

July 17, 2013
LinkedIn Centralizing Data Plumbing with Kafka
As company data grows, so too grows the complexity of the data-stream. This can lead to a convoluted crisscross of specialized pipelines that don’t scale or play well with each other.
 Recently at the Hadoop Summit, engineer, Joel Koshy discussed how LinkedIn attacked this problem and built a real-time data pipeline that they manage to keep current across geography in their disparate datacenters.
Recently at the Hadoop Summit, engineer, Joel Koshy discussed how LinkedIn attacked this problem and built a real-time data pipeline that they manage to keep current across geography in their disparate datacenters.
Developed by LinkedIn, the solution came in the form of a high-throughput distributed messaging system called Apache Kafka. The program was created internally and contributed to Apache in July 2011. The goal of the project was to deliver a single system able to unify disparate systems doing messaging, ETL, log aggregation and stream processing, and untangle an architectural mess of specialized pipelines.
At LinkedIn, like most web companies, the company provides value through tracking user activity, including user events, connections and interests. A user’s activity stream becomes an important ingredient in the many data driven products that the company offers. Along with this data there are system and application metrics, and other logs that are very important for monitoring the health trends of production systems, identifying bottlenecks, and etc. LinkedIn was determined to find a way to integrate all of these disparate data streams and make them universally accessible to any and all of their data driven systems that needed the data.
“It’s very important to have the activity feed in real time,” Koshy explained. “Recommendation systems can provide more relevant suggestions if it incorporates user activity early on. Search systems provide more relevant results if the indexed content is as fresh as possible. Security systems need to track user activity in near real time to detect anomalous patterns and react quickly.”
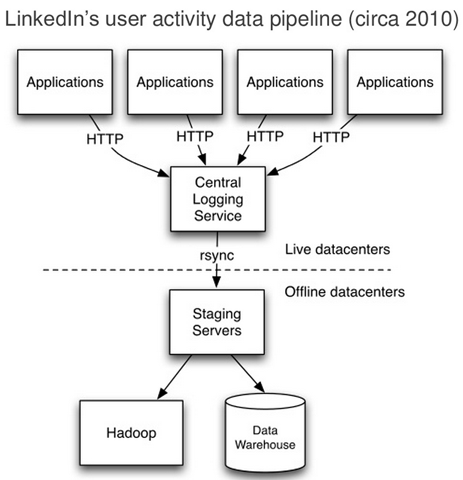 The problem that LinkedIn had, however, was that their architecture wasn’t able to scale to offer real-time data access to its services in the live data center. This resulted into an organizationally disjointed and out of sync data process where unclean data was thrown over the fence to the data warehouse team to clean and make it beautiful. “That is not the ideal stage to do cleaning because they’re not necessarily well versed in what the structure and semantics of the source data is,” explained Koshy, who noted that the producers of the data likewise didn’t know what data is amenable for treatment at the ETL stage.
The problem that LinkedIn had, however, was that their architecture wasn’t able to scale to offer real-time data access to its services in the live data center. This resulted into an organizationally disjointed and out of sync data process where unclean data was thrown over the fence to the data warehouse team to clean and make it beautiful. “That is not the ideal stage to do cleaning because they’re not necessarily well versed in what the structure and semantics of the source data is,” explained Koshy, who noted that the producers of the data likewise didn’t know what data is amenable for treatment at the ETL stage.
To address this, the company set out to implement a centralized data pipeline using messaging systems. Koshy says at first they tried using ActiveMQ and RabbitMQ. “The approach was to basically take these activity feeds and just hook it up to these technologies,” he explained. “That didn’t go too well and I think the reason for that is largely because they weren’t designed to scale to the volume of data that we had… Persistence is not an ingrained concept in these systems and we found that they were hard to scale out – it wasn’t as simple as throwing more brokers at the problem.
He says that instead they decided to do something entirely different, which was to use a central commit log. “This borrows from the traditional database concept where you have a bunch of updates – you update tables, indexes, materialized views and so on – and you do it in a way that is corrective in the presence of failures… So someone else can read these changes from these logs and apply it elsewhere.”
Koshy says that using Apache Kafka, they took this concept and analogized it to use for messaging. “It’s really a simple concept,” he explained. “The source producers basically append to this log, and the consumers, they just read from the log.”
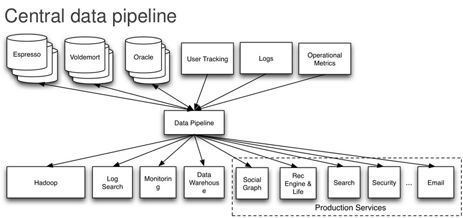
“We have the brokers in the middle (you can have one or more brokers), and the brokers basically provide the topics, with each topic divided into a number of partitions” he explained.
Additionally, the company is able to use the central data pipeline model to provide real-time data updates across their disparate datacenters. Koshy explained that the company is employing mirroring to implement Kafka clusters across datacenters with a few minutes of delay.
“That’s a pretty powerful concept because it implicitly means that the data pipeline can almost seamlessly cut across data center boundaries,” he explained. “That means, for instance, the Hadoop cluster in the offline datacenter can access the activity feed from the datacenter in almost real-time, and more importantly, you can actually push data back to this data pipeline and back to production for services to consume.”

Ultimately, using Kafka, LinkedIn has been able to build and drive a central data pipeline and tracking system that performs at scale. For LinkedIn, this means 28 billion messages a day, with peak writes at 460,000 messages a second and peak reads at 2,300,00 messages a second (though Koshy says that because they do batching, the request per second is actually a factor less). He says the company is currently at over 40 to 50 live services consuming the data at any given time.
As for Kafka, the project’s 0.8 version was released last month into public beta, allowing engineers to test out its newest features, which include intracluster replication – a feature which Koshy says LinkedIn is very excited about and have already rolled into production.
We’re aware of other companies, such as InfoChimps, who use Kafka as part of their own Data Delivery Service.
Related Items:
Yahoo! Spinning Continuous Computing with YARN
Achieving Low Latency: The Fall and Rise of Storage Caching
Deep Attempts to Recreate the Single Platform, General Purpose Database
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
Call & Contact Center Expo
 April 24 - April 25Las Vegas NV United States
April 24 - April 25Las Vegas NV United States -
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States