

January 20, 2012
RainStor Brings Database to Hadoop
This week big data management software company, RainStor, announced an enterprise database that can run natively on Hadoop. The company says that this will allow more flexibility for analytics operations on diverse data without the need to move data out of HDFS.
RainStor claims that their new database offering provides up to 40x compression, along with 10-100x faster analytics by providing both SQL access and MapReduce. Furthermore, they say that a compressed multi-structured data set running on HDFS delivers maximum efficiency and reduces the cluster size by 50 percent to 80 percent, which significantly lowers operating costs.
The company says that unlike traditional databases, RainStor has architectural compatibility (particularly in terms of the block file approach to storage) with Hadoop so users can run the two together. This is how they break down the database for Hadoop’s capabilities:
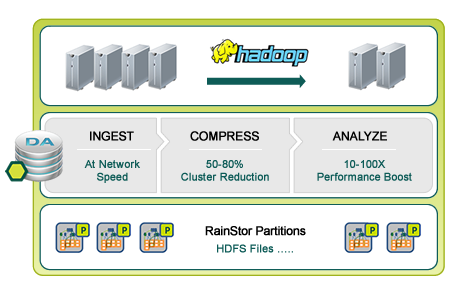 Ingest
Ingest
RainStor ingests raw, multi-structured network data handling 10’s of billions of daily records and as the data is ingested, it is automatically de-duplicated and compressed.
Compress
RainStor’s industry leading compression starts with value and pattern de-duplication resulting in zero redundancy of records. Further byte and algorithmic compression yields data reduction rates of 20-40:1.
Analysis
RainStor supports both SQL andMapReduce, via Pig. Users can choose SQL for rapid response ad-hoc queries or run batch jobs using MapReduce against RainStor data. Additionally you can interoperate SQL and MapReduce and join results from a query against RainStor and against native CSV files on HDFS.
Scale
Hadoop is gaining in popularity because it is easy to scale as data volumes grow. RainStor is designed to scale up and out and you simply add additional nodes when capacity requirements dictate.
Manage
Because RainStor runs natively on Hadoop, users get deployments off the ground faster with standard SQL supported. There are no specialist DBA skills required to maintain RainStor.
RainStor uniquely provides all the enterprise standards IT has come to expect when running analytics platforms. RainStor has built in geo-replication, security and automatic recovery of partitions. Additional support for workload segregation enables fast and resilient deployments.
In addition to their Hadoop database announcement, they also commented on new partnerships with others in the Hadoop ecosystem, including Cloudera, Hortonworks, and MapR as well as Composite Software.
As a side note, the graphic below highlights RainStor’s statement about how compression can improve the performance of analytics.

Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States