

August 2, 2013
Treasure Data Gains New Steam for Cloud-based Big Data
Start-up, Treasure Data says they’re taking the complexity out of collecting, storing, and analyzing big data with a full-service cloud offering that is gaining new steam.
 Launched in September 2012, Treasure Data offers a cloud-based system that addresses everything from data collection, storage, to the output analytics – all on a single packaged platform.
Launched in September 2012, Treasure Data offers a cloud-based system that addresses everything from data collection, storage, to the output analytics – all on a single packaged platform.
Last week, the company announced that they’ve raised $5 million in Series A financing led by Sierra Ventures. The funding, which CEO, Hiro Yoshikawa says will be used to fuel their global growth plan follows a year of already impressive growth – the company now claims over 80 customers since the platform launched.
“These companies are looking for solutions that change the economics of data warehousing,” Yosikawa told Datanami, adding that they’ve already got reach into the Fortune 100 with their offering.
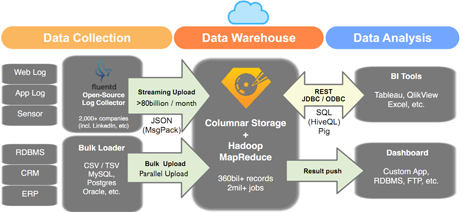
One of the primary challenges any cloud service has is getting the data reliably into the cloud. Treasure Data says that they solved this problem early on with tools that enable users to stream data directly in, or be transferred en masse from a relational database. These tools include their open sourced Fluentd and MessagePack, which can be used to move data into the Treasure Data schemaless platform.
In the data warehousing layer, the company has a storage system dubbed Plazma, built using Amazon’s S3, and Cloudera’s CDH4 Hadoop distro. “We take advantage of available open source technology,” Kiyoto Tamura, VP of Products told Datanami. “We understand that there are shortcomings with technology available in the open, and whenever we see an opportunity to do better, we write our own unique solution.”
In the case of their Hadoop-based platform, the company has opted to bypass HDFS for their own proprietary file system, dubbed Plazma, a distributed columnar storage system invented by by Treasure Data Chief Architect, Sada Furuhashi (who is also responsible for Fluentd and MessagePack).
“We noticed that the storage layer needs to be multi-tenant, elastic, and easy to manage while keeping the scalability and efficiency,” the company wrote in a recent article explaining the creation of Plazma. “By separating the MapReduce processing engine of Hadoop and the storage layer, we would be able to optimize the elasticity, efficiency, and reliability of the system.”
Ultimately, says Tamura, it adds up to Plazma providing better IO performance than “had we just gone with the raw vanilla.”
Once in the system, data can be queried using HiveQL or Pig, have MapReduce jobs run on it, or be utilized by analytic tools such as Tableau or JasperSoft (among others). Currently, Tamura says that there are over 700 billion records in the system, with over 200,000 queries a day running on the data.
Tamura says one of the world’s largest social gaming companies uses the Treasure Data platform to unify their data collection across geographies, and departments. With several studios collecting data on their various gaming titles, they lacked a central platform in which to compare apples with apples in performance. After starting on a single game basis, Tamura says the company now has more than a hundred gaming titles on the system and are able to give data access to everyone from C-level executives to business analysts and engineers.
While the service has a lot of competition from all directions, including both old and new school database technologies, Tamura says the company sees a lot of green pasture ahead of them.
“We bump the hardest against the home-grown, do-it-yourself solution,” he explains. “Hadoop is a hot commodity… and some companies can do it – but many companies tend to overestimate their abilities on building, and more importantly maintaining a Hadoop cluster.”
Related Items:
Facebook Molds HDFS to Achieve Storage Savings
Baldeschwieler: Looking at the Future of Hadoop
On Algorithm Wars and Predictive Apps
Applications:
Enterprise Analytics
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
Call & Contact Center Expo
 April 24 - April 25Las Vegas NV United States
April 24 - April 25Las Vegas NV United States -
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States