

December 14, 2015
The Algebra of Data Promises a Better Math for Analytics, And More

(Marina Sun/Shutterstock.com)
A company by the name of Algebraix Data is beginning to speak publicly for the first time about the algebra of data, an approach to storing and accessing data that it devised and patented. The company is using its data algebra now to provide big data analytics services to clients, but the uses could be much more far-reaching, including a universal language.
When E.F. Codd set out to change how we store and access data in the 1970s, he had initially envisioned applying strong mathematical principals based on set theory. Codd eventually failed with implementing that math, but he still succeeded in creating the relational database that would become the underpinning of business software for the next 35 years.
Fast forward to 2009. The relational database is straining under the weight of big, semi-structured and unstructured data, heralding the rise of new technologies like NoSQL databases, object-oriented file systems, and Hadoop. We see a flowering of new technologies under the “big data” banner, and relational databases and SQL are no longer kings of data access hill.
About the same time, the mathematician Gary Sherman starts pondering a more perfect way to represent data. Instead of storing data in rows and columns, or as nested JSON documents or edges within a graph or as values unlocked by keys, why couldn’t the data be represented more mathematically, as Codd had originally intended?
Sherman, a professor at Indiana’s Rose‐Hulman Institute of Technology, started with the 1968 paper, “Description of a Set-Theoretic Data Structure,” by D. L. Childs, which Codd had used as the basis for his work on relational theory. Sherman and analyst Robin Bloor describe the mathematical research in their 2015 book, “The Algebra of Data: A Foundation for the Data Economy.”
“Childs correctly identified set theory as the natural mathematical basis for representing data and proposed an extended set theory as a means to creating an algebra of data. As a consequence, it would be possible to query data using set operations such as union, intersection, Cartesian product and so on. If this were done, the use of sets and set operations would provide complete independence from physical data structures.”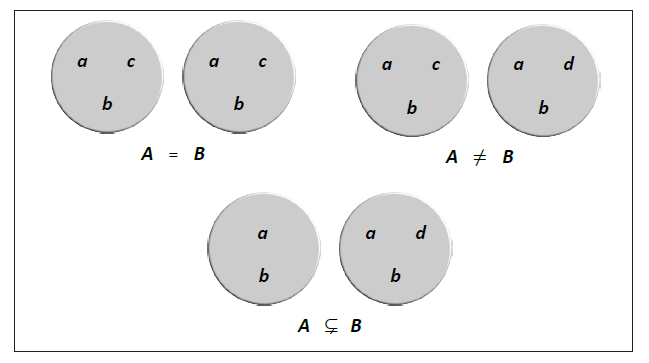
Sherman soon concluded that, while Childs was right in his aims, his extension was unnecessary, and so instead focused on Zermelo-Fraenkel set theory (ZFC). He eventually left the university and joined Algebraix, and started working full time to hammer out a working algebra of data based on ZFC that could represent any data, anywhere, in any way.
A Simpler Approach to Data
Algebraix attracted the interest of entrepreneur Charlie Silver, who had some familiarity with the difficulty of analyzing large sums of data. Silver was a co-founder of RealAge, a medical website started in the early 2000s. RealAge allowed people to enter health- and lifestyle-related information about themselves, and algorithms behind the scenes would calculate their “real” age and then give them advice on “how to live life to the youngest.”

