

July 8, 2013
Interplay between Research, Big Data & HPC
Research, Big Data and High Performance Computing (HPC) do not dance or play. People do. The interplay between researchers, funders and HPC support professionals are issues related to the evolving research focus, funding preference, influence of Big Data and its specific demand on HPC services.
Evolving Research Focus
Worldwide, we now generate the equivalent of all the data that existed in the world up to 2003 every two days. This is “big data” and it makes up a vast new natural resource that has the potential to revolutionize both industries and societies. All these have a significant implication on scientific research, the driving force of change.
 High Performance Computing in support of scientific research has long been dealing with big data. For example, in research of the now widely publicized Higgs Boson (the God particle), in 2000 Physicists anticipated that data coming from the LHC at CERN to the ATLAS tier-1 site in Canada would be in Petabytes. This was 13 years ago and indeed, we were not wrong on that when the LHC began operational four years ago As another example, the Canadian Advance Network for Astronomical Research (CANFAR) is running a 1.2 Petabyte size database that provides astrophysicists observation data that spans the entire electromagnetic spectrum. This is the equivalent of storing data in 150 thousand DVD disks which stack up to 250 meters, half the height of the CN Tower in Toronto, Canada. In the near future, the proposed Square Kilometer Array project (SKA) will have data size measured in Exabytes, i.e. thousands of Petabytes.
High Performance Computing in support of scientific research has long been dealing with big data. For example, in research of the now widely publicized Higgs Boson (the God particle), in 2000 Physicists anticipated that data coming from the LHC at CERN to the ATLAS tier-1 site in Canada would be in Petabytes. This was 13 years ago and indeed, we were not wrong on that when the LHC began operational four years ago As another example, the Canadian Advance Network for Astronomical Research (CANFAR) is running a 1.2 Petabyte size database that provides astrophysicists observation data that spans the entire electromagnetic spectrum. This is the equivalent of storing data in 150 thousand DVD disks which stack up to 250 meters, half the height of the CN Tower in Toronto, Canada. In the near future, the proposed Square Kilometer Array project (SKA) will have data size measured in Exabytes, i.e. thousands of Petabytes.
Using big data to support research is not new to HPC professionals, yet its presence only confines to a handful of leading edge grand challenges in the extreme world of subatomic and cosmological systems such as finding the Higgs boson and mapping the cosmic microwave background radiation. But that is changing as research evolves its focus to understanding emergent phenomena that are much closer to our daily life. Examples of these studies abound: weather forecasting, ocean ecosystem, power grid stability and stock trend and portfolio optimization. These are all areas where big data can play successfully to help organizations that are operating in a world of accelerating complexity and massively available information.
In fact, these “daily life” systems are more complicated than those in the extreme world. In these systems, there is much larger number of different participants than those in a subatomic system that initiate various interactions among the participants. However, the number of participant in these systems is not large enough as in a cosmological system to trigger a gravitational effort that quenches out all potential complexities like what happens in stars and galaxies. ”Daily Life” systems create a network of interrelated interactions that give rise to collective and emergent properties and seemingly unpredictable behaviors. These are systems scientists cannot understand by simply taking the traditional reduction approach. In order to seek the basic principle behind these emergent phenomena, Scientists have to start with a very large number of hypotheses that result in a very large number of numerical models. The combination of these results then needs to be compared and analyzed with a huge amount of data from real world measurements.
The most complicated “daily” or emergent system of all is the brain. For example, the Big Brain project led by the Montreal Neurological Institute studies our brain one 20 micron thin slice at a time. That’s where big data comes to play. While some scientists are busy with theoretical discovery, others cannot wait for it. We need to solve problems at hand to keep the world moving.
A typical practice in solving problems like these is to process incoming data in real time and then compare the immediate analytical result with our knowledge, experience and the big data accumulated in the past. One of the most famous examples of this practice in my experience is the UOIT / Sick Kids project for Real Time Monitoring at the Neonatal Intensive Care Unit. We call this practice event driven processing. The project showcases the potential of big data initiatives for online health analytics to provide new and advanced approaches for clinical decision support in critical care.
Trend in Government Research Funding
As mentioned, these emergent systems are much more relevant to our daily life than the two extreme worlds. Understanding them will have tremendous impact to our own well being. Therefore, it is of no surprise that this type of research focus among scientists matches well with a new trend of government funding preference.
For example, in Canada, under Industry Canada, the federal ministry where most research funding agencies reside, the Science, Technology and Innovation Council has the mandate to “Provide the Government of Canada with evidence-based science and technology advice on issues critical to Canada’s economic development and Canadians’ social well-being”. To a certain degree, the Canada Foundation for Innovation (CFI) and other Canadian research funding agencies conform to this Science and Technology Strategy. Canadian researchers are expected to conduct research that has the potential for more direct economic and social impact. It is beneficial that the focus of modern research aligns well with this funding preference. Many big data projects currently in development have the potential to contribute a significant, positive impact on our healthcare, energy, city and water management systems.
Data-Centric Research Computing Architecture
Now, how does the HPC support community enter the interplay? As illustrated, HPC plays an important role in investigating emergent phenomena and how it’s processing power couples with big data in both seeking principled approaches and solving “real world” problems with event driven processing. A closely related subject to this realization is the so-called “Data-Centric Research Computing System Architecture”. This system architecture was proposed by the author in 2006 at High Performance Computing Symposium at the Memorial University of Newfoundland in St. John’s, Newfoundland and Labrador, Canada after the design of several systems to support collaborative research projects.
