interactive SQL processes like Impala, and machine learning processes like Mahout. The advantage of this approach is that everything is consolidated, thereby reducing the maintenance overhead and simplifying operations.
One early user of Cloudera Search is the agriculture giant Monsanto. “Incorporating Search into our existing Cloudera environment allows us to index images of plants at various stages in their lifecycles in real-time, which accelerates product development,” said Monsanto’s R&D big data engineer Jeff Melching in a Cloudera Search brochure. “This ultimately supports our goal of helping farmers produce enough food to sustain our growing global population while conserving natural resources.”
Related Articles
Twitter Conjures Up a Hadoop-Storm Hybrid, Ponders IPO
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
Call & Contact Center Expo
 April 24 - April 25Las Vegas NV United States
April 24 - April 25Las Vegas NV United States -
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States