

August 12, 2013
The Three T’s of Hadoop: An Enterprise Big Data Pattern
Enterprise data not just exists quietly at rest, but also flows very dynamically. Organizations need to put their data in constant movement in order to turn raw transactional and operational data material into business insight. The 3 Ts (Transfer, Transform, and Translate) is a Hadoop-driven enterprise big data pattern for that purpose. We officially proposed the concept of 3 Ts recently at Hadoop Summit 2013.
Enterprise Data in Continuous Iterations of Circular Flow
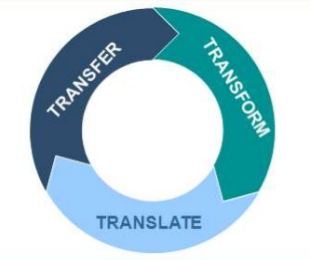 In our 3T model, the most efficient enterprise data movement is a 3-step process, which covers complete enterprise data lifecycle, including storage, integration and analytics. If we visualize the 3T pattern as a circular shape, at the center of the circle is Hadoop-based enterprise big data platform. In that ecosystem, enterprise data goes through continuous iterations of movement, each cycle completed with three stages, all named with an initial T.
In our 3T model, the most efficient enterprise data movement is a 3-step process, which covers complete enterprise data lifecycle, including storage, integration and analytics. If we visualize the 3T pattern as a circular shape, at the center of the circle is Hadoop-based enterprise big data platform. In that ecosystem, enterprise data goes through continuous iterations of movement, each cycle completed with three stages, all named with an initial T.
Enterprise data flows through the 3T stages in a clockwise direction, indicating the time dimension in the process, that is, it symbolizes the ultimate goal of enterprise data movement: to reduce the latency or time spent in the conversion of raw data into business knowledge. In each iteration of this continuous data flow, coming in is raw transactional data, going out are actionable data products as business wisdom, which will help enterprises make better business decisions in daily operations so as to generate more data, hence begins the next iteration of enterprise data flow.
Transfer: Sourcing All Enterprise Data into Hadoop
One liner for this first T: Capture continuously all enterprise data at earliest touch points possible, deliver the data from all sources, through all source data systems, to Hadoop, and store under HDFS consolidated and centralized data as the single point of truth.
In this T, what to transfer is not data from certain divisions, or partial datasets from some data systems, but every piece of data that belongs to the enterprise. Data sourcing or ingesting is something enterprises do every day, but not every enterprise takes such ambitious effort to transfer, consolidate, and centralize all their data into Hadoop. Enterprise upper management with a vision and long-term strategy for their data can make this T an enterprise-wide mandate. It takes time to build a decent Hadoop-based enterprise data infrastructure. Keep doing this T will benefit enterprises in the long run.
To source data “at earliest touch points possible” is important, not only because it is a measure to guarantee the data quality by going directly to the primary source, but also because it matters for the enterprise’s “time to insight”, it is about its reduction ultimately. So do it as early as possible, and do it everywhere that enterprise data is generated.
Why should Hadoop be the grand destination of all enterprise data? Simply put, Hadoop is not your regular data system. Today no other enterprise data system of RDBMS or EDW has the same storage flexibility (for structured, semi-structured and unstructured data), computational power (MapReduce), scalable capacity (grid of hundreds or even thousands of data nodes) and cost efficiency (commodity hardware), plus the rapidly growing technology stack backed by the open source community, start-ups, and big vendors, as Hadoop does. Very likely Hadoop will soon become the de facto center of enterprise data universe. With Hadoop ecosystem as the platform, enterprises can start to build and maintain a truly centralized reservoir of federated data infrastructure in efficient and economic fashion.
Here is the difference this T would make: prior to it, enterprise data could be isolated, partial, monolithically segmented, and disconnected in various siloed data/file systems; after this T, enterprise data will become holistic and consolidated in Hadoop, heterogeneous, diverse and huge, an ideal state for large-scale, in-depth enterprise big data analytics.
Transform: Integrating Enterprise Data within Hadoop
One liner: Keep the enterprise data flow beyond the ingesting phase by transforming the data from dirty to clean, from raw to standardized, and from transactional to analytical, all in situ, that is, within Hadoop.
The second T is a critical stage where all the magic of integration happens to enterprise data. Data transformation can have many requirements in multiple dimensions: “from dirty to clean” is about data quality; “from raw to standardized” about usability, and “from transactional to analytical” about functionality. But this second T has one special requirement for data integration that other non-Hadoop systems won’t have: transform the data in-place, in situ, in Hadoop.
Why is in-place data integration with Hadoop such a big deal? For one thing, this T is not the same as the T in ETL, even though both use exactly the same term: transform. ETL has been around for years as a popular process for conventional data warehousing. It exists for a good reason: in the enterprise data models of ‘80s and ’90s, storage and analytics systems are two different types of animals living in separated, incompatible worlds. Under such circumstances, it is inevitable for integrative and analytical tasks to retrieve data from one system, and load and transform it in another. The side effect is repeatedly redundant, non-value adding data movement back and forth between the storage and analytics systems. In the big data era, conventional ETL can cause serious, painful network traffic bottleneck between enterprise data systems, and its possible negative impact on enterprise data and its flow should not be ignored any more.
