

December 24, 2012
How Object Storage and Information Dispersal Address Big Data Challenges
Sponsored Content
Over the past decade, the definition of mission-critical data has changed for most enterprises. The explosion of digital content created by individuals as well as about individuals as they go about their daily lives (e.g., surveillance videos, motion sensors tracking location) has changed the nature of the data that organizations need to storage, manage and analyze. According to IDC, over 90 percent of the world’s data is so-called unstructured data—file formats such as Microsoft Word, PowerPoint presentations, PDFs and non-textual content like images, graphics, video and audio files. So, only 10 percent of data now represents what until quite recently was considered core data for a business.
And unstructured data will only continue to grow. According to a 2011 IDC report, the total amount of digital information created and replicated broke the zettabyte (1,000,000,000,000 gigabytes) barrier in 2010. The size of the digital universe is more than doubling every two years, and is expected to grow to almost eight zettabytes by 2015.
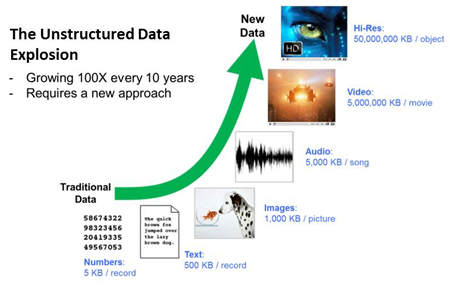
Given this data growth, it’s not unrealistic to think that companies will be looking for storage and analytics solutions that can grow to accommodate petabytes (1 petabyte = 1 million gigabytes) and even exabytes (1 exabyte = 1 billion gigabytes) of data in this decade. The defense and intelligence, public safety, energy and online media industries all rely on high-resolution imagery. Today those needs reach one terabyte at minimum use capacity each day. In order to meet strict compliance guidelines for patient care and ensure the integrity of medical records, the health care industry makes an average of three copies of data for most patients and in some cases five copies for the highest SLAs, including medical imaging. That information needs to be readily available and securely retained.
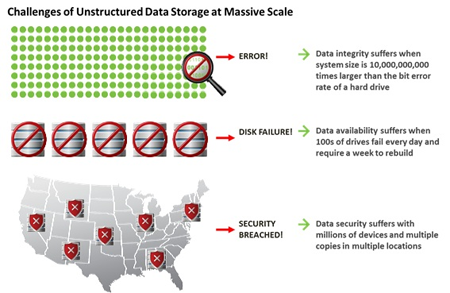
Storing, managing and analyzing unstructured data on such a massive scale creates unique challenges for enterprise and government agencies. These challenges include:
- Preventing data loss. When storage systems reach hundreds of terabytes in scale, drive failures and errors present a constant challenge. The traditional approach to protecting data against these failures is replication—creating one or more copies of the data to ensure that there is always a backup available in case of data loss. However, creating copies of the data eventually becomes difficult to sustain from a cost and administration standpoint.
- Maintaining an “always on” system. End users and customers have grown to expect 24/7 access to information—downtime is unacceptable. Data must always be available during storage system upgrades, drive failures, network outages—even during the failure of an entire data center.
- Protecting data from unauthorized access. Data must be protected from unauthorized access, both when it’s “at rest” and when it’s traversing the network. The massive scale of big data makes it difficult for organizations to identify and address potential security threats.
- Scaling storage capacity continuously while controlling costs. Storage devices continue to grow in terms of capacity while declining in price (more bits per device at a lower cost). However, even as the price of capacity declines, the cost to power, cool, house, connect and manage that capacity continues to pose a challenge to budgets.
To address these challenges, organizations are adopting new storage approaches that are designed to support massive amounts of unstructured data. Among these new approaches are object-based storage and information dispersal.
Object-Based Storage
Traditional storage systems typically use an underlying file system. File systems allow humans to organize content in an understandable hierarchy where access speed is not critical. This approach is ideal for human users but not for big data applications that must manage billions of objects such as images, documents, emails, videos, etc. When an organization has billions of objects that need to be stored and retrieved, a file system approach does not scale and incurs performance breakdowns and bottlenecks.
