

February 27, 2012
Fujitsu Puts Proprietary Twist on Hadoop
Fujitsu has released a new twist on its ever-expanding big data theme. With the release of Interstage Big Data Parallel Processing Server V1.0 today, they claim the ability to simplify massive Hadoop deployments via the injection of their home-cooked proprietary distributed file system.
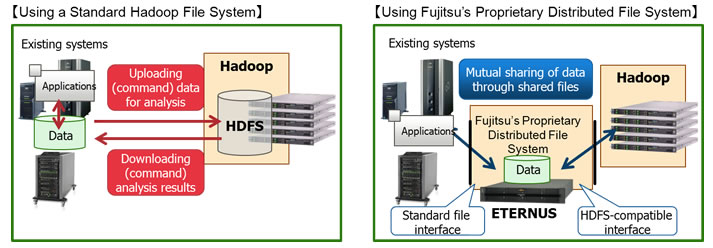
 Fujitsu claims the integration of an unnamed proprietary file system and Apache Hadoop will result in improved data integrity and performance as it removes the need to transfer data to Hadoop processing servers.
Fujitsu claims the integration of an unnamed proprietary file system and Apache Hadoop will result in improved data integrity and performance as it removes the need to transfer data to Hadoop processing servers.
In an effort to ease the process of installation, the software has a smart set-up feature. Also, the company will be offering services to assist with deployment, including Hadoop. Fujitsu’s proprietary file system in addition to Hadoop’s Distributed File System (HDFS).
Drumming up their file system’s track record in mission-critical environments and recognizing Hadoop’s ability in processing unstructured data, Fujitsu claims the marriage of these technologies, will result in an improvement over using just HDFS itself as it requires data to be temporarily uploaded before processing.
The company touts the following benefits:
- Improved file system reliability with Fujitsu’s proprietary distributed file system, Apache Hadoop’s single point of failure can be resolved through redundant operations using a master server that employs Fujitsu cluster technology, thereby enabling high reliability. Moreover, storing data in the storage system also improves data reliability.
- Boosts processing performance by obviating need for data transfer to Hadoop processing servers with Fujitsu’s proprietary distributed file system, when processing data using Hadoop, processing can be performed by directly accessing data stored in the storage system. Unlike the standard Apache Hadoop format, which temporarily transfers data to be used to HDFS before processing, Fujitsu’s software obviates the need transfer data to substantially reduce processing time.
- Existing tools can be used without modification In addition to an HDFS-compatible interface, an interface with the data file system supports the standard Linux interface. This means that users can employ existing tools for back-up, printing and other purposes, without modification.
Fujitsu has joined the Hadoop party with the similar goal of other vendors in the market by plugging integration with their offering. In this particular case, the company opted not to go with higher level, ease of use features like visualizations and glitzy analytics. Instead the focus seems to start with infrastructure, adding redundancy and reducing processing overhead. Given the willingness to support Hadoop administrators with the install, Fujitsu may be indicating that deployment will still require some advanced knowledge.
Where does Fujitsu go from here? If they continue to commit towards integration with Hadoop, there may be a strategic partnership in their future with one or more Hadoop distributors.
Related Stories
Fujitsu Lets Big Data Cloud Flag Fly
Fujitsu Expands On-Demand Access to Analytical Simulations
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
Call & Contact Center Expo
 April 24 - April 25Las Vegas NV United States
April 24 - April 25Las Vegas NV United States -
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States