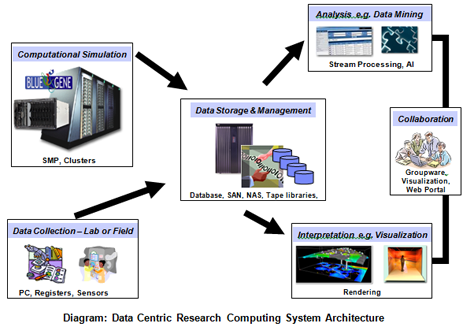
Those past research projects built standalone systems because their processing need could not be satisfied by batch processing based services offered by a traditional HPC facility. With the arrival of big data and the new focus on investigating emergent phenomena, this seven-year old architecture becomes more relevant today than in the past.
Two unique features stand out in this architecture:
(1) Data Dimension – we are very familiar with “data at rest” in structural format such as data in a relational database. But big data introduces other dimensions for data. As we invented and deployed so many highly reliable and capable sensors in the field for various purposes, we now have nonstop streaming data. For example, the UOIT / Toronto Sick Kids project deals with this type of data coming from monitors of the premature baby’s vital signs nonstop 24 hours a day. In addition to this “data in motion” we also have “data in many form”, e.g. sound, voice, picture, video, number, and text. You name it and we have it in today’s multimedia rich world where big data is multiplying at an annual growth rate of 60% – including both structured and unstructured content – according to industry analyst International Data Corporation. Last, but definitely not least, we have “data in doubt”. As data increases in volume and comes from more diverse sources, it exhibits an increasing degree of uncertainty due to inconsistency, incompleteness, ambiguities, latency, deception and model approximation. These new dimensions in data present challenges to IT professionals who are charged to acquire, organize, manage and deliver data to researchers in a data-centric system environment. New system technologies and data analytic tools are needed to make such an environment productive to researchers.
(2) System Integration – While traditional batch-based HPC is a critical component in a data-centric architecture, there are many other equally critical components such as data analysis and interpretation. To ensure researcher productivity, it is essential to provide services with a tightly integrated system. It is quite obvious that a fragmented component service will not support the demand from research collaboration in this architecture.
Big Data Influence in HPC Support Services – changing focus on skills
These two unique features lead to a perspective on a potential evolution in HPC services. Today, there are two types of HPC support professional: System Analyst and Application Analyst. With the new dimensions of big data, there will be more interesting and challenging system technologies to deploy and integrate to the HPC environment.
Also, due to economic consideration, funding agencies are demanding a single computing support organization for all funded research projects. So, it is not only an interesting new workload for System Analysts. It is also a new mandate. On the negative side, over the next few years, consolidation demand will likely close a large number of smaller HPC computing centers and hence, the demand for the HPC System Analyst will shrink. Those who are not die hard System Analysts might have to consider alternative career paths.
One possibility would be what can be categorized as a “High Value Application Analyst”. Research with big data demands an integrated data centric processing environment. Future Application Analysts will have to provide that service. This kind of new workload is very rewarding because in the new service environment, analysts will work very closely with researchers and will apply advanced system knowledge most relevant to the specific research objective at hand. Over the past 12 years, the author has had numerous opportunities to engage researchers in a similar way. That engagement stopped at the high level system design phase. Therefore, my sense of fulfillment is no doubt a lot less than an Application Analyst who would work with researchers all the way to project completion. In addition to HPC support professionals’ intelligence, knowledge, skill and passion to help researchers, solid project management is also a critical success factor in this type of system integration service. By combining professional buy-in and management discipline, we can transform HPC services into a proactive and high value project-based offering to the research community.
Modern science demands big data and modern analytics technology makes this data meaningful. The opposite is also true. big data triggers the opportunity for the research community and the HPC professional community to “play” in a more integrated fashion as they collaborate to advance scientific knowledge and benefit our society at the same time. In this scenario, everyone wins.
About the Author
 Dominic Lam has a Ph.D. in Condensed Matter Physics from the University of Toronto. He conducted nuclear reactor safety simulation using supercomputers in his early post graduate career. In the past 12 years, he has been responsible for HPC business and solution development for IBM Canada. In that capacity, he works with IBM Research and the Canadian research community (both academia and industries) to facilitate collaboration in joint projects on various scientific, engineering, social and economical subjects which make extensive use of information system technology. His understanding of the domestic funding challenges has made him a valuable part of the alliances of Canadian researchers and HPC support professionals.
Dominic Lam has a Ph.D. in Condensed Matter Physics from the University of Toronto. He conducted nuclear reactor safety simulation using supercomputers in his early post graduate career. In the past 12 years, he has been responsible for HPC business and solution development for IBM Canada. In that capacity, he works with IBM Research and the Canadian research community (both academia and industries) to facilitate collaboration in joint projects on various scientific, engineering, social and economical subjects which make extensive use of information system technology. His understanding of the domestic funding challenges has made him a valuable part of the alliances of Canadian researchers and HPC support professionals.
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
Call & Contact Center Expo
 April 24 - April 25Las Vegas NV United States
April 24 - April 25Las Vegas NV United States -
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States