Object-based storage offers an alternative approach that is ideally suited for storing massive amounts of unstructured data. Object-based storage systems are not organized hierarchically. Instead, an object is identified and located by its unique identifier. This enables the number of objects to grow substantially beyond the limitation of traditional file systems while still maintaining the integrity and consistency of the data. Organization of the information in an object storage system is generally maintained by the application that is responsible for reading and writing information.
Valet parking provides an apt analogy for object-based storage. When you valet park your car, the attendant gives you a claim ticket that allows you to retrieve your car when ready. While the attendant has your car, he might move it around as needed to optimize space in the lot or garage. With object-based storage, an object ID identifies a particular piece of data, but not its specific location in the system. Data can be moved around the system as needed, and the object ID is the “claim ticket” needed to retrieve it, wherever it resides. In this waqy, object-based systems can use storage capacity more efficiently than file systems.
Both the large traditional storage players as well as newer, smaller vendors have introduced object-based storage solutions to the market.
Information Dispersal
Information dispersal is the practice of using erasure codes as a means to create redundancy for transferring and storing data. An erasure code transforms a message of k symbols into a longer message with n symbols such that the original message can be recovered from a subset of the n symbols (k symbols). Simply speaking, erasure codes use advanced math to create “extra data” that allows a user to need only a subset of the data to recreate it.
An Information Dispersal Algorithm (IDA) builds on the erasure code and goes one step further. The additional step of the IDA is to split the coded data into multiple segments, which can then be stored on different devices or media to attain a high degree of failure independence. For example, using erasure coding alone on files on your computer won’t do much to help if your hard drive fails, but if you use an IDA to separate pieces across machines, you can now tolerate multiple failures without losing the ability to reassemble that data.
In the example depicted in the diagram below, the IDA splits the coded data into 16 slices (referred to as the “width” of the system). The slices are then distributed to storage nodes across four different sites. Even though each site has experienced at least one device failure, the data is able to be reassembled bit-perfectly because only 10 slices (i.e., the “threshold” number of slices) are needed to recreate the data, thanks to the use of erasure coding. The width and threshold of a system are configurable and are determined by the reliability required. In this case, six slices can be lost or unavailable and the data can still be retrieved. An organization can choose another configuration that allows for the loss of either more or fewer slices, depending on its need for storage system reliability.
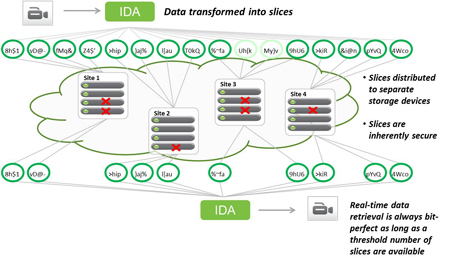
Information dispersal eliminates the need for the common practice of data replication described above. It also offers inherent security benefits because no complete copy of the data resides in any single location or storage node.
Information dispersal is offered by a small but growing group of vendors, often in conjunction with an object-based storage system. A number of other storage vendors use erasure codes without information dispersal for data protection.
Conclusion
As unstructured data volumes continue to grow, more and more companies will reach the petabyte milestone and confront the challenges associated with managing very large storage environments. Storage technologies that can deliver massive scalability while ensuring reliability and availability are already emerging to meet their needs. Early adopters of these technologies will include communications providers, government agencies, online content and service providers, and media and entertainment companies—any organization that has the delivery and/or analysis of large amounts of unstructured data at the core of its business.
Cleversafe’s innovative Dispersed Storage® technology combines object-based storage and information dispersal to deliver limitless scalability with high levels of availability, reliability and security. For more information, visit cleversafe.com.
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
Call & Contact Center Expo
 April 24 - April 25Las Vegas NV United States
April 24 - April 25Las Vegas NV United States -
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States