

February 4, 2013
A Holistic Approach to Big Data Analytics
The race to build an effective holistic big data analytics system is a lucrative one being run by several Hadoop-focused startup companies, including Karmasphere and Datameer.
 Manish Jiadani, Karmasphere’s Senior Director of Product Management, hosted a talk where he discussed Karmasphere’s new Hadoop-based data analytics offering, called Karmasphere 2.0.
Manish Jiadani, Karmasphere’s Senior Director of Product Management, hosted a talk where he discussed Karmasphere’s new Hadoop-based data analytics offering, called Karmasphere 2.0.
For Karmasphere, a company founded in 2005, there exist five pillars that hold up a worthwhile analytics system. Some of those pillars are fairly common across vendors, including the ability to garner ‘actionable insight’ along with hosting ‘unconstrained analytics.’
Their first factor, collaboration, is also fairly common, but it carries another level of significance for Karmasphere. They hope to ease the collaborative process by automatically presenting the data users wish to work with graphically when it comes out of Hive.
The Karmasphere system works in four steps. The first step, which they call ‘ingest,’ takes in data in “wizard-based data ingestion.” According to Jiadani, the data is immediately visualized in a tabular manner before reaching the user in the exploration step. Meanwhile, the metadata is poured into Hive tables.
The second step would allow end users to ‘explore’ the data through “visual, iterative data exploration with filtering and sorting wizards.” Again, effective initial visualization is the key here. Instead of tabulating the information through spreadsheets like Datameer, the interface represents the data graphically, with the emphasis being on fostering a collaborative environment.
The user would then analyze the data through iterative SQL analysis before connecting to a visualization tool like Tableau and Spotfire to represent results.
These features are represented in the figure below, which details the architecture underlying the Karmasphere platform.
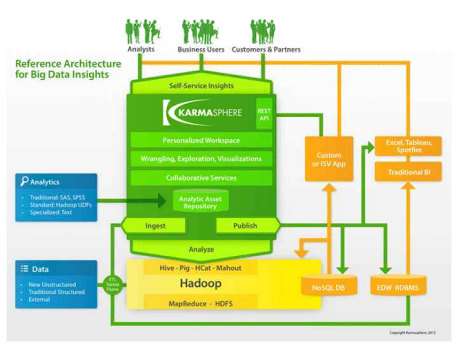
One of the challenges in building a comprehensive Hadoop-based analytics system is finding a way to let business and end users efficiently work with the data. As shown by the diagram, Karmasphere would run atop Hadoop, sending and receiving its data from Hive. Upon arrival, the system analyzes the data through several means, including through SAS and SPSS analytics as well as a custom text analytics application from their analytic asset repository.
From there, according to Jiadani, the data can be output to a NoSQL database, back into Hive, or into, as mentioned before, a visualization package.
It will be interesting to see how the platform stacks up with that of competitor Datameer, who also think of themselves as a do-it-all big data analytics company. Whether or not Hive, Hadoop’s data warehousing tool, can serve as the principal feeder and keeper of Karmasphere’s data as opposed to a more private option like EMC Greenplum or HP Vertica will be an essential factor in the success of the Karmasphere system.
Indeed, Karmasphere CEO Gail Ennis spoke last year on the limitations of Hive but noted that its effectiveness is rapidly growing. She argued back in June that “the constraints are going to be addressed very soon because Hive adoption and community development work is moving quickly.”
Ennis and her company will hope that Hive maintains its development pace and that their system will run smoothly from it.
Related Articles
New Ropes for Scaling the SQL Wall
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
Call & Contact Center Expo
 April 24 - April 25Las Vegas NV United States
April 24 - April 25Las Vegas NV United States -
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States