Algebraix founding mathematician Gary J Sherman Ph.D. brings expertise in modern and linear algebras, probability theory, topology, and functional analysis
“It drove me crazy that we couldn’t do the analytics,” says Silver, who was involved in the sale of RealAge to Hearst in 2007 for an estimated $60 million to $70 million. “How many millions of dollars did I spend, how many people did I have to hire, how many cubes of this and that did I had to deploy to try to compare people with high cholesterol and eating habits and additional outcomes etc. It drove me crazy.”
Silver saw the value in what Sherman was pitching, and decided to invest in the company. Later, he took over as CEO. While he admits he’s no mathematician, Silver recognized that Sherman’s creation could have a dramatic impact on big data analytics. “All data can be represented in these algebraic sets,” Silver tells Datanami. “Once you do that–whether you use Hadoop or Oracle, it doesn’t really matter–it just becomes blazing fast. Blazing fast.”
You need a mathematics degree to really understand how the Algebraix Technology Platform actually works, but the effects are easier to explain. Silver does this using the Rolodex analogy. In a typical computer, whenever you do a search or a query, he says, “You turn the whole Rolodex every single time,” he says. “But when you do things algebraically, you actually compute in the cache, meaning every time something has been computed, it’s an immutable algebraic set that can be re-used.
“And that’s why it becomes lightning fast,” he continues, “because it doesn’t have to power through the 99.9 percent of the data that’s not relevant to the data, whereas in a traditional compute environment, you have to go through the whole data set every single time.”
Big Data Algebra
Algebraix is currently using its technology in big data analytics services engagements. “For $10,000 per month, we can do what the people who are charging millions can do,” Silver says. “Don’t spend $5 million with McKinsey or Bain or IBM or Oracle to do analytics on your data. We’re able to do it, better faster, cheaper.”
The company has a handful of clients, including the Khan Academy, a nonprofit educational organization, and a fast-food chain from Southern California. Deployments of the technology are done on Microsoft‘s Azure platform (the company considers Microsoft a close partner).
In early 2016, the company plans to begin shipping its first shrink-wrapped product—a SQL optimizer for Hadoop that will speed u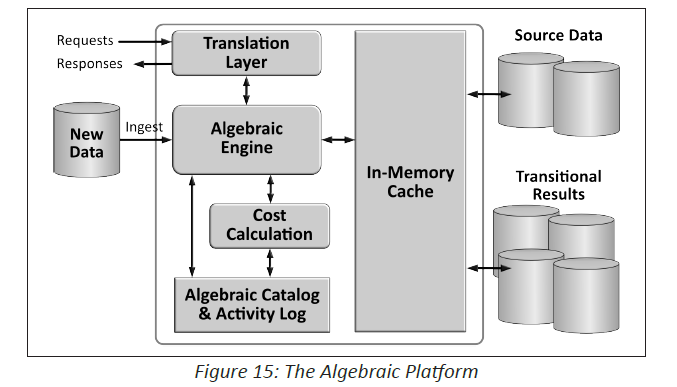 p SQL queries on Hadoop without requiring the data to be first converted into an algebraic form or exposing users to the Algebraix code. It’s also working on using its technology with document and graph databases (it created a sematic database called SPARQL) and is considering writing extensions to popular languages like Java, C++, PHP, and Ruby.
p SQL queries on Hadoop without requiring the data to be first converted into an algebraic form or exposing users to the Algebraix code. It’s also working on using its technology with document and graph databases (it created a sematic database called SPARQL) and is considering writing extensions to popular languages like Java, C++, PHP, and Ruby.
It’s hard to say where the algebra of data will go at this point. Algebraic kept a tight lid on it while it was being developed, and intends to have the first whack at productizing it. In the meantime, there should be no question as to whether the technology is production ready. The fact that Bloor, a respected IT industry analyst, has a taken an interest in Algebraix as its Technology Evangelist says quite a bit.
“Nobody is going to turn around and say the math is wrong. I can guarantee it,” says Bloor, a Ph.D. holder who has degrees in math and computer science. “Gary Sherman is the best mathematician I’ve ever encountered.”
But Why Now?
If using an algebraic approach on data is so approach—and one that Codd had initially hoped to take—then why did it take so long, and why did nobody else create it sooner? Bloor has some ideas.
“I was brought up in the relational era, and I knew it wasn’t mathematically perfect. They knew it wasn’t mathematically perfect,” Bloor says. “Say we’ve gone back to the beginning of computing. If you could start again, everything would be done this way, no doubt, because it’s a ![]() perfect representation. But it wasn’t done then. It’s only just appeared.”
perfect representation. But it wasn’t done then. It’s only just appeared.”
Bloor is convinced this technique will eventually make its way into high performance computing (HPC), and could even become the basis for a universal query language far in to the future. “It is revolutionary in the same way that relational was revolutionary,” Bloor says. But what exactly becomes the “killer” app for algebraic data has yet to be determined.
There are some drawbacks to this approach, including the need to convert older data to an algebraic form. “There is God knows how many exabytes of data out there that doesn’t conform to this yet,” Bloor says. “Some of it will be recognized algebraically by its very nature, but it’s really difficult to know how fast you could attack the whole of the data problem.”
As the concepts and benefits of algebraic data become more widely known, there’s a chance that it will catch on and become part of the tech landscape, just like the relational database did four decades ago. It took Sherman and his team four years of hard work to create this algebra of data. “When you think about that, four years is reasonably good,” Bloor says. “In retrospect, as people start using this and it becomes natural for people to use it, they’ll think it was easy to create.”
Related Items:
Can You Trust Your Algorithms?
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
Call & Contact Center Expo
 April 24 - April 25Las Vegas NV United States
April 24 - April 25Las Vegas NV United States -
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States