The 3T pattern promotes data movement in the enterprise, but it discourages the movement that does not add value to the data. Technically it is very feasible to do in-place data transformation in Hadoop because it provides an integrated platform that is organically suitable for storage, integration and analytics under one roof.
It is necessary to carefully partition enterprise data under HDFS in different layers to separate raw source data, standardized data, and task-specific analytical data, so that enterprises can keep the entra-Hadoop data flow running during the integration stage. For the standardized data layer, organizations can still apply conventional EDW’s dimensional modeling there, and organize enterprise master data in finest granularity as atomic units. Enterprise dimensional data can then be transformed once, and mixed and used many, many times.
In this second T, unnecessary data movement is reduced through in situ data transformation, and that eventually helps enterprises move closer toward the ultimate goal: time to insight latency reduction.
Translate: Making Enterprise Data Products out of Hadoop
Turn analytical info into data products of business wisdom using home-made or commercial tools of analytics built on top of Hadoop. Business decisions supported by those data products will help generate more new data, thus a new round of enterprise data movement.
This third T, Translate, is the last step to complete one cycle in enterprise data’s circular flow iterations. Analytical data prepared in previous phase now needs to be translated into actionable knowledge to assist business decisions.
Analytical tools, including the ones for visualization, are needed in this phase to discover new business knowledge hidden in the information gathered and prepared in previous stages. There have been discussions about whether to buy or build such tools. Our answer: it depends. You can take a pure open source approach and build your analytical applications, if existing commercial packages are not exactly what you are looking for, and you have development resource available. If you can afford it and the commercial tools can do your job, buy them by all means. Or, you can take a combined approach to buy as well to build.
Whatever route you take, we would like to put one pre-condition as our recommendation: only choose those tools built on top of Hadoop, that is, the ones that are integrated and compatible with Hadoop. One simple question to ask about the available tools and packages is whether they can load input data directly from HDFS or HDFS-based storage layers such as Hive, HBase, Accumulo, and other columnar stores or NoSQL systems.
This “on top of Hadoop” criterion for selecting analytics tools and packages in the third T is based on the same consideration for the in situ requirement for the second T. We want to fight against the latency enemy during the circulation of enterprise data flow; and latency is not just about the temporal length of a period by itself. The latency of enterprise data flow is directly related to how far, i.e., how much distance, the data has to travel over the network. In other words, latency is a temporal issue as well as a spatial one. So data locality matters here. Distributed systems like Hadoop are very much network I/O bound. To move the prepared data out of Hadoop and into other systems for the sake of analytics would be counter-productive, against our original purpose to fully utilize Hadoop’s power and capabilities. To use solely analytical tools on top of Hadoop is an assurance that in this last phase of the 3T stages, there will only be shortest possible distance between data feeds as input and data products as outcome. That is, eventually, an assurance for low-latency or real-time enterprise big data analytics.
It used to be very difficult to conduct serious analytical tasks with Hadoop. Not anymore. Recently we have seen quite a lot of exciting new technology, functionality, and features emerged in the enterprise data analytics realm: Dremel-based Impala and Apache Drill for ad-hoc, interactive, and real-time big data analysis; Stinger for high-performance, SQL compatible Hive query; Storm-on-YARN for stream-based real-time data feeds/pipelines, to name just a few. And to make it even better, Knox and Sentry will add security to enterprise BI applications.
Everyone in the big data business nowadays wants real-time analytics. To make it happen, streamlining enterprise data flow is a necessity. The 3T pattern provides a Hadoop-centric model and solution to help you get there, and get there in a simpler, better, and faster way.
About the Author
 Wuheng Luo is an architect for Hadoop and big data solutions at Sears Holdings Corporation and its Hadoop focused start-up, MetaScale (www.metascale.com). Wuheng’s Hadoop related experience includes projects for Sears Holdings’ enterprise data hub, Yahoo search data pipeline, MetaScale client BI initiative. He has a PhD from UIUC and an MS in computer science from IIT, Chicago.
Wuheng Luo is an architect for Hadoop and big data solutions at Sears Holdings Corporation and its Hadoop focused start-up, MetaScale (www.metascale.com). Wuheng’s Hadoop related experience includes projects for Sears Holdings’ enterprise data hub, Yahoo search data pipeline, MetaScale client BI initiative. He has a PhD from UIUC and an MS in computer science from IIT, Chicago.
The 3 Ts presentation is available as slides at http://www.slideshare.net/Hadoop_Summit/luo-june27-1150amroom230av2-24152168.
Related Items:
Bare Metal or the Cloud, That is the Question…
Treasure Data Gains New Steam for Cloud-based Big Data
Big Data Garbage In, Even Bigger Garbage Out
Tags:
Hadoop; Wuheng Luo
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
Call & Contact Center Expo
 April 24 - April 25Las Vegas NV United States
April 24 - April 25Las Vegas NV United States -
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States