

September 17, 2012
Big Data – Scale Up or Scale Out or Both
Sponsored Content
Introduction
The “Big Data” term is generally used to describe datasets that are too large or complex to be analyzed with standard database management systems. When a dataset is considered to be a “Big Data” is a moving target, since the amount of data created each year grows, as do the tools (soft-ware) and hardware (speed and capacity) to make sense of the information. Many use the terms volume (amount of data), velocity (speed of data in and out) and variety of data to describe “Big Data”. Large datasets can be analyzed and interpreted in two ways:
- Distributed Processing – use many separate (thin) computers, where each analyze a portion of the data. This method is sometimes called scale-out or horizontal scaling.
- Shared Memory Processing – use large systems with enough resources to analyze huge amounts of the data. This method sometime called scale-up or vertical scaling.
Distributed processing
Depending on the type of data and the desired outcome where a distributed system would be the best fit for an organization. Simple searches through a list of records could be easily distributed to a set of systems, with the results from each server then collected. An example of this could be searching through all driver license records for those with blue eyes. A portion of the driver license records could be kept on each server, in memory, without issues such as overlap or dependency on other server results. Apache Hadoop is an open source software framework that supports data intensive distributed applications. It enables applications to work with hundreds to thousands of computational independent computers and petabytes of data. Hadoop was derived from Google’s MapReduce and Google File System (GFS) papers.
Advantages and disadvantages of distributed processing
The main advantage of distributed processing is its ability to scale just by adding “one more node”. An additional node or server can be added to the cluster and the necessary modifications to scripts or applications can be quickly implemented. On the other hand it requires the skillsets and management capabilities to manage Hadoop cluster which require setting up the software on multiple systems, and keeping it tuned and running. It also worth noting that Hadoop is suitable for cases where data interdependency is low and requires small (if any) data replication.
Shared Memory processing
If the amount of data is complex, unstructured or where multiple algorithms are required to be used on the data, a large shared-memory system would be best. Much more of the data could be held in the memory of the system, and different processes could all operate on the same data, while the data resides in memory. For instance, monitoring thousands of video feeds to determine any correlation between the images would benefit from keeping all the feeds in main memory and having multiple applications all work with the data. By utilizing a shared memory approach, applications become easier to develop as well as debug.
Advantages and disadvantages of shared-memory processing
While it is much easier to manage single large-scale system and host all the data and processing on one machine, such systems tend to be quite expensive. The reduction in OPEX as result of single system to manage and a reduction in DBA complexity come at the cost of the hardware.
ScaleMP vSMP Foundation
vSMP Foundation from ScaleMP creates a virtual shared-memory system, from a distributed infra-structure, providing the best of both worlds for big-data and analytics problems. On one hand, it allows scale just by adding “one more node” but still keeps the OPEX advantage of a shared-memory system. It provides benefits for small Hadoop deployments where the OPEX costs are high, and can handle big-data cases where data cannot be easily distributed by providing a shared-memory processing environment.
How does it work?
vSMP Foundation creates a single virtual machine with CPUs, RAM and I/O aggregated from several smaller systems. This allows for more data to be held in memory, directly accessible by any of the CPUs in the aggregated system.
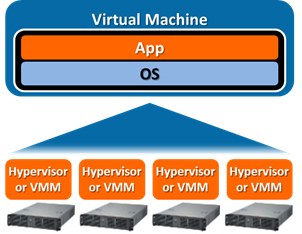
Advantages and disadvantages of vSMP Foundation
With complex datasets that require a number of steps of processing and significant computations, the ability to hold larger datasets in memory, without having to swap to disk, greatly reduces the time to understanding trends within the data.
Smaller, more distributed types of analyses can also benefit from vSMP Foundation. For example, if a distributed algorithm is used, a certain number of servers must be maintained and administered. By using vSMP Foundation on a small to medium sized cluster, this greatly simplifies the administration cost, while the application will run at the same performance. By reducing the administration costs associated with a small cluster running a distributed algorithm, an increased ROI can be achieved, while continuing to run familiar big data analysis applications.
Usage Models for Aggregated Systems
When aggregation of systems is performed, there are a number of use cases that benefit anyone analyzing large amounts of data. The most popular case would be to gain access to all of the memory across all of the systems. Data can be stored in memory, significantly speeding up data access (as compared to hard disk drives). This is shown in the upper left diagram. Some applications may be more compute intensive and could benefit from using a large number of cores for processing. In this case a single application, running on a single instance of the OS can use all of the cores as well as accessing all of the memory. This is shown in the lower left of the image. Other applications that access large amounts of data could benefit from aggregating the I/O capabilities of individual servers into one I/O system. This allows for faster ingest of the data, as shown in the upper right of the diagram. Finally, in the lower right shows how using aggregation can simplify the management of a cluster, as compared to having to manage individual systems.
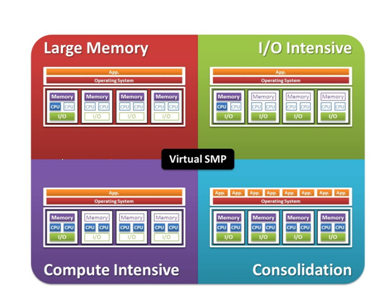
Summary
With the increasing business requirements to analyze and understand significant volumes of data, it is important to create an IT system than can respond to those needs. By using vSMP Foundation to combine the low cost of scale-out systems with the advantages of scale-up systems, cost savings can be realized while maintaining a highly responsive system to make sense of Big Data information.
|
Distributed Processing |
Shared Memory Processing |
vSMP Foundation |
|
|
Advantages |
Low cost infrastructure (CAPEX) with pay as you grow characteristics |
Single system to manage (OPEX) |
|
|
Disadvantages |
Management cost (OPEX) |
Platform cost CAPEX) |
|
For More Information:
To learn more about how aggregating scale-out servers can benefit and speed up big data analysis, download our whitepapers or visit the ScaleMP web site.
Vendors:
ScaleMP
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States