


October 22, 2012
Searching Big Data’s Open Source Roots
Ah, the ubiquitous search box. It’s something most of us tap multiple queries into on a daily basis—so often that this simple “old hat” process of searching across billions of records has made us forget about the deep, complex mining efforts for the right results in seconds.
 The technologies behind search are being tasked with not only larger volumes of data (that’s really the easy part)—they’re ingesting and propelling through data of different formats and with the demands that it digest both big and diverse data faster than ever before.
The technologies behind search are being tasked with not only larger volumes of data (that’s really the easy part)—they’re ingesting and propelling through data of different formats and with the demands that it digest both big and diverse data faster than ever before.
While that revolving effort to refine search and add ever-expanding layers of richness and relevance continues, some companies are using the root open source technologies behind large-scale search to spin out a refreshed approach to enterprise and research big data.
Consider this—search capabilities have evolved to the point that they can serve as the basis for large-scale genetic sequencing and analysis operations. To put this in some context, the process of sequencing the data of one patient can create more than one terabyte per individual, including the metadata that yield insight into genetic differences.
Grant Ingersoll, Chief Scientist at LucidWorks says that there is a large hospital that is prototyping systems that leverage this new breed of search. They need to surf the wave of data generated by DNA sequencing machines by tapping into the rich metadata of the genetic information via search to identify patient mutations and variations that can better guide treatments. In such a case, says Ingersoll, “they want to use Hadoop to do things like alignment and analysis of large amounts of genetic data in parallel.” This lets hospitals and researchers determine treatment options based on specific mutations and genetic variations among groups—a major step toward the goal of personalized medicine.
Behind this use case and the technologies being spun by LucidWorks are three Apache open source projects—all of which have had Ingersoll and many of his colleagues at the development helm. These projects include the indexing and search efforts behind Lucene and Solr, as well as Mahout – meaning, “one who rides elephants,” so think Hadoop. The company’s mission is to blend these projects to redefine what’s possible with enterprise-grade search across massive, multi-structured data using these and other open source and custom-developed search, indexing and machine learning tools.
To construct sophisticated, distributed approaches to big data search, discovery, and analysis requires a rethink for developers. For one thing, we’ve moved beyond the days of data as numerical values; the integration of text and a wealth of other semi- and multi-structured data creates its own complications. Big data application developers need a seamless way to pull together disparate, often open source strands of the DNA of search technologies—and this takes an integrated platform that can usher Hadoop, among other environments.
LucidWorks is working to put a new bevy of tools in the hands of developers who are seeking to comb massive multi-structured data via its standard LucidWorks Search and LucidWorks Big Data platforms. Enterprise users are asking far more from search—and the company says they can cater to those needs by becoming the “Google of enterprise search.” Ingersoll, who is also the company’s co-founder (and co-founder of the initial Apache Mahout project) has also been a “committer” to the open source effort for Lucene since 2004 and later Solr, before spinning out the company under the name Lucid Imagination, in 2008.
 For that matter, the entire small company is strong on Apache committers, claiming 9 of the 37 core committers to the Apache Lucene/Solar project. Their first business model evolved around providing an enterprise-level embedded search development platform on top of the Lucene/Solr project in addition to selling support, training and consultation for the projects à la the Red Hat approach. Following a rebranding (shifting from Lucid Imagination to LucidWorks) they altered their business model by moving from support to developing further capabilities via licensed tweaks to aid in hyper-powerful search, discovery, and analysis – an effort that was solidified by their LucidWorks Big Data offering, which they rolled out in May.
For that matter, the entire small company is strong on Apache committers, claiming 9 of the 37 core committers to the Apache Lucene/Solar project. Their first business model evolved around providing an enterprise-level embedded search development platform on top of the Lucene/Solr project in addition to selling support, training and consultation for the projects à la the Red Hat approach. Following a rebranding (shifting from Lucid Imagination to LucidWorks) they altered their business model by moving from support to developing further capabilities via licensed tweaks to aid in hyper-powerful search, discovery, and analysis – an effort that was solidified by their LucidWorks Big Data offering, which they rolled out in May.
The company’s Big Data offering builds on the momentum and technologies that back their LucidWorks Search offering. The key element that culls it under the “Big Data” banner is a full integration of any standard Hadoop developer’s arsenal (Mahout, Zookeeper, Pig, etc.).
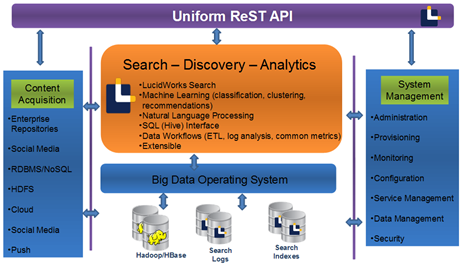
The company has focused on the scalability challenges that come with complex search at scale—a matter that isn’t just about data volume, but is as much about the data complexity/results relevance balance. Ingersoll told us that when his team got started in 2008, Hadoop was beginning its climb to popularity. The team set about finding the most effective machine learning algorithms for Hadoop environments before evolving beyond just Hadoop to see what machine learning algorithms would be most efficient and scale no matter what implementation environment was at the core.
Ingersoll says that both their Search and Big Data offerings were driven by enterprise demand to take information access and relevance to new levels. He says that Lucene and Solr are making keyword-based relevance easier and other developments on the distributed side are making the process more efficient by speeding up results.
Next — Riding the Elephant on Search >
In the past users were taking advantage of these projects for search from a text standpoint, but as data grew into more places, the demand to access unstructured or semi-structured content branched outward. Now it’s not just about data access, rather, the focus now is on relevance, scalability and fuller functionality of search capabilities. Ingersoll said that with this in mind, the company has been investing heavily in distributed and real-time search, an effort that is aided by the fruits of Apache labor via the Lucene and Solr 4.0 release, which he says will “set the stage for the next generation of search applications.”
The Lucene project itself began in 1999 with Hadoop co-founder Doug Cutting, and resulted in the project becoming robust enough to support the underlying search capabilities for Twitter, Disney, LinkedIn, and other recognizable brands. Solr, which Ingersoll has also worked on, was added to extend this functionality.
Mahout, which is Ingersoll’s big claim to Apache fame, was spun out of Lucene as the needs to solve more complex relevance problems in search, especially on the text front, merged with greater demand for more robust machine learning libraries. While he notes that there are already a number of open source machine learning libraries available, they are too research-oriented, don’t scale, or lack the development community that Apache provides.
Development work on Mahout to increase relevance and robustness is centered around three areas of machine learning; classification, clustering and collaborative filtering, all three of which he says are addressed by the company’s LucidWorks Big Data offering.
“We want to provide a one-platform approach to let users ask questions of semi and multi-structured data and give them multiple ways of accessing and searching that content,” said Ingersoll. “By marrying Solr with Hadoop, Mahout and other machine learning tools, we’re giving application developers a single place to go to build out these types of systems,” Ingersoll added, pointing to a range of use cases in government, genetics and ecommerce where these capabilities are required.
Technologies:
Frameworks
Tags:
apache, big data, enterprise search, ingersoll, Lucene, lucid imagination, LucidWorks, mahout, solr, strata12
Leading Solution Providers
















